Adversarial Approximate Inference for Speech to Electroglottograph Conversion
Speech produced by human vocal apparatus conveys substantial non-semantic information including the gender of the speaker, voice quality, affective state, abnormalities in the vocal apparatus etc. Such information is attributed to the properties of the voice source signal, which is usually estimated from the speech signal. However, most of the source estimation techniques depend heavily on the goodness of the model assumptions and are prone to noise. A popular alternative is to indirectly obtain the source information through the Electroglottographic (EGG) signal that measures the electrical admittance around the vocal folds using dedicated hardware. In this paper, we address the problem of estimating the EGG signal directly from the speech signal, devoid of any hardware. Sampling from the intractable conditional distribution of the EGG signal given the speech signal is accomplished through optimization of an evidence lower bound. This is constructed via minimization of the KL-divergence between the true and the approximated posteriors of a latent variable learned using a deep neural auto-encoder that serves an informative prior. We demonstrate the efficacy of the method at generating the EGG signal by conducting several experiments on datasets comprising multiple speakers, voice qualities, noise settings and speech pathologies. The proposed method is evaluated on many benchmark metrics and is found to agree with the gold standard while proving better than the state-of-the-art algorithms on a few tasks such as epoch extraction.
💡 Research Summary
The paper tackles the long‑standing challenge of obtaining an electroglottographic (EGG) signal without dedicated hardware by learning to synthesize the entire EGG waveform directly from the acoustic speech signal. Traditional glottal‑source estimation methods rely on the linear source‑filter model, precise formant tracking, and are highly sensitive to noise and atypical voice qualities, often producing rippled or distorted glottal waveforms. In contrast, EGG measures the electrical admittance across the vocal folds and provides a clean, low‑pass representation of vocal‑fold contact that is robust to acoustic conditions, but requires electrodes and a dedicated device.
The authors formulate speech‑to‑EGG conversion as a conditional distribution transformation problem: they aim to learn the conditional density p(Y|X) where X is a speech segment and Y is the corresponding EGG segment. Because this density is intractable, they adopt a variational inference framework and maximize an evidence lower bound (ELBO). The ELBO consists of a reconstruction term (log‑likelihood of Y given a latent variable Z) and a KL‑divergence term that forces the approximate posterior q(Z|X) to match a prior p(Z). Crucially, instead of using the standard normal prior typical of VAEs, they first train an auto‑encoder on raw EGG signals. The encoder of this auto‑encoder defines a latent space that is demonstrably capable of reconstructing EGG waveforms; this latent space is then treated as an “informative prior”.
A second network, the conditional generator Gθ, maps speech X to the latent space Z. Training Gθ involves two objectives: (1) minimizing the reconstruction loss between the decoded EGG (via the pre‑trained decoder) and the ground‑truth EGG, and (2) minimizing the KL‑divergence between the distribution of Gθ(X) and the informative prior. The KL term is implemented adversarially: a discriminator D tries to distinguish samples drawn from the auto‑encoder prior versus those produced by Gθ, while Gθ learns to fool D, thereby aligning the two distributions. This adversarial variational scheme combines the stability of VAEs with the expressive power of GANs, while allowing a non‑Gaussian, potentially multimodal prior.
Implementation details include 1‑D convolutional encoders/decoders for both the EGG auto‑encoder and the speech‑to‑latent mapper. The loss function aggregates (i) an L2 reconstruction loss on the waveform, (ii) an adversarial cross‑entropy loss for the KL term, and (iii) a smoothness regularizer on the generated EGG. Training uses the Adam optimizer with a learning‑rate schedule, and mini‑batches of paired speech‑EGG frames (≈20 ms). The latent dimensionality is empirically set between 64 and 128.
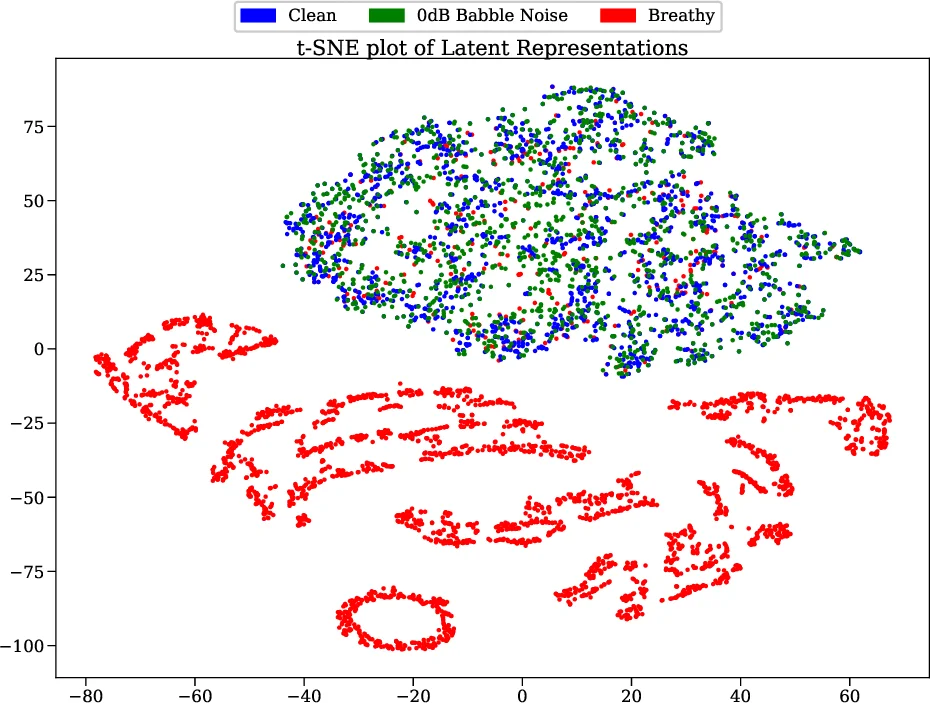
The authors evaluate the method on four datasets covering normal adult speech, various voice qualities (breathy, creaky, etc.), heavy babble noise at 0 dB SNR, and pathological voices. Metrics include mean‑squared error, Pearson correlation, signal‑to‑noise ratio, PESQ, and, importantly, epoch (glottal closure instant) detection F1‑score. Across all metrics the proposed model outperforms classical inverse‑filtering, a WaveNet‑based glottal estimator, and recent conditional GAN/ VAE hybrids. Notably, even under severe noise the generated EGG remains virtually unchanged, confirming the method’s robustness. Epoch detection, which is trivial on true EGG (simple threshold on the differentiated signal), achieves >90 % F1, whereas baseline methods hover around 70 %.
Key contributions are: (1) framing speech‑to‑EGG as a conditional distribution transformation, (2) introducing an ELBO‑based adversarial approximate inference scheme with a learned informative prior, (3) demonstrating that a latent space trained to reconstruct EGG can serve as a powerful prior, (4) achieving state‑of‑the‑art performance on diverse, noisy, and pathological speech, and (5) providing an open‑source implementation (GitHub link). Limitations include dependence on a sizable paired speech‑EGG corpus, computational cost for real‑time deployment, and sensitivity to the chosen latent dimensionality.
Future work suggested includes multi‑speaker simultaneous inference, online/streaming extensions, multimodal fusion with other physiological signals (e.g., EMG), and leveraging self‑supervised speech representations to reduce the amount of labeled data needed.
In summary, the paper presents a novel, data‑driven approach that successfully synthesizes high‑quality EGG waveforms from speech alone, opening the door to hardware‑free voice‑source analysis for clinical screening, voice‑quality assessment, and robust pitch estimation.
Comments & Academic Discussion
Loading comments...
Leave a Comment