OpenMP, OpenMP/MPI, and CUDA/MPI C programs for solving the time-dependent dipolar Gross-Pitaevskii equation
We present new versions of the previously published C and CUDA programs for solving the dipolar Gross-Pitaevskii equation in one, two, and three spatial dimensions, which calculate stationary and non-stationary solutions by propagation in imaginary or real time. Presented programs are improved and parallelized versions of previous programs, divided into three packages according to the type of parallelization. First package contains improved and threaded version of sequential C programs using OpenMP. Second package additionally parallelizes three-dimensional variants of the OpenMP programs using MPI, allowing them to be run on distributed-memory systems. Finally, previous three-dimensional CUDA-parallelized programs are further parallelized using MPI, similarly as the OpenMP programs. We also present speedup test results obtained using new versions of programs in comparison with the previous sequential C and parallel CUDA programs. The improvements to the sequential version yield a speedup of 1.1 to 1.9, depending on the program. OpenMP parallelization yields further speedup of 2 to 12 on a 16-core workstation, while OpenMP/MPI version demonstrates a speedup of 11.5 to 16.5 on a computer cluster with 32 nodes used. CUDA/MPI version shows a speedup of 9 to 10 on a computer cluster with 32 nodes.
💡 Research Summary
**
The paper presents three new software packages for solving the time‑dependent dipolar Gross‑Pitaevskii (GP) equation in one, two, and three spatial dimensions. The GP equation describes the dynamics of dilute trapped Bose‑Einstein condensates (BECs) with both contact and long‑range dipolar interactions. The original codes, released in earlier publications, were sequential C programs and a CUDA‑accelerated version. While the CUDA version offered substantial speed‑up on a single GPU, it required specialized hardware and could not exploit multi‑core CPUs or distributed‑memory clusters. To address these limitations, the authors have re‑engineered the solvers using three parallelization strategies:
-
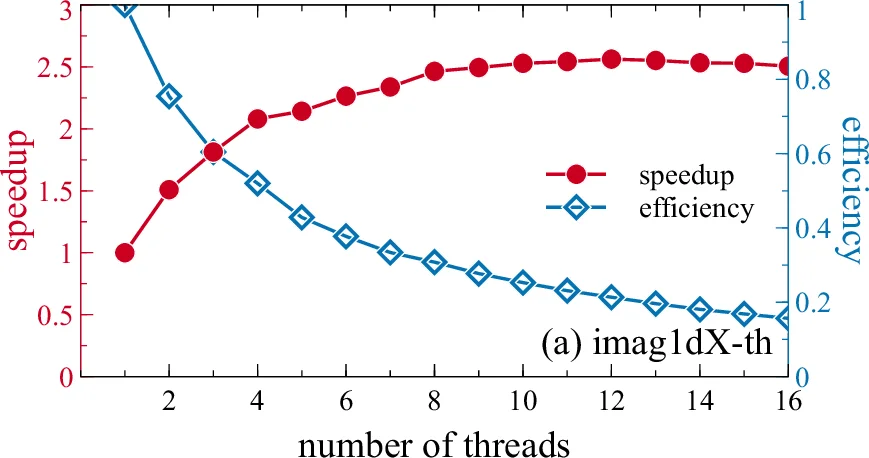
OpenMP‑only package (DBEC‑GP‑OMP) – The sequential C programs were first modernized by switching from a real‑to‑complex (R2C) Fourier transform that halves memory consumption and by exploiting the built‑in OpenMP support of the FFTW3 library. OpenMP pragmas were added to all computational loops, including the evaluation of the dipolar term, which also uses FFTs. Memory overhead from thread‑private variables was mitigated by pointer aliasing and reuse of temporary buffers. As a result, even a single‑thread run of the OpenMP version is 1.1–1.9 × faster than the original serial code, and scaling to 16 threads on a 16‑core workstation yields speed‑ups of 2–12 × for 2‑D and 3‑D problems.
-
Hybrid OpenMP/MPI package (DBEC‑GP‑MPI) – For the computationally intensive 3‑D cases, the OpenMP‑parallelized code was further extended to run on distributed‑memory clusters using MPI. A simple slab (one‑dimensional) domain decomposition is employed: the first spatial dimension (NX) is split among MPI ranks, while each rank retains the full NY and NZ extents locally. This design minimizes inter‑process communication because most operations remain local. When a computation requires the full NX dimension, a transpose is performed using FFTW3’s dedicated transpose interface (implemented via MPI_Alltoall). The authors note that running one MPI process per node, each spawning as many OpenMP threads as there are CPU cores, gives the best performance.
-
Hybrid CUDA/MPI package (DBEC‑GP‑MPI‑CUDA) – The same slab decomposition is applied to the existing CUDA‑based 3‑D solver. Because cuFFT does not provide an MPI‑aware transpose, the authors implemented custom MPI data types and an All‑to‑All exchange to perform the necessary transposes. The three‑dimensional FFT is carried out using a row‑column algorithm: each GPU performs 1‑D FFTs along one axis, the data are transposed across MPI ranks, then 1‑D FFTs are performed along the second axis, and finally a third set of FFTs completes the transform. This approach allows the CUDA code to scale across multiple GPUs on a cluster.
Performance testing was conducted on the PARADOX supercomputing facility (dual‑socket Intel Xeon E5‑2670 nodes, each with 16 cores, 32 GB RAM, and a Tesla M2090 GPU). Grid sizes used for benchmarking were 10⁵ points for 1‑D, 10⁴ × 10⁴ for 2‑D, and 480³ for 3‑D simulations, with 1000 propagation steps. Timing excludes initialization, memory allocation, FFT plan creation, and I/O; only the core propagation loop is measured.
Key results:
- OpenMP only – Single‑thread runs already benefit from the R2C FFT (1.1–1.9 × faster). With 16 threads, 2‑D and 3‑D problems achieve 9–12 × speed‑up, while 1‑D problems see modest gains (≈2 ×). Parallel efficiency remains above 60 % for 2‑D/3‑D cases up to 16 threads.
- OpenMP/MPI – Strong scaling on 32 nodes (512 cores) yields speed‑ups of 11.5–16.5 × for the 3‑D imaginary‑time and real‑time solvers. The slab decomposition and FFTW3 transposes keep communication overhead low.
- CUDA/MPI – Using one MPI process per node and one GPU per process, the hybrid GPU version attains 9–10 × speed‑up on the same 32‑node cluster. Custom transposes and the row‑column FFT algorithm enable efficient distribution of the 3‑D FFT across GPUs.
The authors also switched MPI output to binary format to reduce file size and simplify post‑processing; a conversion script is provided. All source code is released under the Apache 2.0 license, encouraging community contributions and further extensions.
In summary, the paper delivers a comprehensive, high‑performance toolkit for dipolar GP simulations that can run efficiently on a single multi‑core workstation, a CPU‑only cluster, or a multi‑GPU cluster. By combining algorithmic improvements (R2C FFT, memory reuse), thread‑level parallelism (OpenMP), process‑level distribution (MPI slab decomposition), and GPU acceleration (CUDA), the authors achieve substantial speed‑ups while maintaining numerical accuracy. The work significantly lowers the computational barrier for researchers studying Bose‑Einstein condensates, nonlinear quantum fluids, and related nonlinear partial differential equations, and it provides a solid foundation for future scaling to even larger problem sizes or more sophisticated physical models.
Comments & Academic Discussion
Loading comments...
Leave a Comment