CUDA programs for solving the time-dependent dipolar Gross-Pitaevskii equation in an anisotropic trap
In this paper we present new versions of previously published numerical programs for solving the dipolar Gross-Pitaevskii (GP) equation including the contact interaction in two and three spatial dimensions in imaginary and in real time, yielding both stationary and non-stationary solutions. New versions of programs were developed using CUDA toolkit and can make use of Nvidia GPU devices. The algorithm used is the same split-step semi-implicit Crank-Nicolson method as in the previous version (R. Kishor Kumar et al., Comput. Phys. Commun. 195, 117 (2015)), which is here implemented as a series of CUDA kernels that compute the solution on the GPU. In addition, the Fast Fourier Transform (FFT) library used in the previous version is replaced by cuFFT library, which works on CUDA-enabled GPUs. We present speedup test results obtained using new versions of programs and demonstrate an average speedup of 12 to 25, depending on the program and input size.
💡 Research Summary
This paper presents a CUDA‑based implementation of numerical programs for solving the dipolar Gross‑Pitaevskii (GP) equation with contact interaction in two and three spatial dimensions, both in imaginary‑time (for stationary states) and real‑time (for dynamical evolution). The underlying algorithm is the split‑step semi‑implicit Crank‑Nicolson scheme that was previously employed in a CPU‑only Fortran/C package (AEWL v1.0, Comput. Phys. Commun. 195, 117 (2015)). The authors have ported the most computationally intensive parts of the code to NVIDIA GPUs using the CUDA toolkit and replaced the FFTW library with cuFFT, which runs natively on the GPU.
The new package, identified as AEWL v2.0, consists of six executables: imag2dXY‑cuda, imag2dXZ‑cuda, imag3d‑cuda (imaginary‑time propagation) and real2dXY‑cuda, real2dXZ‑cuda, real3d‑cuda (real‑time propagation). All programs retain the same input structure as the original version; the CPU still performs initialization and I/O, while the heavy numerical kernels are executed on the GPU. The authors have rewritten the core functions—calcpsidd2, calcnu, calclux/y/z, calcnorm, calcrms, and calcmuen—as CUDA kernels using a grid‑stride loop pattern, allowing a single block size to be used across all kernels. Block sizes are defined in src/utils/cudautils.cuh and can be tuned for specific GPU architectures (e.g., Tesla, GeForce, RTX).
A major focus of the work is memory management. The dipolar term requires Fourier transforms of the density, which are now performed with cuFFT’s real‑to‑complex (R2C) and complex‑to‑real (C2R) transforms, exploiting the Hermitian symmetry of a real density field to halve memory usage. The authors introduce a configurable parameter POTMEM that controls how trap and dipolar potentials are stored:
- POTMEM = 2 – both potentials are allocated as separate tensors in GPU memory (maximum performance, highest memory consumption).
- POTMEM = 1 – a single tensor is reused for both potentials, reducing memory by roughly 50 % but incurring extra copy operations.
- POTMEM = 0 – potentials remain in host (CPU) memory and are accessed over the PCI‑Express bus (lowest memory demand, reduced performance).
If POTMEM is omitted, the program automatically detects available GPU memory and selects the most suitable mode. The authors also reuse temporary tensors for multiple purposes (e.g., storing Crank‑Nicolson coefficients) to keep the overall GPU footprint low. Because the recursive nature of the Crank‑Nicolson update prevents straightforward inner‑loop parallelisation, the authors parallelise the outer loops: each GPU thread processes an entire inner loop sequentially, while the outer loops are distributed across threads. This design avoids the overhead of launching many small kernels and fits well with typical grid sizes used in BEC simulations.
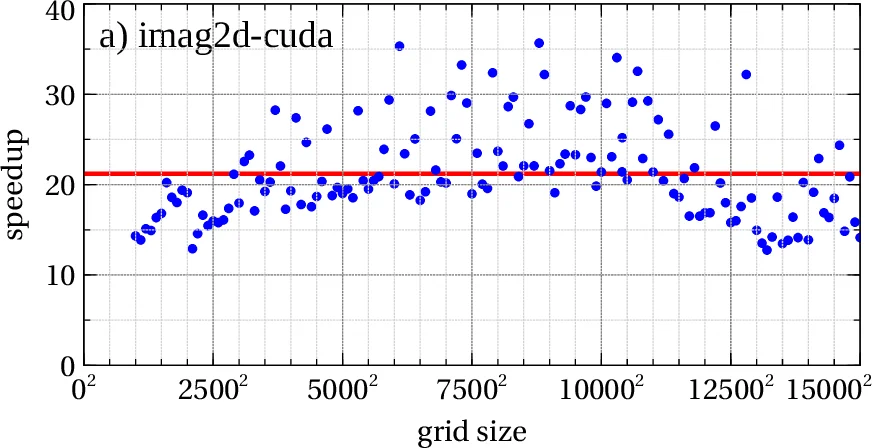
Performance testing was carried out on a Tesla M2090 GPU (6 GB) paired with an Intel Xeon E5‑2670 CPU (32 GB RAM) at the Institute of Physics Belgrade’s PARADOX supercomputing facility. Speed‑up results, plotted as a function of grid size, show average accelerations ranging from 12× to 25× compared with the original CPU version running on a single core. The gain grows with larger grids because cuFFT’s algorithms scale more favourably on the GPU than FFTW on the CPU, and because the GPU’s massive parallelism is better utilised. Specific observations include:
- 2D imaginary‑time programs (imag2dXY‑cuda, imag2dXZ‑cuda) achieve up to 25× speed‑up for grid sizes around 15 000 × 15 000.
- 2D real‑time programs show similar improvements, with typical run times of a few minutes on a “medium” workstation.
- 3D programs (imag3d‑cuda, real3d‑cuda) reach speed‑ups of 5–25×, limited by GPU memory; the largest feasible grid was 600³ for imag3d‑cuda and 540³ for real3d‑cuda on the M2090.
- The dispersion in speed‑up values for the CPU version is attributed to FFTW’s ESTIMATE flag, whereas cuFFT provides more consistent performance.
The authors discuss several practical limitations. The code requires a CUDA‑capable GPU with Compute Capability ≥ 2.0 and CUDA Toolkit ≥ 6.0. Because GPU memory is typically smaller than system RAM, very large simulations may need to reduce grid size or select POTMEM = 1 or 0. The current implementation does not fully parallelise the innermost recursive loops; for extremely large grids this could become a bottleneck, though the overhead of additional kernel launches would need to be weighed against the benefit. The authors also note that cuFFT may demand up to eight times more temporary memory for certain prime‑size dimensions; the program automatically adjusts the grid size when necessary and reports any changes in the output.
In summary, this work delivers a robust, open‑source GPU‑accelerated suite for dipolar Bose‑Einstein condensate simulations. By preserving the well‑tested Crank‑Nicolson algorithm, integrating cuFFT, and carefully managing GPU memory, the authors achieve substantial speed‑ups without sacrificing numerical accuracy. The package is distributed via the CPC Program Library under a standard CPC licence, includes test data, and can be compiled on any Linux system equipped with an appropriate NVIDIA GPU. Future extensions could involve multi‑GPU scaling, higher‑order time‑stepping schemes, or incorporation of additional physical effects (e.g., rotation, disorder). The present implementation already enables researchers to explore larger parameter spaces and longer dynamical evolutions that were previously prohibitive on CPU‑only platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment