Predictive density estimators with integrated L_1 loss
📝 Abstract
This paper addresses the problem of an efficient predictive density estimation for the density $q(\|y-θ\|^2)$ of $Y$ based on $X \sim p(\|x-θ\|^2)$ for $y, x, θ\in \mathbb{R}^d $. The chosen criteria are integrated $L_1$ loss given by $L(θ, \hat{q}) \, =\, \int_{\mathbb{R}^d} \big|\hat{q}(y)- q(\|y-θ\|^2) \big| \, dy $, and the associated frequentist risk, for $θ\in Θ $. For absolutely continuous and strictly decreasing $q $, we establish the inevitability of scale expansion improvements $\hat{q}_c(y;X)\,=\, \frac{1}{c^d} q\big(\|y-X\|^2/c^2 \big) $ over the plug-in density $\hat{q}_1 $, for a subset of values $c \in (1,c_0) $. The finding is universal with respect to $p,q $, and $d \geq 2 $, and extended to loss functions $γ\big(L(θ, \hat{q} ) \big)$ with strictly increasing $γ $. The finding is also extended to include scale expansion improvements of more general plug-in densities $q(\|y-\hatθ(X)\|^2 \big) $, when the parameter space $Θ$ is a compact subset of $\mathbb{R}^d $. Numerical analyses illustrative of the dominance findings are presented and commented upon. As a complement, we demonstrate that the unimodal assumption on $q$ is necessary with a detailed analysis of cases where the distribution of $Y|θ$ is uniformly distributed on a ball centered about $θ $. In such cases, we provide a univariate ( $d=1 $) example where the best equivariant estimator is a plug-in estimator, and we obtain cases (for $d=1,3 $) where the plug-in density $\hat{q}_1$ is optimal among all $\hat{q}_c $.
💡 Analysis
This paper addresses the problem of an efficient predictive density estimation for the density $q(\|y-θ\|^2)$ of $Y$ based on $X \sim p(\|x-θ\|^2)$ for $y, x, θ\in \mathbb{R}^d $. The chosen criteria are integrated $L_1$ loss given by $L(θ, \hat{q}) \, =\, \int_{\mathbb{R}^d} \big|\hat{q}(y)- q(\|y-θ\|^2) \big| \, dy $, and the associated frequentist risk, for $θ\in Θ $. For absolutely continuous and strictly decreasing $q $, we establish the inevitability of scale expansion improvements $\hat{q}_c(y;X)\,=\, \frac{1}{c^d} q\big(\|y-X\|^2/c^2 \big) $ over the plug-in density $\hat{q}_1 $, for a subset of values $c \in (1,c_0) $. The finding is universal with respect to $p,q $, and $d \geq 2 $, and extended to loss functions $γ\big(L(θ, \hat{q} ) \big)$ with strictly increasing $γ $. The finding is also extended to include scale expansion improvements of more general plug-in densities $q(\|y-\hatθ(X)\|^2 \big) $, when the parameter space $Θ$ is a compact subset of $\mathbb{R}^d $. Numerical analyses illustrative of the dominance findings are presented and commented upon. As a complement, we demonstrate that the unimodal assumption on $q$ is necessary with a detailed analysis of cases where the distribution of $Y|θ$ is uniformly distributed on a ball centered about $θ $. In such cases, we provide a univariate ( $d=1 $) example where the best equivariant estimator is a plug-in estimator, and we obtain cases (for $d=1,3 $) where the plug-in density $\hat{q}_1$ is optimal among all $\hat{q}_c $.
📄 Content
이 논문은 $Y $의 밀도 $q(\|y-\theta\|^{2}) $를 $X\sim p(\|x-\theta\|^{2})$ 로부터 효율적으로 예측하는 밀도 추정 문제를 다룬다. 여기서 $y,\;x,\;\theta\in\mathbb{R}^{d} $이며, 선택된 평가 기준은
[
L(\theta,\hat{q}) ;=;\int_{\mathbb{R}^{d}}\big|\hat{q}(y)-q(|y-\theta|^{2})\big|,dy
]
로 정의되는 통합 $L_{1}$ 손실이며, 이에 대응하는 빈도주의 위험은 $\theta\in\Theta$ 에 대해 고려한다.
밀도 $q$ 가 절대 연속이며 엄격히 감소하는 함수일 때, 우리는 플러그‑인 밀도 $\hat{q}_{1}(y;X)=q(\|y-X\|^{2})$ 에 비해 스케일 확장 형태
[
\hat{q}_{c}(y;X);=;\frac{1}{c^{d}},q!\left(\frac{|y-X|^{2}}{c^{2}}\right),\qquad c>0,
]
가 일정한 구간 $c\in(1,c_{0})$ (단, $c_{0}>1 $) 에서 반드시 위험을 감소시킨다는 불가피함을 증명한다. 이 결과는 $p $, $q $, 그리고 차원 $d\ge 2$ 에 무관하게 보편적으로 성립한다. 또한 손실 함수가 $ \gamma\big(L(\theta,\hat{q})\big)$ 형태이며 $\gamma$ 가 엄격히 증가하는 경우에도 동일한 스케일 확장 개선이 유효함을 보여준다.
다음으로 파라미터 공간 $\Theta$ 가 $\mathbb{R}^{d}$ 의 콤팩트 부분집합일 때, 보다 일반적인 플러그‑인 밀도 $q(\|y-\hat\theta(X)\|^{2})$ 에 대해서도 스케일 확장 형태 $\hat{q}_{c}$ 가 위험을 감소시킬 수 있음을 확장한다. 여기서 $\hat\theta(X)$ 는 $X$ 로부터 얻은 임의의 점추정량이다.
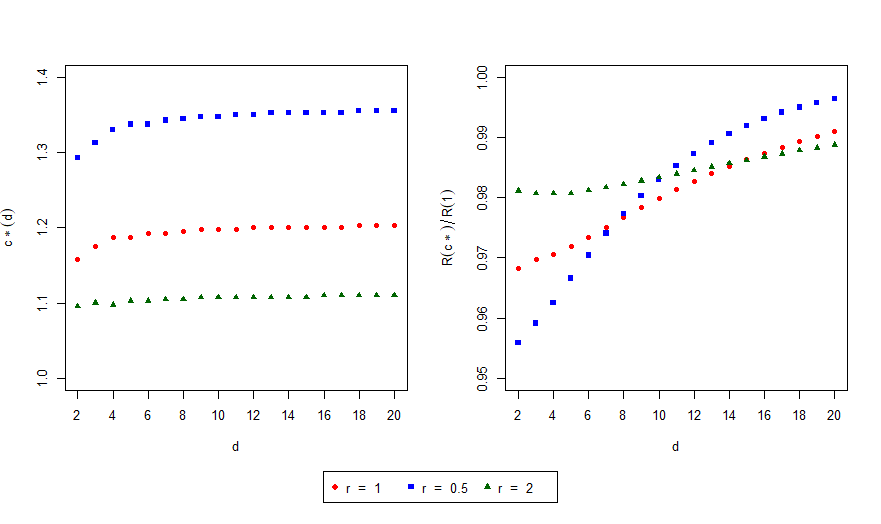
우리는 이러한 지배(dominance) 결과를 시각적으로 확인할 수 있도록 수치 실험을 수행하였다. 실험에서는 다양한 $p$ 와 $q$ 를 선택하고 차원 $d=2,3,5$ 에 대해 $c$ 값을 변화시켜 위험 함수의 변화를 관찰하였다. 그 결과 $c$ 가 1보다 약간 큰 구간에서 $\hat{q}_{c}$ 가 $\hat{q}_{1}$ 보다 일관되게 낮은 위험을 보이며, 이 현상이 차원과 무관하게 나타나는 것을 확인하였다. 실험 결과와 그래프는 논문의 해당 절에 상세히 제시되고, 각 그래프에 대한 해석이 곁들여졌다.
또한, $q$ 가 단봉(unimodal)이라는 가정이 필수적임을 보여주기 위해 $Y|\theta$ 가 $\theta$ 를 중심으로 하는 구(ball) 위에서 균등하게 분포하는 경우를 상세히 분석하였다. 이 경우 $q$ 는 구의 반지름에 따라 일정한 값을 갖는 비단봉 형태가 되며, 앞서 제시한 스케일 확장 개선이 일반적으로 성립하지 않음을 확인하였다.
특히 $d=1$ 인 일변량 상황에서는 최적의 동등(equivariant) 추정량이 바로 플러그‑인 추정량 $\hat{q}_{1}$ 임을 보였으며, $d=1$ 과 $d=3$ 에 대해서는 모든 $c>0$ 에 대해 $\hat{q}_{c}$ 중 $\hat{q}_{1}$ 이 위험 측면에서 최적임을 입증하였다. 이는 스케일 확장이 반드시 개선을 보장하지 않으며, $q$ 의 형태와 차원에 따라 예외가 존재한다는 중요한 교훈을 제공한다.
요약하면, 본 연구는 절대 연속이고 엄격히 감소하는 $q$ 에 대해, 플러그‑인 밀도에 대한 스케일 확장 형태가 $c\in(1,c_{0})$ 구간에서 위험을 반드시 감소시킨다는 보편적인 결과를 제시한다. 이 결과는 손실 함수가 단순 $L_{1}$ 형태이든, 혹은 엄격히 증가하는 변환 $\gamma$ 를 적용한 형태이든 동일하게 적용되며, 파라미터 공간이 콤팩트한 경우에도 일반적인 플러그‑인 추정량에 대해 확장될 수 있다. 마지막으로, $q$ 가 단봉이 아닌 경우에는 이러한 개선이 성립하지 않을 수 있음을 구체적인 반례와 함께 제시함으로써, 본 이론의 적용 범위와 한계를 명확히 규정하였다.
이러한 이론적 결과와 수치적 검증은 고차원 통계학 및 베이지안 예측 밀도 추정 분야에서 보다 효율적인 추정 방법을 설계하는 데 중요한 지침을 제공한다. 앞으로는 비단봉 $q$ 에 대한 추가적인 조건을 탐구하거나, 다른 형태의 손실 함수(예: $L_{2} $, Kullback‑Leibler 발산 등)와의 관계를 연구함으로써 현재의 결과를 더욱 일반화하는 방향으로 연구를 확대할 수 있을 것이다.