Multiple testing with persistent homology
In this paper we propose a computationally efficient multiple hypothesis testing procedure for persistent homology. The computational efficiency of our procedure is based on the observation that one can empirically simulate a null distribution that is universal across many hypothesis testing applications involving persistence homology. Our observation suggests that one can simulate the null distribution efficiently based on a small number of summaries of the collected data and use this null in the same way that p-value tables were used in classical statistics. To illustrate the efficiency and utility of the null distribution we provide procedures for rejecting acyclicity with both control of the Family-Wise Error Rate (FWER) and the False Discovery Rate (FDR). We will argue that the empirical null we propose is very general conditional on a few summaries of the data based on simulations and limit theorems for persistent homology for point processes.
💡 Research Summary
The paper introduces a computationally efficient framework for multiple hypothesis testing (MHT) based on persistent homology, addressing the long‑standing challenge of lacking a tractable null distribution for topological summaries. Traditional approaches in topological data analysis (TDA) have relied on bootstrapping or permutation methods, which become prohibitively expensive when the number of tests grows large. The authors propose a universal empirical null distribution that can be pre‑computed and reused across many testing scenarios.
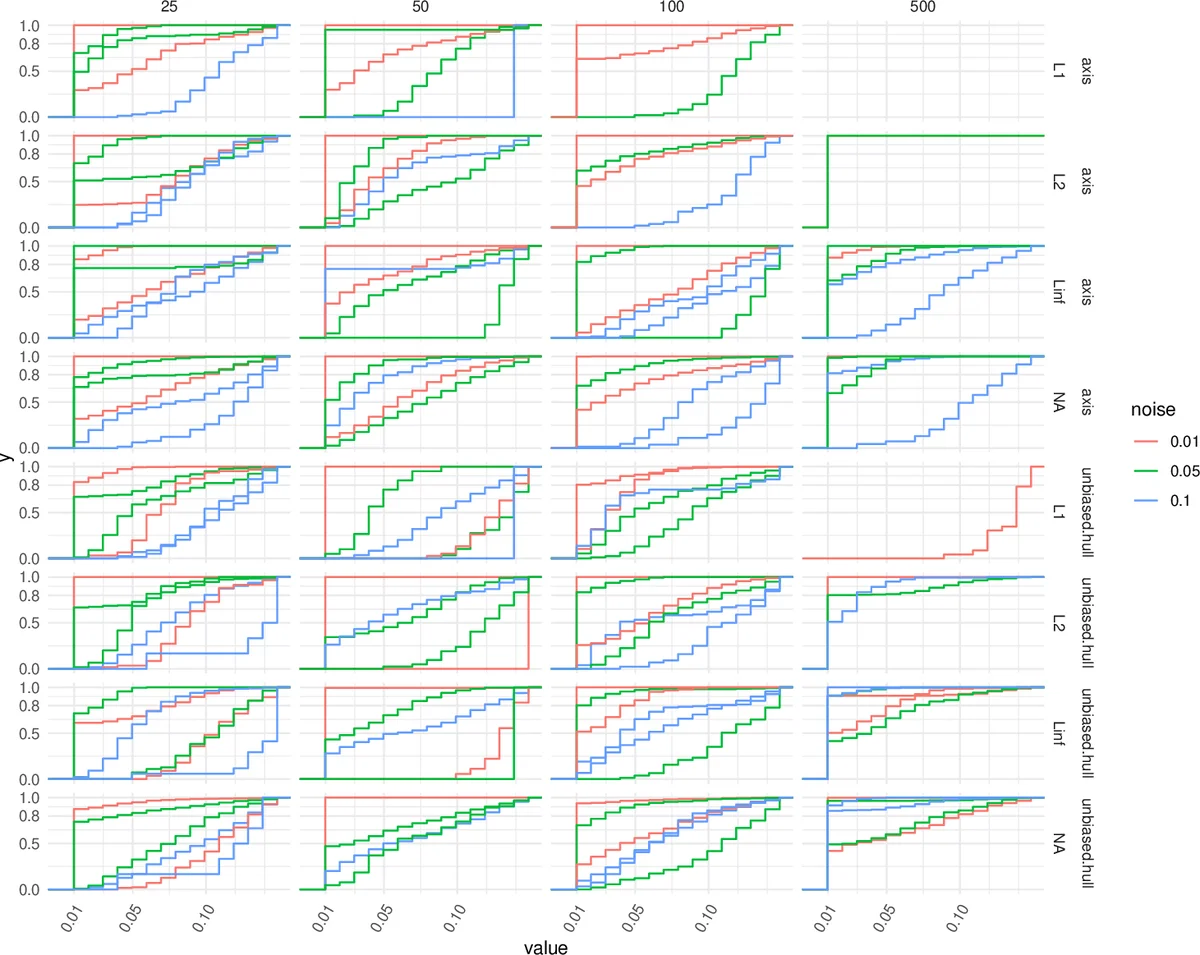
The core idea is to model the null hypothesis as a set of points drawn uniformly from a convex body that approximates the support of the observed data. Two strategies for defining this convex body are presented: (1) compute the exact convex hull of the data and sample uniformly within it, applying an unbiased volume‑adjustment to correct for boundary bias; (2) use a simple axis‑aligned bounding box, which is computationally cheaper but slightly less precise. For each simulated point cloud, a persistence diagram is constructed and a suite of statistics—such as maximal lifetime, lifetime ratios, and logarithmic transforms—are extracted. Repeating this process yields an empirical distribution for each statistic under the null.
Because different tests may involve point clouds of varying scales or dimensions, the authors introduce a standardization step. Each test statistic is centered and scaled using its empirical mean and standard deviation (z‑score transformation). This normalization aligns the null distributions across tests, making them comparable. The approach is theoretically justified by a central limit theorem for persistent Betti numbers in stationary point processes, which predicts asymptotic normality after appropriate scaling.
With standardized statistics and a pre‑computed null, p‑values are obtained by counting simulated statistics more extreme than the observed one (with a +1 correction to avoid zero p‑values). Standard multiple‑testing corrections—Bonferroni for family‑wise error rate (FWER) control and Benjamini–Hochberg for false discovery rate (FDR) control—are then applied directly to these p‑values.
The authors validate the methodology through extensive simulations covering dimensions d = 2, 3, 4 and sample sizes n = 100–1000. Both one‑sample tests (testing for acyclicity) and two‑sample tests (comparing two point clouds) are examined. Results demonstrate that the empirical null remains stable across dimensions and sample sizes, and that the proposed procedures achieve the desired error‑rate control while retaining high statistical power. The convex‑hull based null yields slightly more accurate p‑values than the bounding‑box approach, but the computational overhead is modest, allowing practitioners to choose based on available resources.
In summary, the paper provides a practical, theoretically grounded solution for large‑scale hypothesis testing with persistent homology. By decoupling the costly simulation of null distributions from the data analysis stage and by standardizing statistics across tests, it enables efficient FWER and FDR control in settings where thousands of topological features are examined simultaneously. This contribution significantly lowers the barrier to applying rigorous statistical inference in topological data analysis.
Comments & Academic Discussion
Loading comments...
Leave a Comment