A Deep Generative Model of Speech Complex Spectrograms
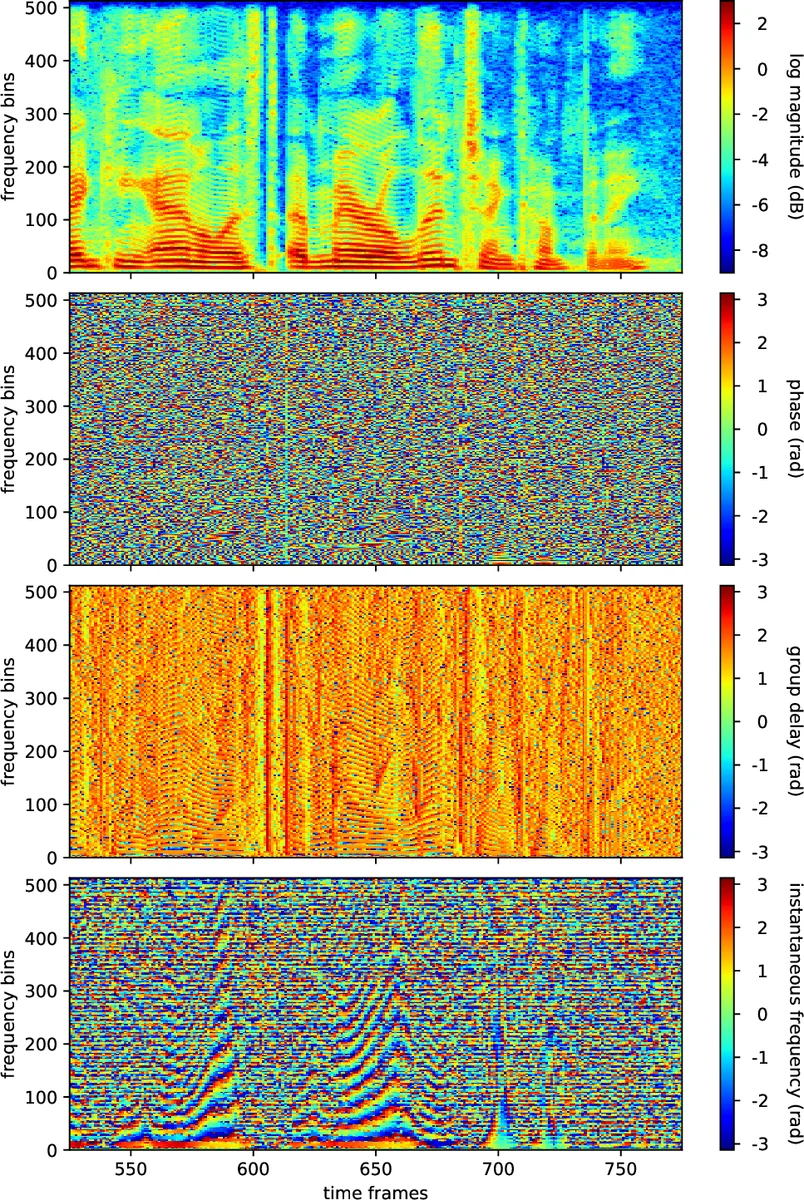
This paper proposes an approach to the joint modeling of the short-time Fourier transform magnitude and phase spectrograms with a deep generative model. We assume that the magnitude follows a Gaussian distribution and the phase follows a von Mises distribution. To improve the consistency of the phase values in the time-frequency domain, we also apply the von Mises distribution to the phase derivatives, i.e., the group delay and the instantaneous frequency. Based on these assumptions, we explore and compare several combinations of loss functions for training our models. Built upon the variational autoencoder framework, our model consists of three convolutional neural networks acting as an encoder, a magnitude decoder, and a phase decoder. In addition to the latent variables, we propose to also condition the phase estimation on the estimated magnitude. Evaluated for a time-domain speech reconstruction task, our models could generate speech with a high perceptual quality and a high intelligibility.
💡 Research Summary
The paper introduces a novel deep generative model that jointly models the magnitude and phase components of short‑time Fourier transform (STFT) representations of speech. While most existing speech processing methods treat magnitude and phase separately—often estimating magnitude and then applying a post‑hoc phase reconstruction algorithm such as Griffin‑Lim—this work integrates both components within a single probabilistic framework.
The authors adopt the variational auto‑encoder (VAE) paradigm. An encoder network qφ(z | a, ψ) maps the observed magnitude a and phase ψ of a single time frame to a low‑dimensional latent vector z (D = 32). Two decoders are then defined: a magnitude decoder pθ(a | z) that reconstructs the magnitude spectrum, and a phase decoder pθ(ψ | a, z) that reconstructs the phase conditioned on both the latent vector and the reconstructed magnitude. This three‑network architecture (encoder, magnitude decoder, phase decoder) is trained jointly in an unsupervised manner.
Statistical assumptions are explicit: magnitude values are modeled as Gaussian random variables with mean μmag and variance σ²mag, while phase values follow a von Mises distribution with mean μpha and concentration κpha. Moreover, the authors extend the von Mises modeling to the phase derivatives—group delay (GD) and instantaneous frequency (IF)—which are the finite differences of phase along the frequency and time axes, respectively. By treating GD and IF as additional von Mises‑distributed variables, the model enforces temporal‑frequency consistency of the phase field.
The loss function is composed of three main parts:
- Regularization (Lreg) – the KL divergence between the approximate posterior qφ(z | a, ψ) and a standard normal prior, encouraging the latent space to follow a unit Gaussian.
- Magnitude reconstruction (Lmag) – the negative log‑likelihood of the Gaussian magnitude model, augmented with a variance‑regularization term Lvar that penalizes large predicted variances, thereby focusing learning on accurate mean estimates.
- Phase‑related reconstruction (Lpha, Lgrd, Lifr) – negative log‑likelihoods of the von Mises distributions for phase, GD, and IF, respectively. The concentration parameters are not learned; instead they are set to a simple function of the predicted magnitude (κ = â + 1), which makes the phase error more influential when the magnitude is high.
Training proceeds in two stages. In the first stage, only the encoder and magnitude decoder are trained using Lreg + Lmag + Lvar, establishing a reliable magnitude prior. In the second stage, the phase decoder is introduced and the full loss LJ = LM + LP is minimized, where LP can be any combination of Lpha, Lgrd, and Lifr. This yields several model variants (J1–J7) corresponding to different loss compositions.
The network architecture is a fully convolutional design inspired by DenseNet and U‑Net. Dense blocks consist of four 2‑D convolutions with a growth rate of eight channels; transition blocks downsample or upsample the feature maps; a temporal block with dilated 1‑D convolutions captures dynamics along the time axis. The total parameter count is about 1.7 M, making the model relatively lightweight.
Experiments use clean speech from the CHiME‑4 corpus (16 kHz, 513 frequency bins after zero‑padding). Evaluation focuses on a reconstruction task: latent vectors are inferred from clean utterances, then used to synthesize the waveform via inverse STFT. Quality is measured by Mean Opinion Score (MOS) and Short‑Time Objective Intelligibility (STOI).
Results show that the baseline magnitude‑only model (M), which samples phase uniformly, yields low quality (MOS ≈ 1.96, STOI ≈ 0.69). Adding a phase loss (J2) dramatically improves MOS to 3.34 and STOI to 0.77. Models that incorporate GD loss (J3, J4) achieve MOS around 2.2–2.5 and STOI around 0.73–0.80. The best overall performance is obtained by a balanced combination of phase and GD losses (J5), reaching MOS ≈ 3.71 and STOI ≈ 0.79. Applying Griffin‑Lim as a post‑processing step (100 iterations) further raises MOS to about 4.0, confirming that the generated spectrograms are already close to a consistent STFT.
A key insight from the analysis is that accurate estimation of phase derivatives (GD, IF) contributes more to perceptual quality than precise phase values themselves. Models that optimize GD (or IF) tend to produce more coherent spectrograms, even if the raw phase error is larger. This suggests that enforcing TF‑domain smoothness via derivative constraints is an effective strategy for generative speech modeling.
The paper concludes that a VAE‑based joint magnitude‑phase model, equipped with appropriate probabilistic assumptions and derivative‑based losses, can generate high‑quality speech without separate phase reconstruction stages. Future directions include adaptive weighting of the derivative losses, learning concentration parameters, or integrating flow‑based or autoregressive components to model the full complex spectrogram distribution more directly.
Comments & Academic Discussion
Loading comments...
Leave a Comment