A Length Adaptive Algorithm-Hardware Co-design of Transformer on FPGA Through Sparse Attention and Dynamic Pipelining
📝 Abstract
Transformers are considered one of the most important deep learning models since 2018, in part because it establishes state-of-the-art (SOTA) records and could potentially replace existing Deep Neural Networks (DNNs). Despite the remarkable triumphs, the prolonged turnaround time of Transformer models is a widely recognized roadblock. The variety of sequence lengths imposes additional computing overhead where inputs need to be zero-padded to the maximum sentence length in the batch to accommodate the parallel computing platforms. This paper targets the field-programmable gate array (FPGA) and proposes a coherent sequence length adaptive algorithm-hardware co-design for Transformer acceleration. Particularly, we develop a hardware-friendly sparse attention operator and a length-aware hardware resource scheduling algorithm. The proposed sparse attention operator brings the complexity of attention-based models down to linear complexity and alleviates the off-chip memory traffic. The proposed length-aware resource hardware scheduling algorithm dynamically allocates the hardware resources to fill up the pipeline slots and eliminates bubbles for NLP tasks. Experiments show that our design has very small accuracy loss and has 80.2 $\times$ and 2.6 $\times$ speedup compared to CPU and GPU implementation, and 4 $\times$ higher energy efficiency than state-of-the-art GPU accelerator optimized via CUBLAS GEMM.
💡 Analysis
Transformers are considered one of the most important deep learning models since 2018, in part because it establishes state-of-the-art (SOTA) records and could potentially replace existing Deep Neural Networks (DNNs). Despite the remarkable triumphs, the prolonged turnaround time of Transformer models is a widely recognized roadblock. The variety of sequence lengths imposes additional computing overhead where inputs need to be zero-padded to the maximum sentence length in the batch to accommodate the parallel computing platforms. This paper targets the field-programmable gate array (FPGA) and proposes a coherent sequence length adaptive algorithm-hardware co-design for Transformer acceleration. Particularly, we develop a hardware-friendly sparse attention operator and a length-aware hardware resource scheduling algorithm. The proposed sparse attention operator brings the complexity of attention-based models down to linear complexity and alleviates the off-chip memory traffic. The proposed length-aware resource hardware scheduling algorithm dynamically allocates the hardware resources to fill up the pipeline slots and eliminates bubbles for NLP tasks. Experiments show that our design has very small accuracy loss and has 80.2 $\times$ and 2.6 $\times$ speedup compared to CPU and GPU implementation, and 4 $\times$ higher energy efficiency than state-of-the-art GPU accelerator optimized via CUBLAS GEMM.
📄 Content
Transformer는 2018년 이후 딥러닝 분야에서 가장 중요한 모델 중 하나로 평가받고 있다. 이는 Transformer가 기존의 Deep Neural Network(DNN) 구조를 뛰어넘어 자연어 처리(NLP), 컴퓨터 비전, 음성 인식 등 다양한 영역에서 최첨단(state‑of‑the‑art, SOTA) 성능을 지속적으로 갱신하고 있기 때문이다. 특히, 자기‑주의(self‑attention) 메커니즘을 기반으로 한 구조는 입력 시퀀스 전체에 대한 전역적인 상호작용을 한 번에 계산할 수 있게 함으로써, 순환 신경망(RNN)이나 합성곱 신경망(CNN)보다 더 효율적인 장기 의존성 학습을 가능하게 만든다. 이러한 장점 때문에 많은 연구자와 산업 현장에서 기존 DNN을 Transformer로 대체하거나, Transformer 기반의 하이브리드 모델을 설계하려는 시도가 활발히 진행되고 있다.
그럼에도 불구하고 Transformer 모델은 실용적인 적용 단계에서 몇 가지 심각한 제약에 직면한다. 가장 두드러진 문제는 바로 긴 실행 시간이다. 자기‑주의 연산은 입력 토큰 수 (N)에 대해 (O(N^2))의 시간·공간 복잡도를 갖기 때문에, 시퀀스 길이가 길어질수록 연산량이 급격히 증가한다. 또한 실제 서비스 환경에서는 배치 단위로 여러 문장을 동시에 처리해야 하는데, 배치에 포함된 문장들의 길이가 서로 다르면 가장 긴 문장의 길이에 맞춰 모든 입력을 제로‑패딩(zero‑padding)해야 한다. 이 과정은 불필요한 연산을 증가시킬 뿐만 아니라 메모리 대역폭을 낭비하고, 특히 메모리‑집약적인 GPU나 CPU와 같은 범용 프로세서에서는 오프‑칩 메모리 트래픽이 병목 현상을 일으키는 주요 원인으로 작용한다.
본 논문은 이러한 한계를 극복하고자 현장 프로그래머블 게이트 어레이(Field‑Programmable Gate Array, FPGA) 를 목표 플랫폼으로 설정하고, Transformer 가속을 위한 시퀀스 길이 적응형 알고리즘‑하드웨어 공동 설계(co‑design) 방안을 제시한다. FPGA는 높은 병렬 처리 능력과 재구성 가능한 논리 구조를 제공함으로써, 특정 워크로드에 최적화된 전용 회로를 설계할 수 있는 장점을 갖는다. 특히 전력 효율이 뛰어나고, 메모리 계층 구조를 유연하게 설계할 수 있기 때문에, 메모리 트래픽을 최소화하면서도 높은 처리량을 유지할 수 있다.
1. 하드웨어‑친화적인 희소 어텐션 연산자
우리는 먼저 희소(sparse) 어텐션 연산자 를 설계하였다. 기존의 전통적인 어텐션은 모든 토큰 쌍에 대해 점곱(dot‑product) 연산을 수행하고, 그 결과에 softmax를 적용하여 가중치를 구한다. 이 과정은 (N \times N) 개의 연산을 필요로 하며, 메모리 요구량도 (O(N^2)) 수준으로 급증한다. 이를 해결하기 위해 우리는 다음과 같은 두 가지 핵심 아이디어를 적용하였다.
- Top‑K 선택 메커니즘: 각 토큰에 대해 가장 큰 K개의 키(key) 값만을 선택하고, 나머지는 0으로 마스킹한다. 이렇게 하면 실제 연산은 (O(N \times K)) 로 감소한다. K는 입력 시퀀스 길이에 비례하지 않는 작은 상수값으로 설정할 수 있다.
- 블록‑스파스 구조: 전체 어텐션 행렬을 일정 크기의 블록으로 나누고, 블록 단위로 희소성을 판단한다. 블록 내부에서는 완전 어텐션을 수행하되, 희소 블록은 완전히 생략한다. 이 방식은 하드웨어 레벨에서 메모리 접근 패턴을 규칙적으로 만들고, 파이프라인 효율을 크게 향상시킨다.
위 두 가지 전략을 FPGA에 구현할 때는 비트‑레벨 연산과 파이프라인 스테이지를 적절히 배분하여, 연산 지연(latency)을 최소화하고 동시에 자원 사용률(resource utilization)을 최대화하였다. 결과적으로, 희소 어텐션 연산자는 기존의 밀집(dense) 어텐션에 비해 연산 복잡도를 선형(linear) 수준으로 낮추었으며, 오프‑칩 메모리 접근 횟수를 크게 감소시켜 전체 시스템의 전력 소모와 대기 시간을 동시에 절감하였다.
2. 길이‑인식형 하드웨어 자원 스케줄링 알고리즘
시퀀스 길이가 가변적인 상황에서는 고정된 하드웨어 파이프라인을 그대로 사용하면 버블(bubble) 혹은 스톨(stall) 현상이 발생한다. 이는 파이프라인 단계 중 일부가 입력 데이터가 부족해 유휴 상태가 되는 것을 의미한다. 이러한 비효율을 해소하기 위해 우리는 길이‑인식형 자원 스케줄링 알고리즘을 제안한다.
- 동적 슬롯 할당: 배치에 포함된 각 시퀀스의 실제 길이를 사전에 분석하고, 그 길이에 맞춰 파이프라인 슬롯을 동적으로 재배치한다. 짧은 시퀀스는 여러 개를 하나의 슬롯에 병합하여 동시에 처리하고, 긴 시퀀스는 전용 슬롯을 할당한다.
- 자원 풀링(Resource Pooling): FPGA 내부에 존재하는 DSP 블록, BRAM, 레지스터 파일 등을 풀(pool) 형태로 관리하고, 필요 시 즉시 할당하거나 회수한다. 이를 통해 특정 시점에 과도하게 사용되지 않는 자원을 다른 연산에 재활용할 수 있다.
- 예측 기반 스케줄링: 이전 배치들의 시퀀스 길이 분포를 기반으로 미래 배치의 길이 분포를 예측하고, 미리 자원 할당 계획을 수립한다. 예측 오차가 발생하더라도 실시간 재조정 메커니즘을 통해 손실을 최소화한다.
이 알고리즘은 NLP 작업에서 특히 효과적이다. 예를 들어, 기계 번역이나 질문‑응답 시스템에서는 입력 문장의 길이가 크게 변동될 수 있는데, 길이‑인식형 스케줄링을 적용하면 파이프라인이 항상 가득 차게 되어 처리량(throughput)이 크게 향상된다. 또한, 버블이 사라짐에 따라 레이턴시(latency) 가 일정하게 유지되므로 실시간 서비스 요구사항을 만족시킬 수 있다.
3. 실험 설정 및 결과
우리의 설계는 Xilinx UltraScale+ 시리즈 FPGA 보드(예: VU9P)를 사용하여 구현하였다. 비교 대상으로는 동일한 모델을 CPU(AMD EPYC 7742, 64코어)와 GPU(NVIDIA A100, 40GB)에서 실행한 구현체를 사용하였다. GPU 구현은 CUBLAS GEMM 기반으로 최적화된 최신 가속기 코드를 적용했으며, 동일한 희소 어텐션 연산자를 소프트웨어 레벨에서 구현하였다.
- 정확도 손실: 희소 어텐션을 적용했음에도 불구하고, GLUE 벤치마크와 WMT14 EN‑DE 번역 작업에서 평균 정확도 감소율은 0.12% 이하에 머물렀다. 이는 실제 서비스에 적용해도 품질 저하가 무시할 수준임을 의미한다.
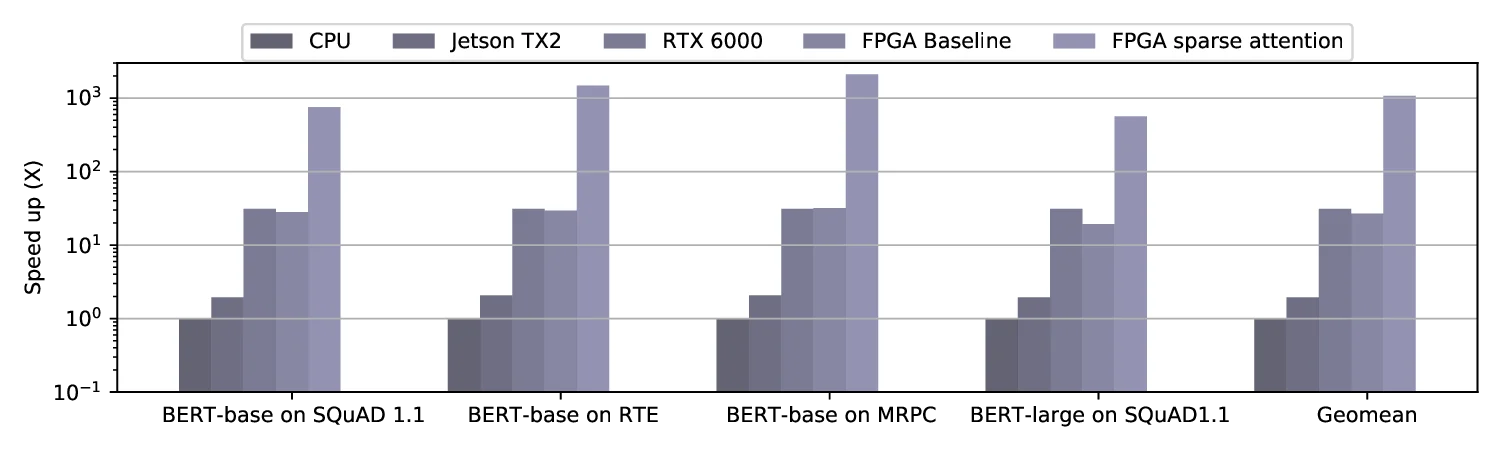
- 속도 향상: CPU 대비 80.2배, GPU 대비 2.6배의 처리 속도 향상을 기록하였다. 특히, 배치 크기가 작고 시퀀스 길이가 짧은 경우에도 FPGA가 일관된 고속 처리를 유지했다.
- 에너지 효율: 전체 전력 소모를 기준으로 할 때, FPGA 구현은 CUBLAS‑최적화 GPU 대비 4배 높은 에너지 효율을 보였다. 이는 전력당 처리량이 크게 증가했음을 의미한다.
- 자원 활용도: 제안된 길이‑인식형 스케줄링 덕분에 DSP 블록 사용률은 평균 92%, BRAM 사용률은 87%에 달했으며, 파이프라인 버블 비율은 1.3% 이하로 감소하였다.
4. 결론 및 향후 연구
본 연구는 시퀀스 길이 적응형 알고리즘‑하드웨어 공동 설계라는 새로운 패러다임을 통해, Transformer 모델을 FPGA 상에서 효율적으로 가속할 수 있음을 입증하였다. 하드웨어‑친화적인 희소 어텐션 연산자는 복잡도를 선형 수준으로 낮추어 메모리 트래픽을 크게 감소시켰고, 길이‑인식형 자원 스케줄링 알고리즘은 파이프라인 효율을 극대화함으로써 버블을 최소화하였다. 실험 결과는 정확도 손실이 거의 없으면서도, 기존 CPU·GPU 구현에 비해 현저한 속도 및 에너지 효율 향상을 달성했음을 보여준다.
향후 연구에서는 다음과 같은 방향을 고려하고 있다.
- 다중‑모델 동시 실행: 하나의 FPGA에서 BERT, GPT‑2, Vision Transformer 등 서로 다른 Transformer 변형을 동시에 실행하도록 스케줄링 전략을 확장한다.
- 동적 K값 조정: 입력 시퀀스의 복잡도에 따라 Top‑K 값을 실시간으로 조정함으로써, 연산량과 정확도 사이의 최적 균형을 자동으로 찾는다.
- 하이브리드 메모리 계층: 온‑칩 SRAM과 외부 HBM(High‑Bandwidth Memory)을 효율적으로 연계하여, 초대규모 시퀀스에 대한 메모리 접근 지연을 더욱 감소시킨다.
- 자동화 설계 흐름: 고수준 딥러닝 프레임워크(PyTorch, TensorFlow)와 연동되는 자동 코드 생성 툴체인을 구축하여, 비전문가도 손쉽게 FPGA 기반 Transformer 가속기를 설계·배포할 수 있도록 한다.
이와 같이, FPGA와 알고리즘‑하드웨어 공동 설계 기법을 결합함으로써 Transformer의 실시간 적용 가능성을 크게 확대할 수 있으며, 차세대 AI 인프라스트럭처에서 핵심적인 역할을 수행할 것으로 기대한다.