Role of non-linear data processing on speech recognition task in the framework of reservoir computing
The reservoir computing neural network architecture is widely used to test hardware systems for neuromorphic computing. One of the preferred tasks for bench-marking such devices is automatic speech recognition. However, this task requires acoustic transformations from sound waveforms with varying amplitudes to frequency domain maps that can be seen as feature extraction techniques. Depending on the conversion method, these may obscure the contribution of the neuromorphic hardware to the overall speech recognition performance. Here, we quantify and separate the contributions of the acoustic transformations and the neuromorphic hardware to the speech recognition success rate. We show that the non-linearity in the acoustic transformation plays a critical role in feature extraction. We compute the gain in word success rate provided by a reservoir computing device compared to the acoustic transformation only, and show that it is an appropriate benchmark for comparing different hardware. Finally, we experimentally and numerically quantify the impact of the different acoustic transformations for neuromorphic hardware based on magnetic nano-oscillators.
💡 Research Summary
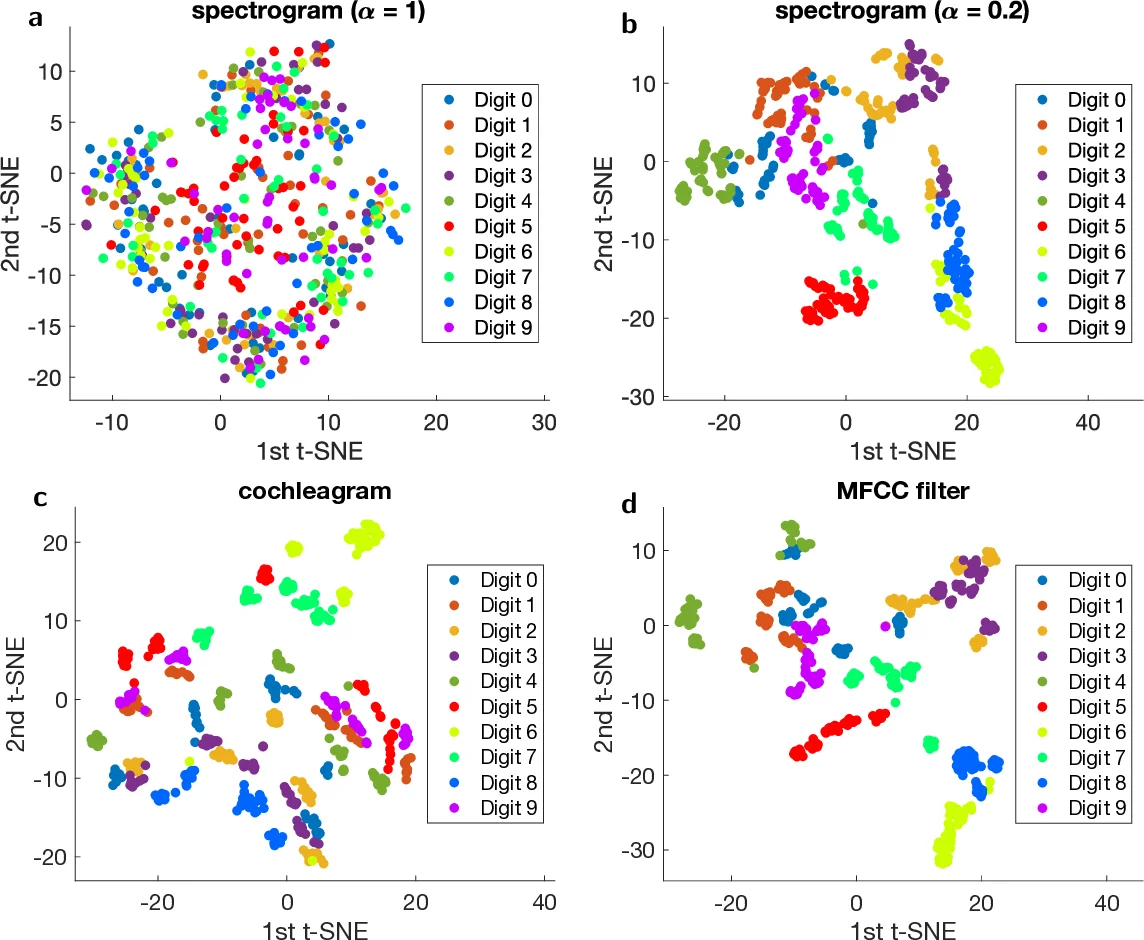
The paper investigates how much of the success in automatic speech recognition (ASR) tasks can be attributed to acoustic preprocessing versus the contribution of a neuromorphic reservoir‑computing (RC) hardware platform based on magnetic nano‑oscillators. Four distinct time‑frequency transforms are examined: (i) a biologically inspired cochleagram (78 channels) that incorporates automatic‑gain‑control non‑linearity, (ii) Mel‑frequency cepstral coefficients (MFCC, 13 channels) with a log‑energy non‑linearity, (iii) a purely linear spectrogram (65 channels) obtained by short‑time Fourier transforms, and (iv) a deliberately non‑linear “Spectro HP” transform, defined as |sin p|·Re(Spectro)+|cos p|·Im(Spectro).
Using the TI‑46 spoken‑digit dataset (500 utterances: 5 speakers × 10 digits × 10 repetitions), the authors first evaluate each preprocessing method in isolation, i.e., feeding the transformed features directly to a linear classifier (no reservoir). The cochleagram attains a word‑success‑rate (WSR) of 95.8 % (with 9 training utterances per digit), Spectro HP reaches 89.0 %, and MFCC obtains 77.2 %. In stark contrast, the linear spectrogram yields only ~10 %—essentially random guessing. This demonstrates that the non‑linear character of the transform is the dominant factor enabling effective feature extraction for ASR.
The second stage introduces a reservoir implemented with a single spin‑torque nano‑oscillator (STNO) that is time‑multiplexed into 400 virtual neurons. Input vectors are flattened, multiplied by a random binary mask (±1), and injected into the STNO, whose intrinsic non‑linear dynamics perform a further mapping into a high‑dimensional state space. Output weights are trained by a closed‑form Moore‑Penrose pseudo‑inverse solution; no regularisation is applied.
When the reservoir is added, the linear spectrogram’s performance jumps from ~10 % to ~88 % WSR, confirming that the reservoir’s non‑linear dynamics can compensate for the lack of non‑linearity in the preprocessing stage. Conversely, for the already powerful non‑linear cochleagram and MFCC, the reservoir contributes only marginal gains (≈0.5–2 %). The authors quantify this as a “gain” metric: gain = WSR_reservoir − WSR_acoustic. Gains are ≈78 % for the linear spectrogram, but <2 % for the cochleagram and MFCC.
Experimental validation is performed with an actual magnetic nano‑oscillator fabricated on a CMOS‑compatible platform. Measured reservoir responses match numerical simulations closely, reproducing the same gain patterns observed in software. This confirms that the STNO‑based reservoir is a realistic hardware substrate for neuromorphic computing.
The paper’s key insights are: (1) non‑linear acoustic feature extraction is the primary driver of ASR performance; (2) neuromorphic reservoirs provide substantial benefit only when the preprocessing is linear or weakly non‑linear; (3) the contribution of the reservoir can be cleanly isolated by comparing against the acoustic‑only baseline, offering a principled benchmark for future neuromorphic hardware; and (4) magnetic nano‑oscillator reservoirs can be reliably modeled and experimentally realized, making them viable candidates for low‑power, high‑speed speech‑recognition accelerators. The work thus reframes how the community should evaluate neuromorphic ASR systems, emphasizing the need to report both acoustic‑only and hardware‑augmented results.
Comments & Academic Discussion
Loading comments...
Leave a Comment