Modular Flows: Differential Molecular Generation
Generating new molecules is fundamental to advancing critical applications such as drug discovery and material synthesis. Flows can generate molecules effectively by inverting the encoding process, however, existing flow models either require artifactual dequantization or specific node/edge orderings, lack desiderata such as permutation invariance, or induce discrepancy between the encoding and the decoding steps that necessitates post hoc validity correction. We circumvent these issues with novel continuous normalizing E(3)-equivariant flows, based on a system of node ODEs coupled as a graph PDE, that repeatedly reconcile locally toward globally aligned densities. Our models can be cast as message-passing temporal networks, and result in superlative performance on the tasks of density estimation and molecular generation. In particular, our generated samples achieve state-of-the-art on both the standard QM9 and ZINC250K benchmarks.
💡 Research Summary
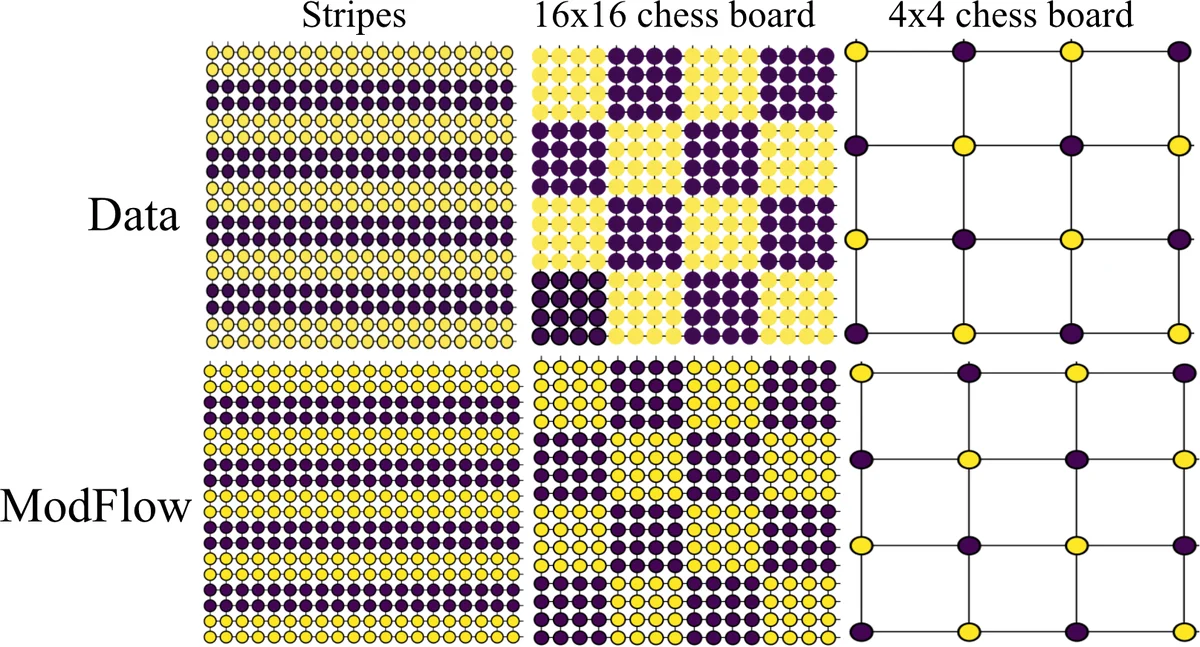
The paper introduces ModFlow, a novel generative model for molecular graphs that leverages continuous normalizing flows (CNFs) coupled across nodes via a graph‑based partial differential equation (PDE). Each atom is represented by a latent score vector z_i(t) that evolves from a standard Gaussian at time t = 0 according to an ODE \dot z_i(t)=f_θ(t, z_i(t), z_{N_i}(t), x_i, x_{N_i}), where N_i denotes neighboring nodes and x_i their geometric coordinates. The differential function f_θ is implemented with an E(3)‑equivariant graph neural network (EGNN), guaranteeing translation, rotation, reflection, and permutation invariance—critical properties for molecular data.
By treating the whole set of node ODEs as a coupled system, ModFlow can be viewed as a graph PDE: the dynamics of each node depend only on its local neighborhood, which yields a sparse Jacobian and sparse adjoint equations. Proposition 1 shows that the modular adjoint computation is sparser than a generic adjoint, leading to lower memory and computational cost during training with the adjoint sensitivity method.
Unlike prior flow‑based molecular generators, ModFlow does not require dequantization (adding noise to discrete graphs) or post‑hoc validity checks. Instead, the authors define a noisy one‑hot mapping from observed graphs to continuous latent scores, creating an “unconditional” data distribution \hat p_{data}. Training maximizes the log‑likelihood E_{\hat p_{data}}
Comments & Academic Discussion
Loading comments...
Leave a Comment