PennyLane: Automatic differentiation of hybrid quantum-classical computations
PennyLane is a Python 3 software framework for differentiable programming of quantum computers. The library provides a unified architecture for near-term quantum computing devices, supporting both qubit and continuous-variable paradigms. PennyLane’s core feature is the ability to compute gradients of variational quantum circuits in a way that is compatible with classical techniques such as backpropagation. PennyLane thus extends the automatic differentiation algorithms common in optimization and machine learning to include quantum and hybrid computations. A plugin system makes the framework compatible with any gate-based quantum simulator or hardware. We provide plugins for hardware providers including the Xanadu Cloud, Amazon Braket, and IBM Quantum, allowing PennyLane optimizations to be run on publicly accessible quantum devices. On the classical front, PennyLane interfaces with accelerated machine learning libraries such as TensorFlow, PyTorch, JAX, and Autograd. PennyLane can be used for the optimization of variational quantum eigensolvers, quantum approximate optimization, quantum machine learning models, and many other applications.
💡 Research Summary
**
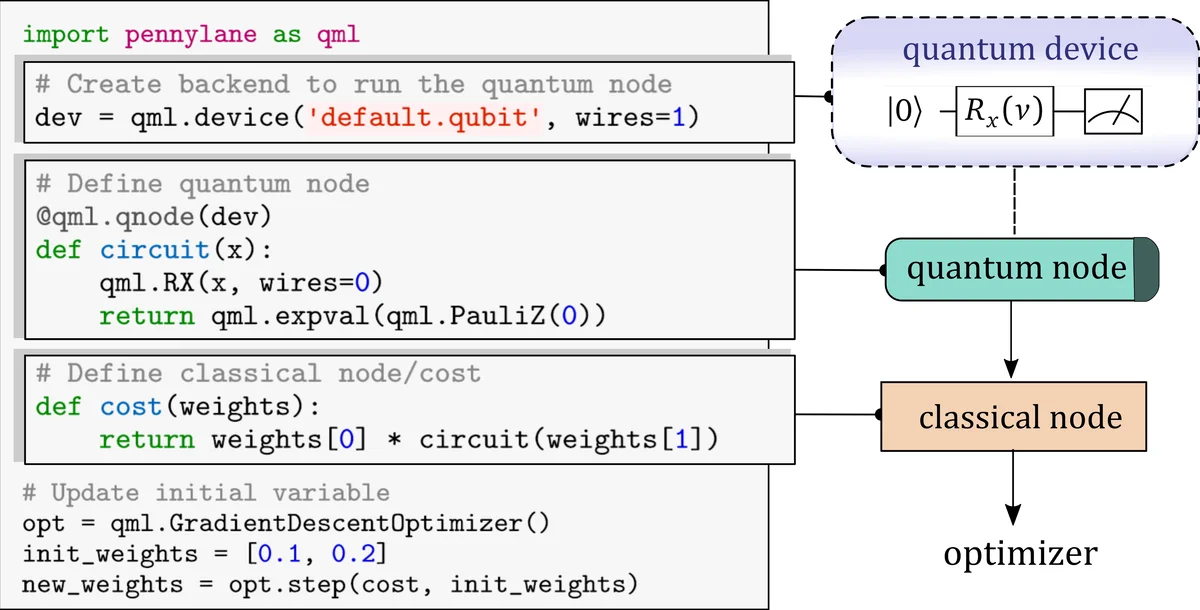
PennyLane is an open‑source Python‑3 library that brings together quantum circuits and classical machine‑learning models under a single differentiable programming framework. The core idea is to represent a hybrid quantum‑classical computation as a directed acyclic graph (DAG) whose nodes are either classical functions or quantum nodes (QNodes). A QNode encapsulates a parametrized variational circuit that prepares an initial state, applies a sequence of gates that may depend on both trainable parameters θ and input data x, and finally measures a set of commuting observables. Expectation values are obtained either by averaging over a finite number of shots R on hardware or by exact evaluation on simulators (the default when shots=None).
The main technical contribution is the ability to differentiate through quantum nodes using the same automatic‑differentiation (AD) engines that power TensorFlow, PyTorch, JAX, and Autograd. PennyLane does not require back‑propagation through the internal quantum state; instead it computes the vector‑Jacobian product (VJP) of each quantum node with respect to its inputs and parameters. Three gradient strategies are supported: (i) the parameter‑shift rule, which evaluates the circuit at shifted parameter values (±π/2) to obtain an exact analytic gradient and is hardware‑friendly; (ii) finite‑difference (numerical) gradients, which are simple but suffer from shot noise and higher cost; and (iii) full back‑propagation, which is only feasible on simulators that can store the full state vector at every step and becomes memory‑intensive for larger qubit counts. The library automatically selects the appropriate method or allows the user to specify it.
A plugin architecture abstracts the quantum device. Any gate‑based simulator or real quantum processor can be integrated by implementing a small set of methods (apply, expval, var, sample). Out‑of‑the‑box plugins connect to Xanadu Cloud, IBM Quantum, Amazon Braket, Rigetti, and several open‑source simulators, and the framework also supports continuous‑variable (CV) photonic platforms, extending its reach beyond qubit‑based hardware.
On the classical side, PennyLane provides seamless wrappers for TensorFlow, PyTorch, JAX, and Autograd. Users can decorate a quantum function with @qml.qnode and embed it inside a conventional neural‑network module. During training, the classical optimizer updates both classical parameters (e.g., bias terms) and quantum parameters (circuit angles) using the gradients supplied by PennyLane. This enables a wide range of hybrid algorithms:
- Variational Quantum Eigensolver (VQE) – the quantum node evaluates the Hamiltonian expectation value, while a classical optimizer minimizes the energy.
- Quantum Approximate Optimization Algorithm (QAOA) – alternating problem and mixer unitaries are parametrized and optimized via gradient descent.
- Quantum classifiers – data is encoded into a circuit, measured, and combined with a classical bias before applying a loss function.
- Quantum Generative Adversarial Networks (QGANs) – both generator and discriminator are variational circuits; their costs are computed from measurement statistics and optimized adversarially.
PennyLane also introduces “differentiable quantum transforms,” which allow entire circuit transformations (e.g., error‑mitigation layers, circuit recompilation) to be treated as differentiable modules. This opens the door to jointly learning algorithmic structure and hardware‑level control.
Performance experiments compare the three gradient methods. The parameter‑shift rule scales linearly with the number of parameters and shots, while keeping memory constant, making it suitable for real hardware. Full back‑propagation, although faster on small simulators, quickly becomes infeasible due to the need to store the full quantum state at each gate. Numerical gradients are the least efficient and most sensitive to noise. The authors demonstrate VQE and QAOA runs on IBM Q, Rigetti, and Xanadu Cloud devices, highlighting how shot noise and hardware errors affect convergence.
The codebase is hosted on GitHub, with an open contribution model that grants co‑authorship on the whitepaper to significant contributors. Documentation, tutorials, and a library of ready‑to‑run examples are available at pennylane.ai, lowering the barrier for both researchers and industry practitioners.
In summary, PennyLane unifies quantum‑classical hybrid computation with modern automatic‑differentiation techniques, providing a hardware‑agnostic, ML‑friendly platform for designing, training, and deploying variational quantum algorithms. By abstracting away the complexities of gradient calculation on quantum hardware and integrating with the dominant ML ecosystems, it accelerates the development of practical quantum‑enhanced applications across chemistry, optimization, and machine learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment