Comment on "An excess of massive stars in the local 30 Doradus starburst"
Schneider et al. (Science, 2018) used an ad hoc statistical method in their calculation of the stellar initial mass function. Adopting an improved approach, we reanalyse their data and determine a power law exponent of $2.05_{-0.14}^{+0.13}$. Alternative assumptions regarding data set completeness and the star formation history model can shift the inferred exponent to $2.11_{-0.19}^{+0.17}$ and $2.15_{-0.13}^{+0.13}$, respectively.
💡 Research Summary
Schneider et al. (2018) reported a shallow stellar initial mass function (IMF) in the 30 Doradus starburst region, finding a power‑law exponent α = 1.90 +0.37 −0.26, significantly flatter than the canonical Salpeter value of 2.35. Their analysis relied on individual stellar mass and age estimates obtained with the BONNSAI Bayesian code, and they constructed an overall mass distribution by simply adding together the posterior probability density functions (PDFs) of each star. The authors of the present comment argue that this procedure lacks a proper statistical foundation: the summed distribution does not represent the posterior PDF of the underlying mass function.
To address this, they adopt a hierarchical Bayesian framework, following Mandel (2010). They treat each star’s mass and age as independent Gaussian likelihoods in log‑space, with means set to the peaks of the Schneider et al. PDFs and standard deviations matched to the 68 % credible widths. The IMF is modeled as a single power law with exponent α, while the star‑formation history (SFH) is described by a truncated Gaussian characterized by a mean and a standard deviation. Broad, non‑informative priors are placed on α and the SFH parameters.
The full hierarchical model includes a latent “true” mass and age for every star, the global IMF exponent, and the SFH parameters. Because the dimensionality is high, the authors employ Hamiltonian Monte Carlo (HMC) sampling via the Stan platform to efficiently explore the posterior distribution.
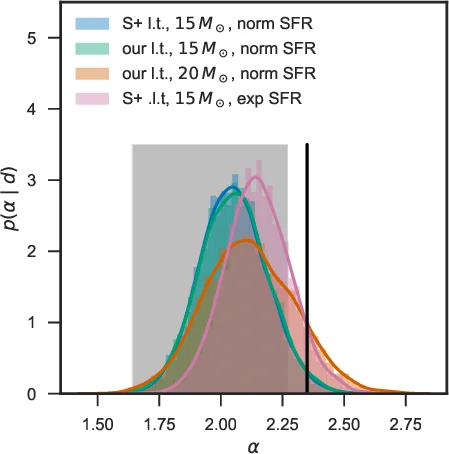
Their fiducial analysis, which assumes the same completeness limit (M ≥ 15 M⊙) and SFH as Schneider et al., yields a posterior median α = 2.05 with a 68 % credible interval of +0.14/−0.13. This value is about one standard deviation higher than Schneider et al.’s result, and the uncertainty is reduced by more than a factor of two. The authors demonstrate that the hierarchical approach provides a statistically rigorous inference on the IMF while substantially tightening the confidence bounds.
To assess systematic effects, they explore three variations: (1) an independent fit to massive‑star main‑sequence lifetimes (based on Brott et al. 2011 and Köhler et al. 2015) – this yields the same α = 2.05, indicating robustness to the lifetime prescription; (2) raising the completeness threshold from 15 M⊙ to 20 M⊙ – the inferred exponent steepens to α = 2.11 +0.19 −0.17, reflecting the observed paucity of stars in the 15–20 M⊙ range; (3) replacing the Gaussian SFH with a double‑exponential model that allows asymmetric rise and decay – this produces α = 2.15 +0.13 −0.13, the steepest among the tested scenarios. These tests show that while the statistical uncertainty is small, systematic choices (completeness limit, SFH shape) can shift the exponent by amounts comparable to or larger than the statistical error.
The authors also test a broken‑power‑law IMF with an additional high‑mass break, introducing three extra parameters (break mass, low‑mass slope, high‑mass slope). The current data do not constrain these extra degrees of freedom, and posterior predictive checks indicate no preference for a broken model.
Posterior predictive checks are performed for all models: synthetic datasets generated from the fitted IMF and SFH reproduce the observed distributions of stellar masses and ages, and the predicted numbers of stars above 30 M⊙ and 60 M⊙ agree with the observations. This validates the hierarchical models and confirms that the observed sample is consistent with being drawn from the inferred IMF.
In summary, the comment demonstrates that a proper hierarchical Bayesian analysis of the 30 Doradus massive‑star sample yields an IMF exponent close to the Salpeter value, with significantly reduced statistical uncertainty compared with the original study. However, the result remains sensitive to systematic modeling choices such as the assumed completeness limit and the functional form of the star‑formation history. The authors conclude that, despite the high quality of the Schneider et al. dataset, inferring the precise shape of the IMF remains challenging due to these systematic uncertainties, and future work should aim to refine completeness assessments, stellar evolution models, and SFH characterizations.
Comments & Academic Discussion
Loading comments...
Leave a Comment