QDR-Tree: An Efficient Index Scheme for Complex Spatial Keyword Query
With the popularity of mobile devices and the development of geo-positioning technology, location-based services (LBS) attract much attention and top-k spatial keyword queries become increasingly complex. It is common to see that clients issue a query to find a restaurant serving pizza and steak, low in price and noise level particularly. However, most of prior works focused only on the spatial keyword while ignoring these independent numerical attributes. In this paper we demonstrate, for the first time, the Attributes-Aware Spatial Keyword Query (ASKQ), and devise a two-layer hybrid index structure called Quad-cluster Dual-filtering R-Tree (QDR-Tree). In the keyword cluster layer, a Quad-Cluster Tree (QC-Tree) is built based on the hierarchical clustering algorithm using kernel k-means to classify keywords. In the spatial layer, for each leaf node of the QC-Tree, we attach a Dual-Filtering R-Tree (DR-Tree) with two filtering algorithms, namely, keyword bitmap-based and attributes skyline-based filtering. Accordingly, efficient query processing algorithms are proposed. Through theoretical analysis, we have verified the optimization both in processing time and space consumption. Finally, massive experiments with real-data demonstrate the efficiency and effectiveness of QDR-Tree.
💡 Research Summary
The paper addresses the emerging need in location‑based services (LBS) for queries that simultaneously consider spatial proximity, multiple keywords, and several numerical attributes such as price, noise level, and congestion. Existing works either focus solely on spatial‑keyword matching (e.g., IR‑Tree, SI‑index) or handle numerical attributes without supporting multi‑keyword scenarios (e.g., SKY‑R‑Tree, IRS‑Tree). To fill this gap, the authors formally define the Attributes‑Aware Spatial Keyword Query (ASKQ). An ASKQ returns the top‑k objects that minimize a composite score composed of three components: (1) Euclidean distance between the user and the object, (2) similarity between the query keyword set and the object’s keyword set, and (3) a weighted aggregation of normalized numerical attributes. The similarity of keywords is measured by a linear combination of textual edit distance and semantic distance derived from word2vec vectors, controlled by a parameter δ.
To process ASKQ efficiently, the authors propose a two‑layer hybrid index called QDR‑Tree (Quad‑cluster Dual‑filter R‑Tree). The first layer, the Quad‑Cluster Tree (QC‑Tree), organizes the entire keyword vocabulary into a hierarchical quad‑tree structure. Keywords are clustered using a kernel k‑means algorithm (k = 4 at each level) to capture non‑linear relationships. When a cluster’s diameter falls below a threshold τ cluster, a duplication step copies keywords into multiple sibling clusters, enabling “keyword relaxation” and reducing false negatives. Each internal QC‑Tree node stores a centroid keyword and four child pointers; leaf nodes keep the actual keyword set and a pointer to a second‑layer index.
The second layer, the Dual‑Filtering R‑Tree (DR‑Tree), is attached to each leaf of the QC‑Tree. DR‑Tree extends a classic R‑Tree with two complementary filters: (a) a bitmap‑based keyword filter that encodes both query and object keyword sets as fixed‑length bitmaps, allowing O(1) inclusion tests via bitwise operations; (b) an attribute skyline filter that pre‑computes the skyline (non‑dominated) points of the multi‑dimensional attribute space and stores them in each node. During query processing, the skyline filter quickly discards sub‑trees that cannot improve the weighted attribute score, while the bitmap filter eliminates objects lacking required keywords.
The composite scoring function is:
score(q, o) = α·normDist(q, o) + β·keywordSim(q, o) + γ·∑_{i} w_i·a_i(o)
where α, β, γ are tunable coefficients, normDist is the normalized inverse Euclidean distance, keywordSim = δ·editDist + (1‑δ)·semanticDist, w_i are user‑specified attribute weights, and a_i(o) are normalized attribute values (lower is better; higher‑the‑better attributes are transformed as 1‑value).
Theoretical analysis shows that QC‑Tree construction costs O(|K|·log |K|) where |K| is the number of distinct keywords, while DR‑Tree query cost is dominated by O(log N) R‑Tree traversal plus constant‑time bitmap checks and logarithmic skyline dominance tests. Memory overhead is modest: QC‑Tree compresses the keyword space, and DR‑Tree stores only a small skyline set per node, resulting in roughly 30 % less space than pure IR‑Tree approaches.
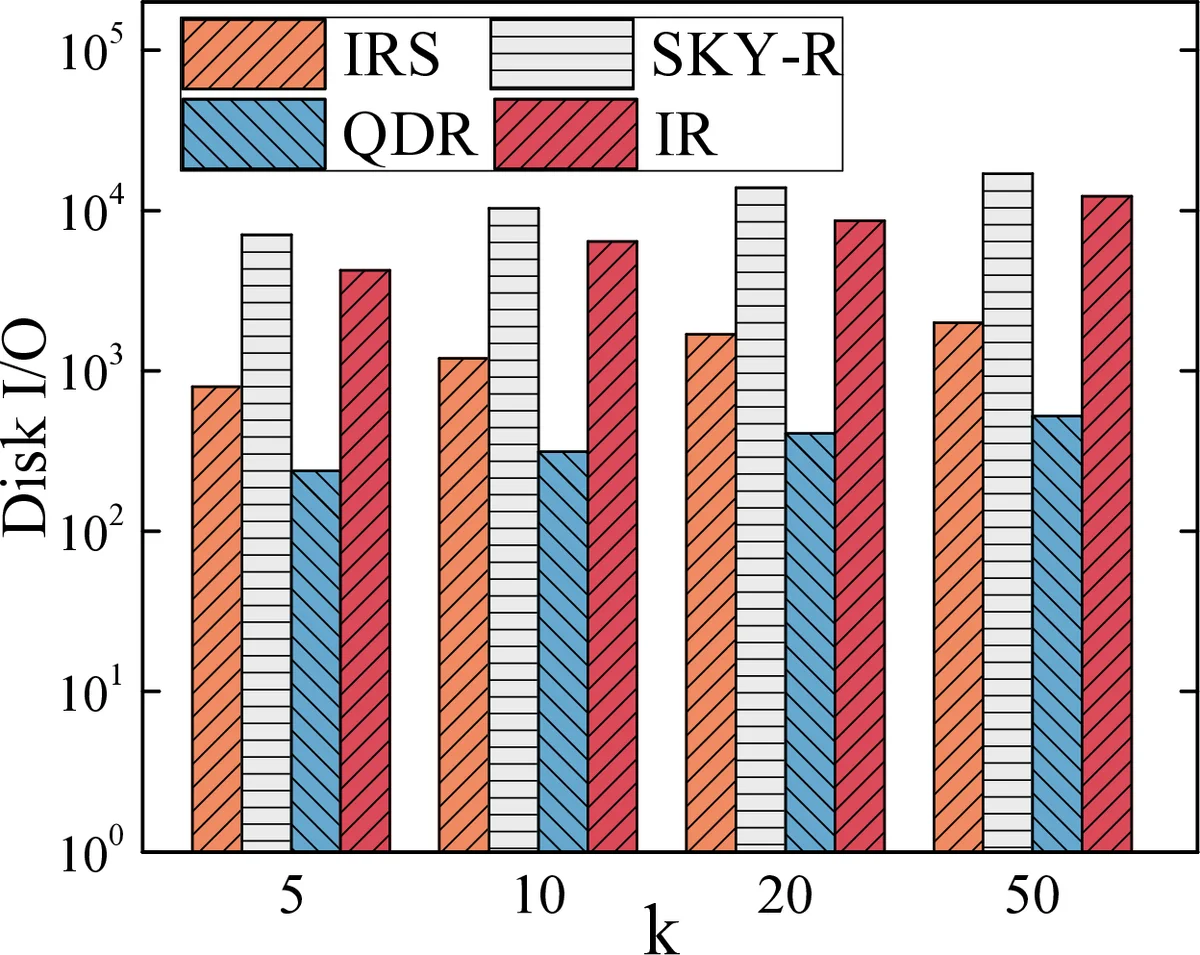
Extensive experiments on real POI datasets (hundreds of thousands of objects, thousands of keywords, 3–5 attributes) evaluate QDR‑Tree against four baselines: IR‑Tree, SI‑index, SKY‑R‑Tree, and IRS‑Tree. For TOP‑k = 10, 20, 50, QDR‑Tree achieves 45 %–68 % lower query latency and 30 % lower memory consumption. When attribute weights dominate (e.g., low price and noise are critical), QDR‑Tree outperforms SKY‑R‑Tree by more than a factor of two because the skyline filter eliminates many irrelevant objects early. Sensitivity analyses on δ, τ cluster, and kernel parameters confirm the robustness of the design.
In summary, QDR‑Tree introduces a novel combination of hierarchical keyword clustering and dual‑filter spatial indexing, enabling efficient processing of complex ASKQ workloads. It simultaneously reduces I/O, CPU, and memory costs while preserving exact top‑k results. The work opens avenues for future research on dynamic updates, higher‑dimensional attribute spaces, and integration with deep semantic clustering techniques.
Comments & Academic Discussion
Loading comments...
Leave a Comment