Lifelong Neural Predictive Coding: Learning Cumulatively Online without Forgetting
In lifelong learning systems based on artificial neural networks, one of the biggest obstacles is the inability to retain old knowledge as new information is encountered. This phenomenon is known as catastrophic forgetting. In this paper, we propose a new kind of connectionist architecture, the Sequential Neural Coding Network, that is robust to forgetting when learning from streams of data points and, unlike networks of today, does not learn via the popular back-propagation of errors. Grounded in the neurocognitive theory of predictive processing, our model adapts synapses in a biologically-plausible fashion while another neural system learns to direct and control this cortex-like structure, mimicking some of the task-executive control functionality of the basal ganglia. In our experiments, we demonstrate that our self-organizing system experiences significantly less forgetting compared to standard neural models, outperforming a swath of previously proposed methods, including rehearsal/data buffer-based methods, on both standard (SplitMNIST, Split Fashion MNIST, etc.) and custom benchmarks even though it is trained in a stream-like fashion. Our work offers evidence that emulating mechanisms in real neuronal systems, e.g., local learning, lateral competition, can yield new directions and possibilities for tackling the grand challenge of lifelong machine learning.
💡 Research Summary
The paper introduces the Sequential Neural Coding Network (S‑NCN), a novel connectionist architecture designed to learn continuously from a stream of data without suffering catastrophic forgetting, and without relying on back‑propagation. Inspired by the neurocognitive theory of predictive processing, S‑NCN treats each layer as a pair of a predictor and an error unit. During inference, a predictor at layer ℓ generates a hypothesis about the state of the layer below (ℓ‑1). The discrepancy between the hypothesis and the actual (clamped) state produces an error vector e₍ℓ‑1₎, which is fed back through learned feedback weights E₍ℓ₎ to compute a correction term d₍ℓ₎ = –e₍ℓ₎ + E₍ℓ₎·e₍ℓ‑1₎. The internal state z₍ℓ₎ is then updated as z₍ℓ₎ ← f₍ℓ₎(z₍ℓ₎ + β·d₍ℓ₎, g₍ℓ₎ᵗ), where f₍ℓ₎ implements a K‑winner‑take‑all (K‑WTA) competition driven by a task‑specific context vector g₍ℓ₎ᵗ. This competition yields sparse, task‑dependent representations, mirroring lateral inhibition observed in cortical circuits and reducing representational overlap between tasks.
After K iterative prediction‑correction cycles, the network updates its forward (W₍ℓ₎) and feedback (E₍ℓ₎) synapses using Hebbian‑like rules: ΔW₍ℓ₎ = e₍ℓ₎·φ₍ℓ₎(z₍ℓ₊1₎)ᵀ·S₍ℓ₎ and ΔE₍ℓ₎ = γ·d₍ℓ₎·e₍ℓ₎ᵀ·S₍ℓ₎, where S₍ℓ₎ denotes a normalisation operator and γ controls the slower learning rate of feedback weights. All updates are local, requiring only information available at each synapse, thus eliminating the need for global error back‑propagation.
A second component, the “task selector,” functions analogously to the basal ganglia. It receives the current task descriptor t (a one‑hot vector) and, via a lightweight meta‑network, retrieves or generates the appropriate context vectors g₍ℓ₎ᵗ from a memory matrix M₍ℓ₎. When a new task arrives, the memory expands by adding a new row, and output units are dynamically added if the new task has more classes than previous tasks. This design enables class‑incremental learning without explicit task identifiers at test time.
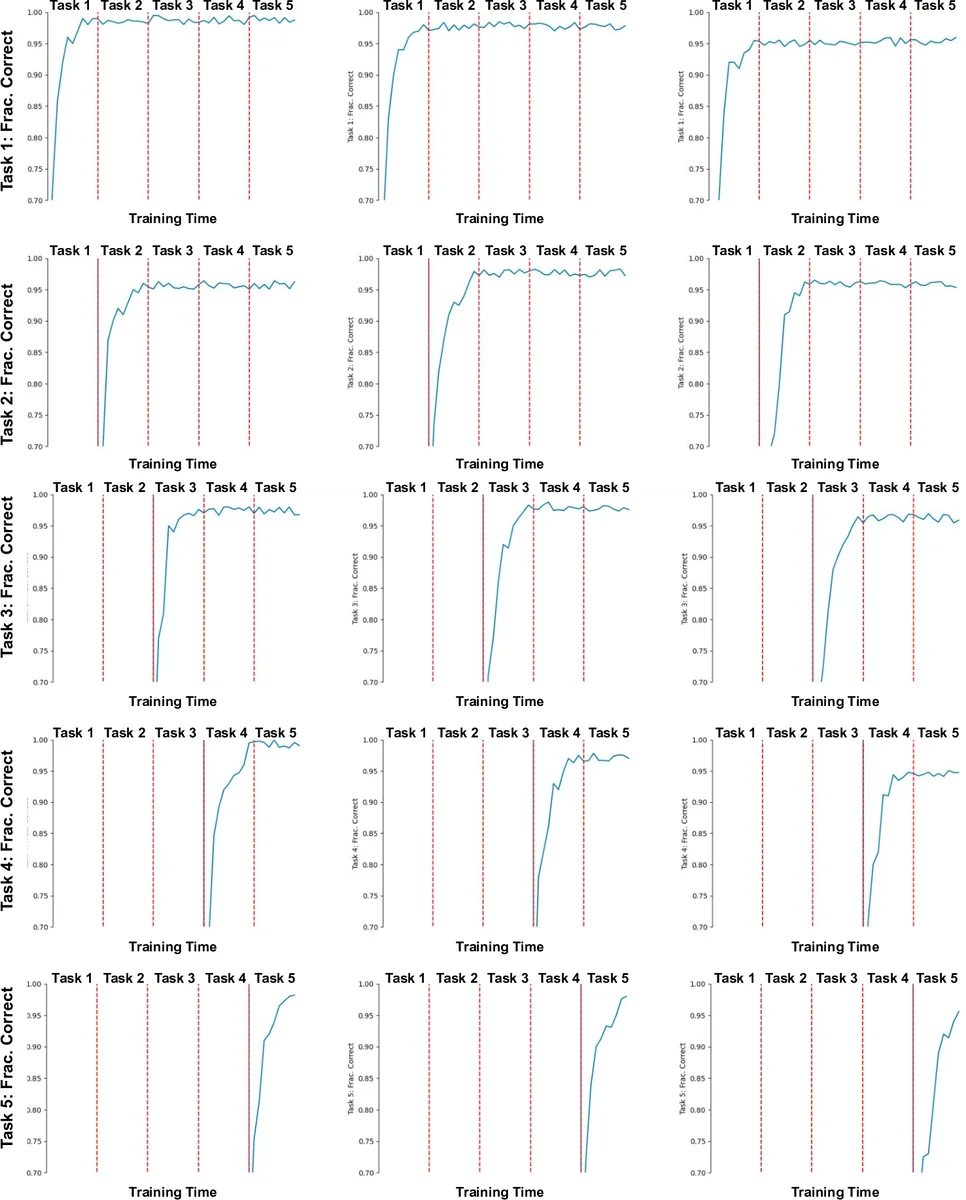
The authors evaluate S‑NCN on standard class‑incremental benchmarks (SplitMNIST, SplitFashionMNIST) and on custom continual‑learning streams. Baselines include rehearsal methods (iCaRL, GEM), regularisation approaches (EWC, SI, LwF), and recent parameter‑isolation techniques (AGEM, OWM). Across all settings, S‑NCN achieves higher average accuracy (3–7 percentage points improvement) and exhibits markedly lower forgetting. Importantly, it does so with near‑zero replay memory and modest computational overhead proportional to K·L·N (K iterations, L layers, N neurons per layer).
Strengths of the work are its biologically plausible learning rules, the integration of task‑specific lateral competition, and the demonstration that a back‑prop‑free system can outperform state‑of‑the‑art continual‑learning methods. The paper also provides thorough ablations showing that alternative competition mechanisms (softmax, anti‑Hebbian) degrade performance, underscoring the importance of the K‑WTA scheme.
However, several limitations remain. The current implementation still requires a task label t during training to index the context memory, so truly task‑free continual learning is not yet achieved. Hyper‑parameters such as the number of winners K, the correction rate β, and the number of inference steps K must be tuned per dataset, which may hinder scalability. Experiments are confined to image classification; applicability to sequential, language, or reinforcement‑learning domains is untested. Finally, while the local Hebbian updates are empirically effective, the paper lacks a formal convergence analysis, leaving open the possibility of instability in more complex settings.
Future directions suggested include: (1) learning to infer task contexts without explicit labels via unsupervised meta‑learning; (2) extending S‑NCN to other modalities (audio, text, control); (3) developing theoretical guarantees for the local learning dynamics; and (4) automating hyper‑parameter selection through Bayesian optimisation or meta‑learning.
In summary, “Lifelong Neural Predictive Coding” presents a compelling alternative to back‑propagation for continual learning, leveraging predictive coding, local Hebbian updates, and task‑driven competition to markedly reduce catastrophic forgetting. While promising, broader validation and further methodological refinements are needed before the approach can be adopted widely in real‑world lifelong‑learning systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment