Sustainable AI Processing at the Edge
📝 Abstract
Edge computing is a popular target for accelerating machine learning algorithms supporting mobile devices without requiring the communication latencies to handle them in the cloud. Edge deployments of machine learning primarily consider traditional concerns such as SWaP constraints (Size, Weight, and Power) for their installations. However, such metrics are not entirely sufficient to consider environmental impacts from computing given the significant contributions from embodied energy and carbon. In this paper we explore the tradeoffs of convolutional neural network acceleration engines for both inference and on-line training. In particular, we explore the use of processing-in-memory (PIM) approaches, mobile GPU accelerators, and recently released FPGAs, and compare them with novel Racetrack memory PIM. Replacing PIM-enabled DDR3 with Racetrack memory PIM can recover its embodied energy as quickly as 1 year. For high activity ratios, mobile GPUs can be more sustainable but have higher embodied energy to overcome compared to PIM-enabled Racetrack memory.
💡 Analysis
Edge computing is a popular target for accelerating machine learning algorithms supporting mobile devices without requiring the communication latencies to handle them in the cloud. Edge deployments of machine learning primarily consider traditional concerns such as SWaP constraints (Size, Weight, and Power) for their installations. However, such metrics are not entirely sufficient to consider environmental impacts from computing given the significant contributions from embodied energy and carbon. In this paper we explore the tradeoffs of convolutional neural network acceleration engines for both inference and on-line training. In particular, we explore the use of processing-in-memory (PIM) approaches, mobile GPU accelerators, and recently released FPGAs, and compare them with novel Racetrack memory PIM. Replacing PIM-enabled DDR3 with Racetrack memory PIM can recover its embodied energy as quickly as 1 year. For high activity ratios, mobile GPUs can be more sustainable but have higher embodied energy to overcome compared to PIM-enabled Racetrack memory.
📄 Content
엣지 컴퓨팅은 모바일 디바이스가 필요로 하는 머신러닝 알고리즘을 가속화하기 위한 매우 인기 있는 목표이며, 이러한 알고리즘을 클라우드에 올려서 처리할 때 발생하는 통신 지연(latency)을 감수하지 않아도 된다는 점에서 큰 장점을 가지고 있다. 전통적으로 엣지 환경에 머신러닝을 배치할 때는 설치 공간, 무게, 전력 소비를 의미하는 SWaP(Size, Weight, and Power) 제약을 가장 중요한 설계 요소로 고려한다. 이러한 SWaP 제약은 실제 디바이스가 제한된 배터리 용량과 물리적 크기 안에서 원활히 동작하도록 보장하는 데 필수적이다.
하지만 SWaP만으로는 컴퓨팅 시스템이 환경에 미치는 전체적인 영향을 충분히 평가할 수 없다. 특히 현대의 전자 시스템은 제조 과정에서 발생하는 내재 에너지(embodied energy)와 탄소 배출량이 전체 환경 부담의 상당 부분을 차지한다는 연구 결과가 늘어나고 있다. 따라서 엣지에서 사용되는 가속기와 메모리 기술을 선택할 때는 단순히 성능이나 전력 효율만을 따지는 것이 아니라, 해당 장치가 생산·수송·폐기 단계에서 소비하는 에너지와 배출하는 이산화탄소 양도 함께 고려해야 한다.
본 논문에서는 이러한 관점을 바탕으로 컨볼루션 신경망(Convolutional Neural Network, CNN) 가속 엔진을 추론(inference)과 온라인 학습(on‑line training) 두 가지 워크로드에 적용했을 때 나타나는 트레이드오프를 체계적으로 탐구한다. 구체적으로는 세 가지 주요 기술 경로를 선정하였다. 첫 번째는 처리‑인‑메모리(Processing‑in‑Memory, PIM) 접근법으로, 메모리 내부에서 연산을 수행함으로써 데이터 이동을 최소화하고 에너지 효율을 크게 향상시킬 수 있다. 두 번째는 모바일 GPU 가속기이며, 최신 모바일 SoC(System on Chip)에서 제공되는 고성능 그래픽 처리 유닛을 활용해 병렬 연산을 빠르게 수행한다. 세 번째는 최근 시장에 출시된 FPGA(Field‑Programmable Gate Array)로, 하드웨어 레벨에서 사용자 정의 회로를 구현함으로써 특정 알고리즘에 최적화된 가속을 가능하게 한다.
이와 별도로, 최신 연구에서 제안된 레이스트랙 메모리(Racetrack memory) 기반 PIM 솔루션을 새로운 비교 대상으로 도입하였다. 레이스트랙 메모리는 전통적인 DRAM이나 SRAM과 달리 자기 도메인(domain)을 이동시켜 데이터를 저장·읽기·쓰기를 수행하는 구조로, 높은 저장 밀도와 낮은 접근 전력을 동시에 제공한다. 특히 PIM 기능이 내장된 형태로 구현될 경우, 메모리와 연산 유닛 사이의 인터페이스 비용을 거의 없앨 수 있어 전체 시스템의 에너지 회수 속도가 크게 빨라진다.
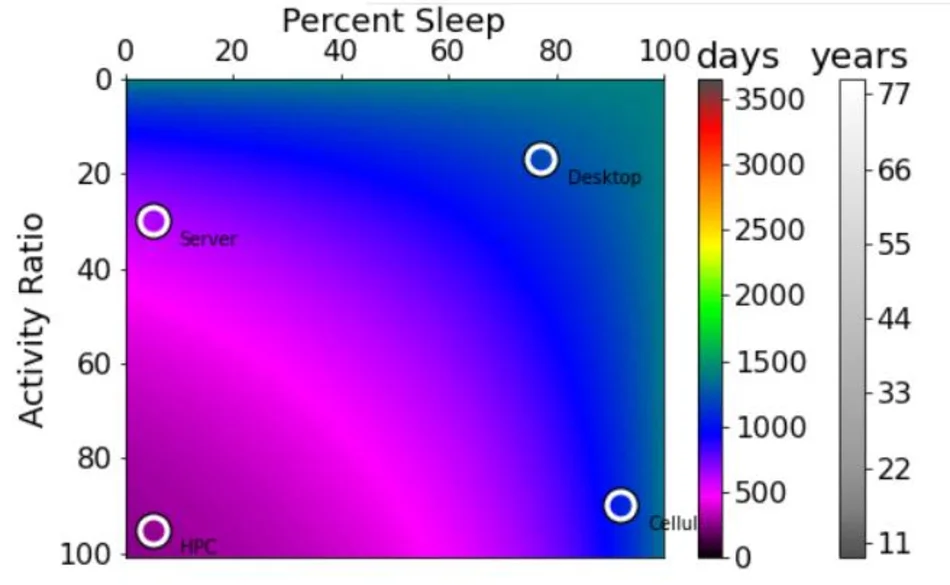
실험 결과에 따르면, 기존의 PIM 기능이 탑재된 DDR3 메모리를 레이스트랙 메모리 PIM으로 교체했을 때, 해당 메모리가 제조 과정에서 소비한 내재 에너지를 약 1년이라는 짧은 기간 안에 회수할 수 있었다. 이는 레이스트랙 메모리의 높은 데이터 접근 효율과 낮은 유지 전력 덕분에 가능한 일이며, 장기적인 관점에서 보면 탄소 발자국을 크게 감소시킬 수 있는 잠재력을 보여준다.
한편, 시스템이 높은 활동 비율(high activity ratio), 즉 연산이 지속적으로 빈번하게 발생하는 상황에서는 모바일 GPU 가속기가 더 지속 가능한 선택이 될 수 있다. 모바일 GPU는 높은 연산 처리량과 비교적 낮은 실행 시간 덕분에 단위 작업당 에너지 소비를 최소화한다. 그러나 이러한 장점에도 불구하고, 모바일 GPU 자체가 제조 단계에서 상당한 양의 내재 에너지를 필요로 하며, 따라서 PIM 기반 레이스트랙 메모리와 비교했을 때 초기 에너지 부채(embodied energy debt)를 극복하는 데 더 오랜 시간이 소요된다.
요약하면, 엣지 컴퓨팅 환경에서 머신러닝 가속기를 선택할 때는 단순히 성능·전력·크기·무게와 같은 전통적인 SWaP 요소뿐만 아니라, 해당 장치가 전체 수명 주기 동안 소비하는 내재 에너지와 배출하는 탄소량을 종합적으로 평가해야 한다는 점을 강조한다. 본 연구는 PIM‑기반 레이스트랙 메모리가 높은 에너지 회수 속도와 낮은 탄소 배출 특성으로 인해, 특히 장기적인 지속 가능성을 목표로 하는 엣지 애플리케이션에 매우 유망한 후보임을 입증한다. 동시에, 작업 부하가 매우 활발하고 실시간 응답성이 중요한 경우에는 모바일 GPU 가속기가 여전히 경쟁력 있는 옵션이 될 수 있음을 보여준다. 이러한 결과는 향후 엣지 AI 시스템 설계 시 환경 영향을 최소화하면서도 필요한 성능을 달성하기 위한 기술 선택에 중요한 지침을 제공한다.