Fast non-convex low-rank matrix decomposition for separation of potential field data using minimal memory
A fast non-convex low-rank matrix decomposition method for potential field data separation is proposed. The singular value decomposition of the large size trajectory matrix, which is also a block Hankel matrix, is obtained using a fast randomized singular value decomposition algorithm in which fast block Hankel matrix-vector multiplications are implemented with minimal memory storage. This fast block Hankel matrix randomized singular value decomposition algorithm is integrated into the \texttt{Altproj} algorithm, which is a standard non-convex method for solving the robust principal component analysis optimization problem. The improved algorithm avoids the construction of the trajectory matrix. Hence, gravity and magnetic data matrices of large size can be computed. Moreover, it is more efficient than the traditional low-rank matrix decomposition method, which is based on the use of an inexact augmented Lagrange multiplier algorithm. The presented algorithm is also robust and, hence, algorithm-dependent parameters are easily determined. The improved and traditional algorithms are contrasted for the separation of synthetic gravity and magnetic data matrices of different sizes. The presented results demonstrate that the improved algorithm is not only computationally more efficient but it is also more accurate. Moreover, it is possible to solve far larger problems. As an example, for the adopted computational environment, matrices of sizes larger than $205 \times 205$ generate “out of memory” exceptions with the traditional method, but a matrix of size $2001\times 2001$ can be calculated in $1062.29$s with the new algorithm. Finally, the improved method is applied to separate real gravity and magnetic data in the Tongling area, Anhui province, China. Areas which may exhibit mineralizations are inferred based on the separated anomalies.
💡 Research Summary
The paper addresses the problem of separating regional (large‑scale, smooth) and residual (small‑scale, localized) components from large gravity and magnetic data sets, a crucial step for reliable geological interpretation. Classical spatial‑domain methods (moving average, polynomial fitting) and frequency‑ or wavelet‑domain techniques suffer from spectral overlap and parameter‑tuning difficulties, while recent low‑rank matrix decomposition approaches based on robust principal component analysis (RPCA) have shown superior robustness and accuracy. However, existing RPCA‑based methods for potential‑field separation (e.g., LRMD‑PFS) require explicit construction of a block‑Hankel trajectory matrix whose size grows quadratically with the original data dimensions, leading to prohibitive memory consumption and computational cost.
To overcome these limitations, the authors propose a fast non‑convex low‑rank matrix decomposition framework (FNCLRMD‑PFS) that avoids constructing the trajectory matrix altogether. The core contributions are threefold:
-
Fast Block‑Hankel Matrix‑Vector Multiplication (FBHMVM) – By exploiting the circulant embedding of block‑Hankel matrices and using FFT‑based convolution, the product y = T b (where T = H(X) is the trajectory matrix and b is any vector) can be computed directly from the original data matrix X with O(PQ log (PQ)) operations and a storage requirement of only 3PQ + K̂ + L̂ entries, where P × Q is the size of X and K̂, L̂ are the block dimensions.
-
Fast Block‑Hankel Matrix‑Matrix Multiplication (FBHMMM) – Extending FBHMVM column‑wise yields an efficient routine for Y = T C, which is essential for algorithms that need multiple matrix‑matrix products (e.g., the Altproj RPCA iterations).
-
Fast Block‑Hankel Randomized SVD (FBHMRSVD) – The authors embed the above multiplication kernels into a randomized SVD scheme. A Gaussian test matrix Ω is multiplied with T via FBHMMM, followed by QR factorization and optional power iterations (parameter q). The resulting orthonormal basis Q approximates the column space of T, and a small eigen‑decomposition of BᵀB (where B = T Q) yields the low‑rank factors U_r, Σ_r, V_r. The algorithm’s cost is O((r + p) PQ log (PQ)) and its memory footprint remains O(PQ), a dramatic reduction compared with the O((L̂K̂)³) cost of a full SVD on the trajectory matrix.
These fast kernels are integrated into the Altproj non‑convex RPCA algorithm, which alternately updates a low‑rank approximation and a sparse matrix. By replacing the exact SVD step with FBHMRSVD, the new method (FNCLRMD‑PFS) can handle matrices far larger than previously possible.
Experimental Evaluation
Synthetic experiments on square gravity/magnetic matrices ranging from 50 × 50 to 2001 × 2001 demonstrate that FNCLRMD‑PFS consistently outperforms the traditional LRMD‑PFS (based on inexact augmented Lagrange multiplier, IALM). Metrics include root‑mean‑square error (RMSE), structural similarity index (SSIM), and wall‑clock time. For a 2001 × 2001 matrix, the proposed method completes in 1062 seconds, whereas the traditional approach fails due to “out‑of‑memory” errors already at 205 × 205. Parameter studies show that an oversampling p equal to the target rank r and a single power iteration (q = 1) provide a good trade‑off between accuracy and runtime.
Real‑Data Application
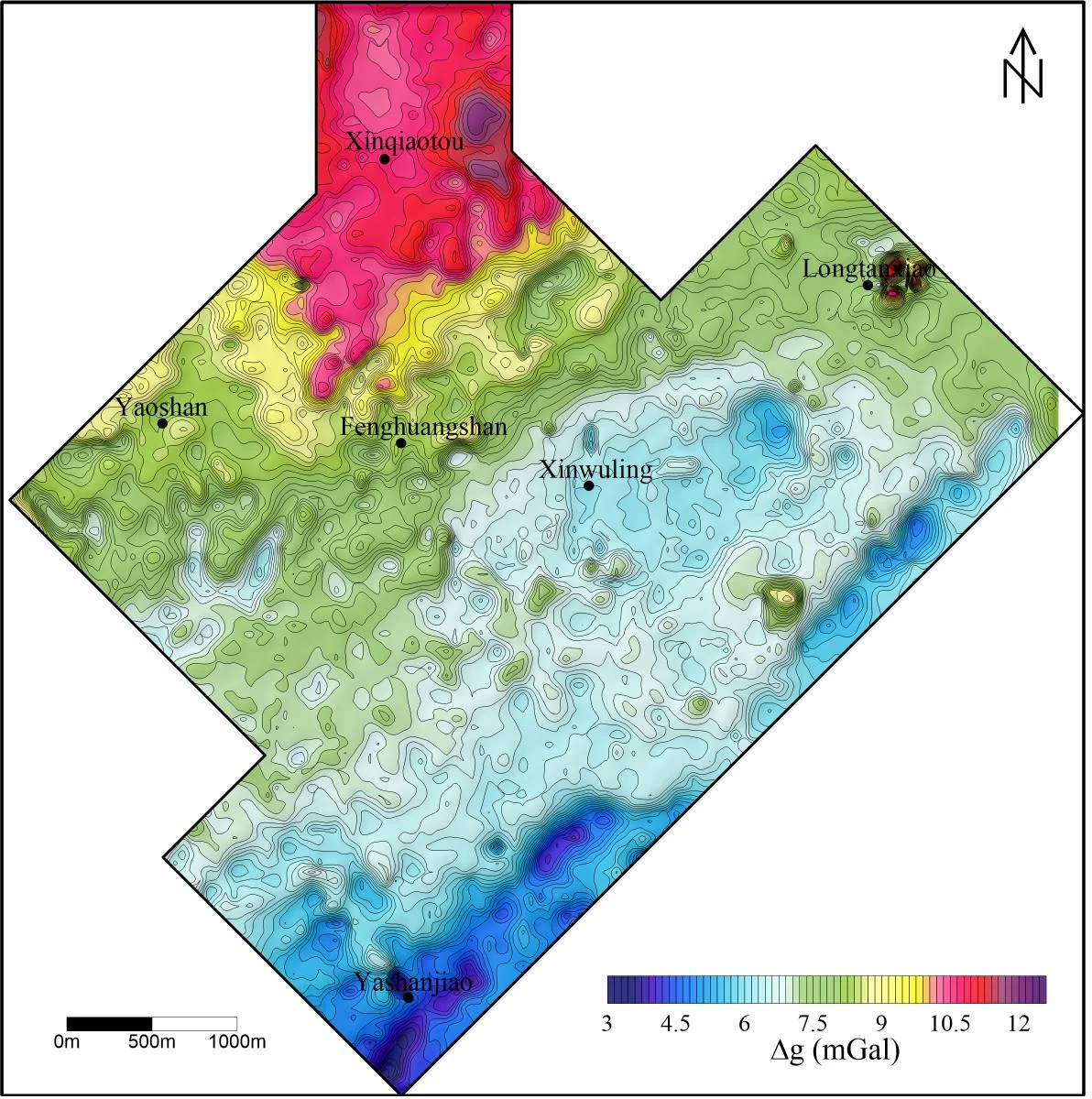
The algorithm is applied to real gravity and magnetic surveys over the Tongling area, Anhui Province, China. After separation, the regional component highlights broad anomalies that may correspond to deep mineralized bodies, while the residual component accentuates localized high‑frequency features indicative of shallow structures. Compared with conventional moving‑average or wavelet methods, the FNCLRMD‑PFS results exhibit clearer boundaries and reduced noise, facilitating more reliable mineralization targeting.
Conclusions and Future Work
The paper delivers a practical solution for large‑scale potential‑field data separation by (i) exploiting block‑Hankel structure for memory‑efficient matrix‑vector products, (ii) leveraging randomized SVD with modest power iterations for accurate low‑rank approximation, and (iii) embedding these into a non‑convex RPCA scheme. The method scales linearly in memory with data size, retains high accuracy, and is robust to parameter choices. Future directions include multi‑scale windowing for adaptive rank selection, extension to irregular (non‑grid) measurement layouts, GPU acceleration for near‑real‑time processing, and application to other geophysical modalities such as electromagnetic or seismic data.
Comments & Academic Discussion
Loading comments...
Leave a Comment