Regression of exchangeable relational arrays
Relational arrays represent measures of association between pairs of actors, often in varied contexts or over time. Trade flows between countries, financial transactions between individuals, contact frequencies between school children in classrooms, and dynamic protein-protein interactions are all examples of relational arrays. Elements of a relational array are often modeled as a linear function of observable covariates. Uncertainty estimates for regression coefficient estimators – and ideally the coefficient estimators themselves – must account for dependence between elements of the array (e.g. relations involving the same actor) and existing estimators of standard errors that recognize such relational dependence rely on estimating extremely complex, heterogeneous structure across actors. This paper develops a new class of parsimonious coefficient and standard error estimators for regressions of relational arrays. We leverage an exchangeability assumption to derive standard error estimators that pool information across actors and are substantially more accurate than existing estimators in a variety of settings. This exchangeability assumption is pervasive in network and array models in the statistics literature, but not previously considered when adjusting for dependence in a regression setting with relational data. We demonstrate improvements in inference theoretically, via a simulation study, and by analysis of a data set involving international trade.
💡 Research Summary
The paper addresses statistical inference for regression models built on relational arrays—datasets that record pairwise interactions among actors across multiple contexts or time periods (e.g., international trade flows, financial transfers, classroom contacts, protein‑protein interactions). A standard linear specification y_{ij}^{r}=β^{T}x_{ij}^{r}+ξ_{ij}^{r} is considered, where the error terms ξ exhibit dependence whenever they share an actor. Ignoring this dependence leads to biased coefficient estimates and misleading significance tests.
Two families of existing solutions are reviewed. The first imposes parametric structures on the error covariance (latent‑variable models, random‑effects specifications) and typically requires Bayesian MCMC, which can be computationally intensive and sensitive to model misspecification. The second, often called dyadic clustering (DC), estimates the covariance empirically from regression residuals, assuming that any two dyads that do not share an actor are independent. While DC yields a sandwich variance estimator that is asymptotically consistent under very general dependence, it must estimate O(R^{2}n^{3}) distinct covariance elements from only O(R^{2}n^{2}) observations, resulting in high variability and, paradoxically, an anticonservative bias.
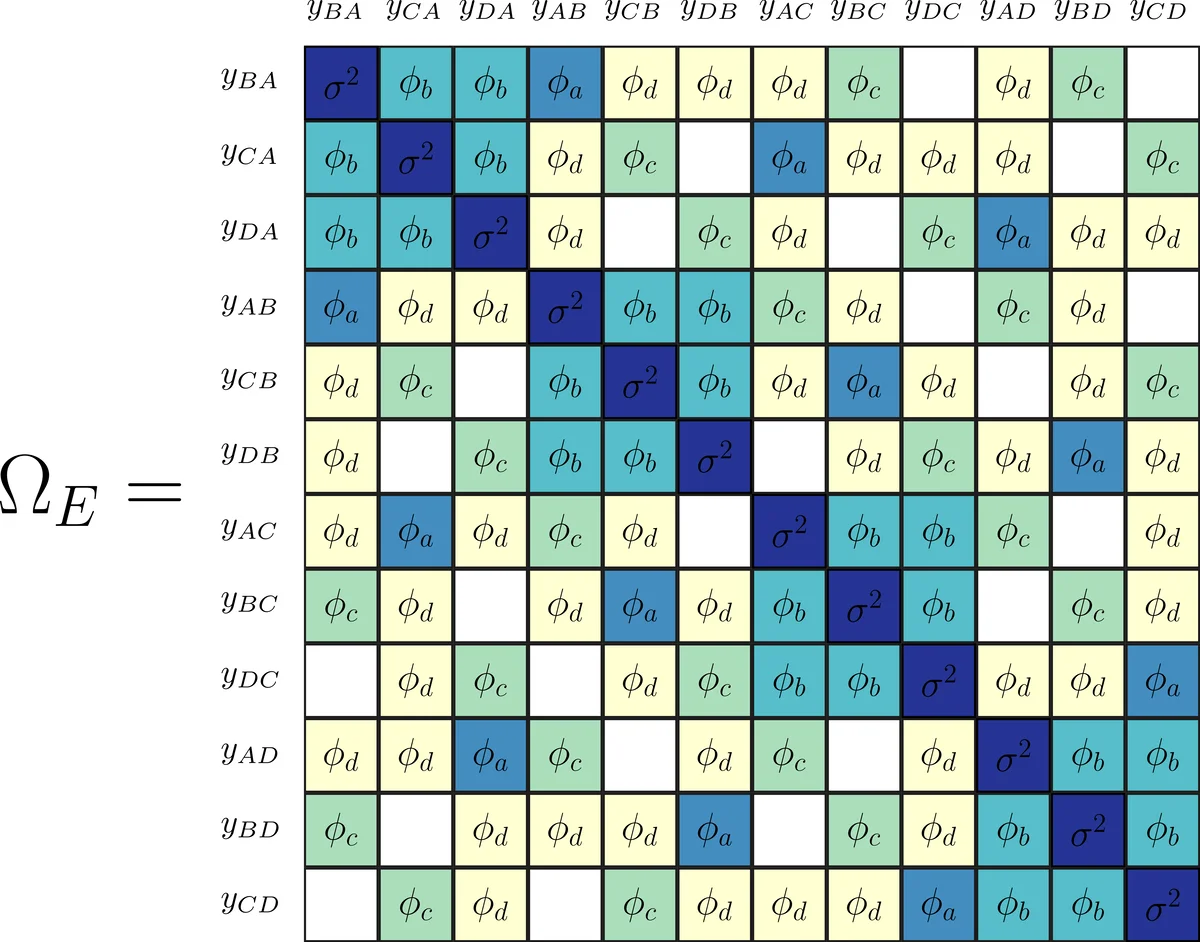
The authors propose a new approach that leverages exchangeability—a symmetry assumption stating that the joint distribution of the error array is invariant under simultaneous permutations of rows, columns, and the third dimension (contexts or time). Under exchangeability, the covariance matrix Ω of the vectorized errors contains at most twelve distinct entries (six when R=1). By further imposing that non‑overlapping dyads are independent, the structure reduces to ten free parameters, grouped into two blocks (same‑context vs. different‑context).
A parsimonious estimator Ω̂_E is constructed by averaging products of residuals that share the same index configuration (the ten patterns shown in Figure 1 of the paper). This estimator can be viewed as the orthogonal projection of the full dyadic‑clustering estimator Ω̂_DC onto the subspace defined by exchangeability. The resulting variance estimator V̂_E = (X^{T}X)^{-1} X^{T} Ω̂_E X (X^{T}X)^{-1} is shown to be consistent and asymptotically more efficient than the DC counterpart whenever exchangeability holds.
Theoretical contributions include: (1) a proof that any jointly exchangeable relational error array yields a covariance matrix with at most twelve unique values (Proposition 1); (2) a bias analysis demonstrating that the DC variance estimator is downward‑biased, with bias at least twice the magnitude of the bias of the exchangeable estimator (Theorem 2); (3) asymptotic normality of the OLS estimator under exchangeability and consistency of V̂_E.
Simulation studies vary sample size (n=20 to 320), number of contexts (R=1), and covariate types (binary, positive real, unrestricted real). When errors are generated from an exchangeable model, V̂_E achieves coverage rates close to the nominal 95 % level across all covariates, while DC often under‑covers, especially for the binary covariate where signal‑to‑noise is low. Under non‑exchangeable errors, both methods lose some accuracy, but V̂_E remains more stable.
An empirical application to a multi‑year, multi‑sector international trade dataset illustrates practical gains. Using the exchangeable estimator yields smaller standard errors and more precise coefficient estimates compared with DC, facilitating clearer policy interpretation.
All methods are implemented in the R package netregR, and reproducible code is provided on GitHub (https://github.com/fmarrs3/netreg_public).
In summary, by imposing a modest symmetry assumption that is already implicit in many latent‑variable network models, the authors derive a highly parsimonious covariance estimator that dramatically improves inference for relational array regressions. The approach retains the robustness of empirical (sandwich) methods while eliminating the high variance and anticonservatism of traditional dyadic clustering, offering a valuable tool for researchers working with dependent dyadic data.
Comments & Academic Discussion
Loading comments...
Leave a Comment