An Experimental Evaluation of Machine Learning Training on a Real Processing-in-Memory System
Training machine learning (ML) algorithms is a computationally intensive process, which is frequently memory-bound due to repeatedly accessing large training datasets. As a result, processor-centric systems (e.g., CPU, GPU) suffer from costly data movement between memory units and processing units, which consumes large amounts of energy and execution cycles. Memory-centric computing systems, i.e., with processing-in-memory (PIM) capabilities, can alleviate this data movement bottleneck. Our goal is to understand the potential of modern general-purpose PIM architectures to accelerate ML training. To do so, we (1) implement several representative classic ML algorithms (namely, linear regression, logistic regression, decision tree, K-Means clustering) on a real-world general-purpose PIM architecture, (2) rigorously evaluate and characterize them in terms of accuracy, performance and scaling, and (3) compare to their counterpart implementations on CPU and GPU. Our evaluation on a real memory-centric computing system with more than 2500 PIM cores shows that general-purpose PIM architectures can greatly accelerate memory-bound ML workloads, when the necessary operations and datatypes are natively supported by PIM hardware. For example, our PIM implementation of decision tree is $27\times$ faster than a state-of-the-art CPU version on an 8-core Intel Xeon, and $1.34\times$ faster than a state-of-the-art GPU version on an NVIDIA A100. Our K-Means clustering on PIM is $2.8\times$ and $3.2\times$ than state-of-the-art CPU and GPU versions, respectively. To our knowledge, our work is the first one to evaluate ML training on a real-world PIM architecture. We conclude with key observations, takeaways, and recommendations that can inspire users of ML workloads, programmers of PIM architectures, and hardware designers&architects of future memory-centric computing systems.
💡 Research Summary
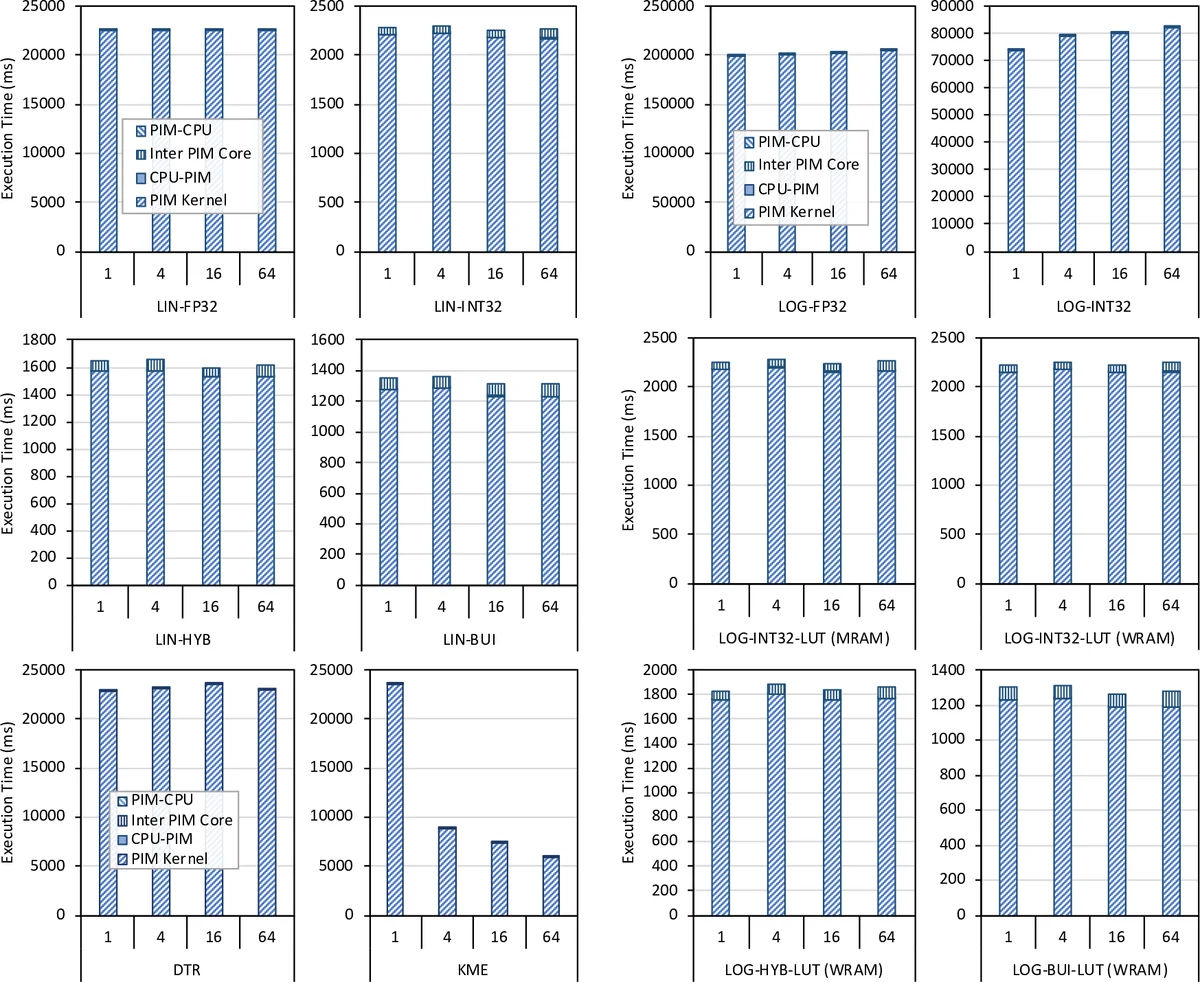
This paper presents a comprehensive experimental evaluation of machine‑learning (ML) training on a real, general‑purpose processing‑in‑memory (PIM) system. The authors target the UPMEM PIM architecture, which integrates 2,524 in‑order cores operating at 425 MHz alongside 158 GB of DDR4 memory. Four classic, memory‑bound ML algorithms are implemented: linear regression, logistic regression, decision tree, and K‑Means clustering. Because the UPMEM cores lack native floating‑point support, the implementations rely on fixed‑point representations, quantization to 8‑ or 16‑bit integers, and lookup‑table (LUT) approximations for non‑linear functions such as the sigmoid. Data layout is carefully arranged so that each core accesses its local memory bank in a streaming fashion, maximizing internal bandwidth and minimizing latency.
The authors benchmark their PIM implementations against state‑of‑the‑art CPU (8‑core Intel Xeon) and GPU (NVIDIA A100) baselines using identical datasets and hyper‑parameters. Results show dramatic speedups for memory‑intensive workloads: decision‑tree training on PIM is 27×–113× faster than the CPU and 1.34×–4.5× faster than the GPU; K‑Means achieves 2.8× (CPU) and 3.2× (GPU) speedups; linear and logistic regression obtain 4×–6× improvements. Accuracy is preserved; fixed‑point and quantized models match the floating‑point baselines within statistical noise. Scaling experiments demonstrate near‑linear performance gains as the number of PIM cores and memory capacity increase, while host‑PIM communication overhead remains below 5 % of total runtime.
Beyond raw numbers, the paper extracts several design insights: (1) memory‑bound ML workloads benefit from fixed‑point data, quantization, and hybrid‑precision schemes when floating‑point units are unavailable; (2) LUTs are preferable to polynomial approximations for complex functions on PIM; (3) arranging data for streaming accesses fully exploits the high internal bandwidth of PIM; (4) large training datasets can stay resident in PIM‑enabled memory throughout training, eliminating costly host‑memory transfers. The authors also discuss limitations, noting that deep‑learning training remains better suited to GPUs due to high arithmetic intensity, and that current PIM hardware lacks specialized accelerators for such workloads.
The paper concludes with recommendations for three audiences: ML practitioners should consider PIM for workloads that are memory‑bound and tolerant of reduced precision; PIM programmers should adopt fixed‑point, quantization, and LUT techniques; hardware designers are encouraged to add native floating‑point SIMD units, richer instruction sets, and higher clock frequencies to broaden the class of accelerable algorithms. All code, datasets, and evaluation scripts are open‑sourced on GitHub. In sum, this work provides the first real‑world evidence that general‑purpose PIM architectures can substantially accelerate classic ML training, offering a compelling alternative to traditional CPU/GPU platforms for data‑movement‑limited applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment