QubitHD: A Stochastic Acceleration Method for HD Computing-Based Machine Learning
Machine Learning algorithms based on Brain-inspired Hyperdimensional(HD) computing imitate cognition by exploiting statistical properties of high-dimensional vector spaces. It is a promising solution for achieving high energy efficiency in different machine learning tasks, such as classification, semi-supervised learning, and clustering. A weakness of existing HD computing-based ML algorithms is the fact that they have to be binarized to achieve very high energy efficiency. At the same time, binarized models reach lower classification accuracies. To solve the problem of the trade-off between energy efficiency and classification accuracy, we propose the QubitHD algorithm. It stochastically binarizes HD-based algorithms, while maintaining comparable classification accuracies to their non-binarized counterparts. The FPGA implementation of QubitHD provides a 65% improvement in terms of energy efficiency, and a 95% improvement in terms of training time, as compared to state-of-the-art HD-based ML algorithms. It also outperforms state-of-the-art low-cost classifiers (such as Binarized Neural Networks) in terms of speed and energy efficiency by an order of magnitude during training and inference.
💡 Research Summary
The paper introduces QubitHD, a novel stochastic acceleration method for hyperdimensional (HD) computing‑based machine learning that bridges the long‑standing trade‑off between energy efficiency and classification accuracy. Traditional HD‑based classifiers achieve high accuracy only with floating‑point or integer representations, while binarized versions suffer substantial accuracy loss. Existing work (QuantHD) improves binarized accuracy by retraining on a binarized model, yet it still leaves a sizable gap to the non‑binarized counterpart, converges slowly, and can become trapped in local minima. QubitHD draws inspiration from quantum‑bit measurement: it replaces the deterministic sign‑based binarization with a probabilistic function q_bin(x) that, for values within a cutoff b (a fraction of the data’s standard deviation), flips to +1 or –1 with probabilities proportional to (½ ± x⁄2b). This ensures that the expected value of the binary vector equals the original real‑valued vector, preserving the information content while still yielding a binary representation.
The algorithm proceeds in four stages: (1) encoding raw features into 10 000‑dimensional hypervectors using random base vectors; (2) initial one‑shot training by summing hypervectors per class; (3) stochastic binarization of the class hypervectors using q_bin; and (4) retraining where mis‑classified samples adjust the non‑binary model, with the binarized model guiding updates via a learning rate α. Because the binary model uses Hamming distance instead of cosine similarity, inference becomes a cheap bit‑wise operation.
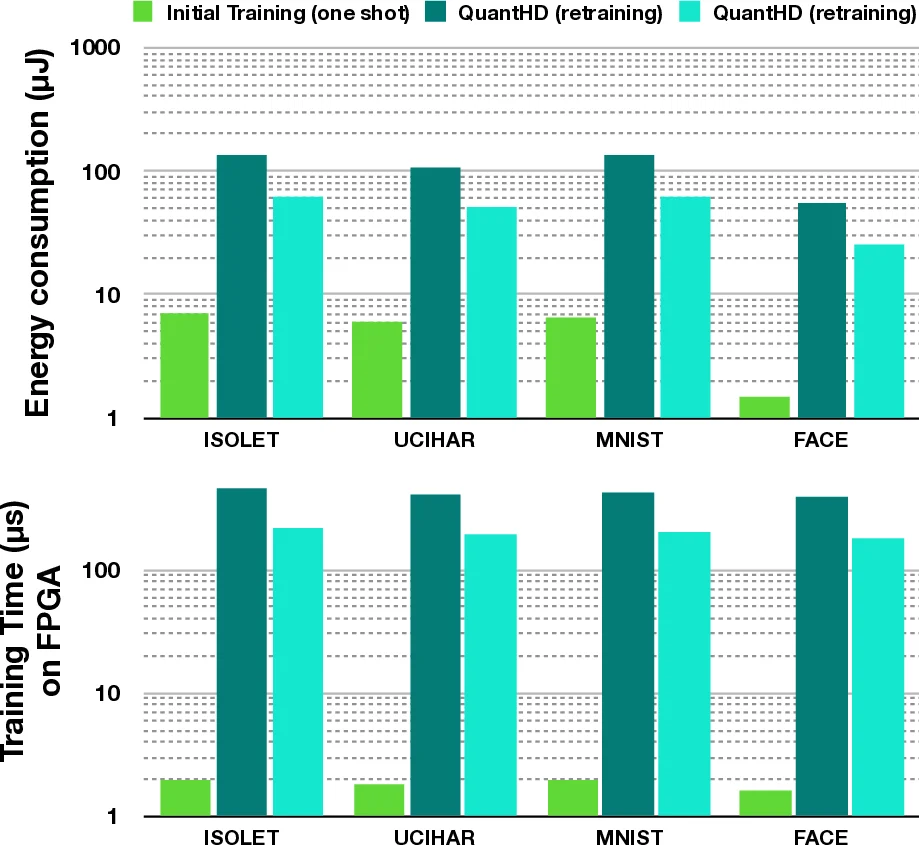
A hardware prototype on FPGA implements the entire pipeline with minimal extra resources; random flips are generated once per retraining round, and the binary arithmetic maps naturally to FPGA logic. Experimental evaluation on human‑activity, face, and text datasets shows that QubitHD reduces the accuracy gap between binarized and full‑precision HD models by an average of 38.8 %, cuts convergence iterations by 30‑50 % (overall training time reduced by 95 %), and achieves a 56× improvement in energy efficiency and an 8× speed‑up during training compared with state‑of‑the‑art HD methods. When benchmarked against Binarized Neural Networks (BNNs) and Multi‑Layer Perceptrons (MLPs), QubitHD delivers comparable or slightly higher accuracies while being 56× (training) and 52× (inference) faster.
In summary, QubitHD demonstrates that stochastic binarization can retain the expressive power of high‑dimensional representations while delivering orders‑of‑magnitude gains in speed and power consumption. This makes it a compelling candidate for ultra‑low‑power edge devices and IoT platforms where traditional deep learning is infeasible.
Comments & Academic Discussion
Loading comments...
Leave a Comment