Algorithms to estimate Shapley value feature attributions
Feature attributions based on the Shapley value are popular for explaining machine learning models; however, their estimation is complex from both a theoretical and computational standpoint. We disentangle this complexity into two factors: (1)~the approach to removing feature information, and (2)~the tractable estimation strategy. These two factors provide a natural lens through which we can better understand and compare 24 distinct algorithms. Based on the various feature removal approaches, we describe the multiple types of Shapley value feature attributions and methods to calculate each one. Then, based on the tractable estimation strategies, we characterize two distinct families of approaches: model-agnostic and model-specific approximations. For the model-agnostic approximations, we benchmark a wide class of estimation approaches and tie them to alternative yet equivalent characterizations of the Shapley value. For the model-specific approximations, we clarify the assumptions crucial to each method’s tractability for linear, tree, and deep models. Finally, we identify gaps in the literature and promising future research directions.
💡 Research Summary
The paper presents a comprehensive taxonomy and evaluation of algorithms that estimate Shapley‑value based feature attributions. It identifies two fundamental sources of complexity: (1) how to “remove” a feature (the feature‑removal strategy) and (2) how to compute or approximate the Shapley values tractably (the estimation strategy). By combining these two dimensions, the authors classify 24 distinct algorithms, covering both model‑agnostic and model‑specific approaches.
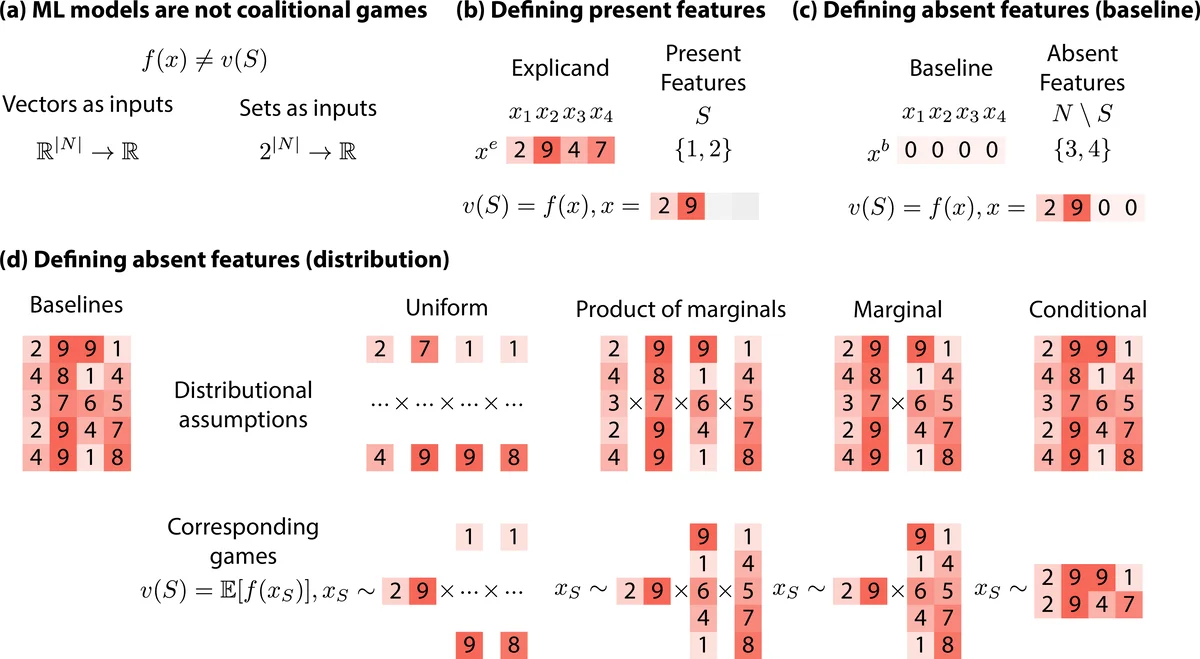
For feature removal, the authors discuss baseline substitution (single baseline, multiple baselines, uniform, marginal, conditional) and illustrate how the choice of baseline dramatically influences the resulting attributions, even for simple linear models. They emphasize that baseline selection is often arbitrary and can lead to inconsistent explanations.
On the estimation side, model‑agnostic methods such as KernelSHAP, Permutation SHAP, FastSHAP, and multilinear extensions are examined. The paper shows that these methods are mathematically equivalent to alternative definitions of the Shapley value and compares their convergence rates, variance, and computational cost through extensive experiments.
Model‑specific methods exploit structural properties of particular learners. LinearSHAP directly uses regression coefficients; TreeSHAP leverages tree paths to achieve exact O(td) computation; DeepSHAP combines DeepLIFT with Shapley concepts to provide fast approximations for deep networks, albeit with limitations in capturing higher‑order interactions. The authors clarify the assumptions each method relies on (e.g., feature independence, tree monotonicity).
Finally, the survey identifies gaps: lack of principled guidelines for baseline choice, insufficient techniques for efficiently estimating high‑order interactions, and the need for more sample‑efficient model‑agnostic algorithms. The authors propose future research directions, including automated baseline generation, interaction‑aware Shapley extensions, and hybrid approaches that blend model‑agnostic sampling with model‑specific shortcuts. Overall, the paper serves as a detailed reference for practitioners seeking to select appropriate Shapley‑value estimators and for researchers aiming to advance the state of the art in explainable AI.
Comments & Academic Discussion
Loading comments...
Leave a Comment