Approximate Computing and the Efficient Machine Learning Expedition
Approximate computing (AxC) has been long accepted as a design alternative for efficient system implementation at the cost of relaxed accuracy requirements. Despite the AxC research activities in various application domains, AxC thrived the past decade when it was applied in Machine Learning (ML). The by definition approximate notion of ML models but also the increased computational overheads associated with ML applications–that were effectively mitigated by corresponding approximations–led to a perfect matching and a fruitful synergy. AxC for AI/ML has transcended beyond academic prototypes. In this work, we enlighten the synergistic nature of AxC and ML and elucidate the impact of AxC in designing efficient ML systems. To that end, we present an overview and taxonomy of AxC for ML and use two descriptive application scenarios to demonstrate how AxC boosts the efficiency of ML systems.
💡 Research Summary
The paper provides a comprehensive survey and taxonomy of Approximate Computing (AxC) techniques as they apply to Machine Learning (ML), and demonstrates their impact through two concrete case studies. It begins by motivating AxC in the post‑Dennard‑scaling era, where “dark silicon” forces designers to seek energy‑efficient alternatives. ML is identified as a natural fit for AxC because neural networks are fundamentally function‑approximation systems and their training process can compensate for approximation errors.
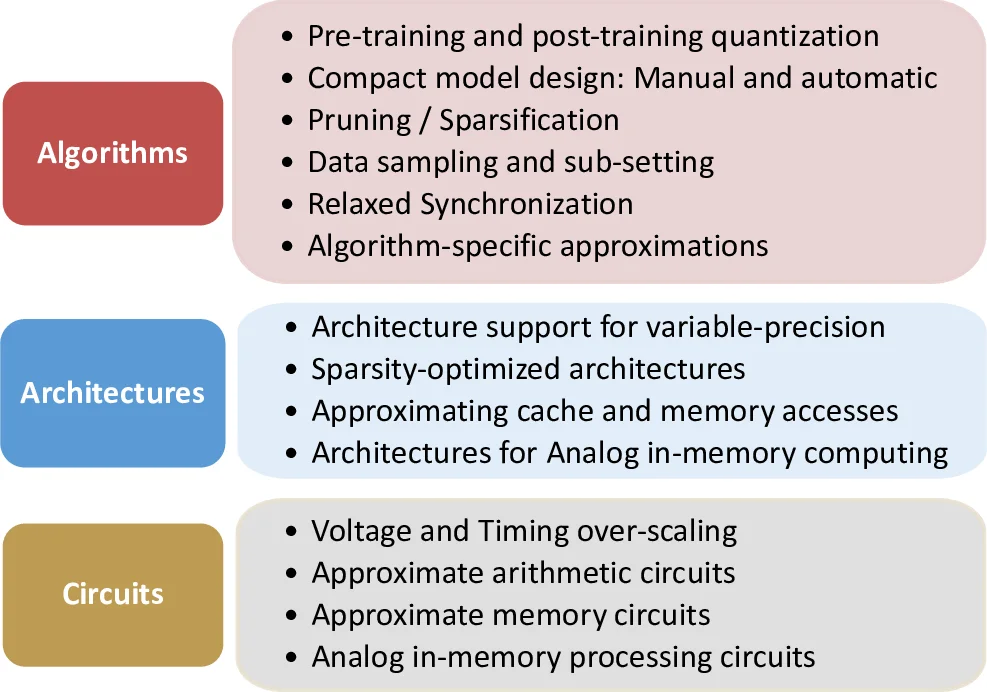
Section 2 presents a three‑level taxonomy—algorithmic, architectural, and circuit‑level approximations.
Algorithmic approximations include quantization/precision scaling (from FP16 down to INT2, with hybrid FP8 formats and both post‑training quantization and quantization‑aware training), compact model design (inverted bottleneck, depth‑wise convolutions, NAS, knowledge distillation), pruning and sparsification (structured block sparsity, compression of gradients for distributed training), data sampling/sub‑setting, and relaxed synchronization for distributed training. The authors discuss trade‑offs such as accuracy loss versus memory/compute reduction, and note that quantization is typically applied to CONV/GEMM while other ops remain in higher precision.
Architectural approximations focus on hardware that can exploit the algorithmic errors. Variable‑precision support (e.g., the RaPiD accelerator that spans 16‑bit floating‑point to 2‑bit fixed‑point), sparsity‑optimized engines (structured and unstructured, with dynamic skip logic), and memory‑system approximations (DRAM refresh reduction, speculative loads, data reuse) are described. The interplay between sparsity and quantization is highlighted as an open challenge, especially as aggressive quantization favors dense compute arrays.
Circuit‑level approximations cover logic approximation (modifying truth tables for lower power), timing over‑scaling (operating beyond nominal voltage/frequency to save energy at the cost of occasional timing errors), and approximate memory cells whose accuracy can be tuned at runtime. These low‑level techniques are positioned as the foundation that enables higher‑level AxC strategies.
Two case studies illustrate the end‑to‑end impact. The first is an analog in‑memory computing (IMC) accelerator for Transformer models. By embedding MAC operations directly in SRAM or ReRAM arrays, data movement is eliminated, and the design achieves 8‑bit to 4‑bit precision scaling with less than 0.3 % BLEU degradation, demonstrating that large language models can be deployed on edge devices with dramatically reduced energy.
The second case study targets ultra‑low‑power printed electronics. Using low‑voltage transistors and approximate arithmetic cells, a battery‑powered classifier is built that consumes under 10 mW while maintaining ~92 % accuracy after 95 % model compression via quantization, pruning, and data sampling. This showcases how AxC enables ML in domains where silicon‑based solutions are infeasible, such as disposable sensors or wearables.
The paper concludes by noting that commercial CPUs, GPUs, and AI accelerators already embed AxC features (e.g., mixed‑precision units, sparsity support) and outlines future research directions: joint optimization of precision, sparsity, and power; dynamic run‑time control of approximation levels; and addressing security, reliability, and verification concerns. Overall, the work argues that the synergy between AxC and ML, when pursued through systematic co‑design across the entire compute stack, can unlock unprecedented energy‑performance gains and broaden the applicability of machine‑learning systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment