A Degeneracy Framework for Scalable Graph Autoencoders
In this paper, we present a general framework to scale graph autoencoders (AE) and graph variational autoencoders (VAE). This framework leverages graph degeneracy concepts to train models only from a dense subset of nodes instead of using the entire graph. Together with a simple yet effective propagation mechanism, our approach significantly improves scalability and training speed while preserving performance. We evaluate and discuss our method on several variants of existing graph AE and VAE, providing the first application of these models to large graphs with up to millions of nodes and edges. We achieve empirically competitive results w.r.t. several popular scalable node embedding methods, which emphasizes the relevance of pursuing further research towards more scalable graph AE and VAE.
💡 Research Summary
The paper addresses the long‑standing scalability bottleneck of graph autoencoders (GAE) and variational graph autoencoders (VGAE), whose training and decoding costs grow quadratically with the number of nodes. The authors propose a two‑stage “degeneracy framework” that dramatically reduces both memory consumption and runtime while preserving the quality of the learned embeddings.
In the first stage, the graph is decomposed into its k‑core hierarchy using a linear‑time algorithm (O(max(m,n))). A k‑core is the maximal subgraph in which every node has degree at least k; the degeneracy δ∗(G) is the largest k for which the k‑core is non‑empty. By selecting a suitable k (typically k = 2 or 3 for large graphs), the authors retain a dense “core” that contains only a small fraction (often <5 %) of the original nodes but captures the most structurally important part of the network. The GAE or VGAE model—any encoder such as a GCN, GraphSAGE, Chebyshev GNN, or GAT, and a standard inner‑product decoder—is then trained only on this core subgraph. Consequently, the expensive O(n²) decoder multiplication and the GNN forward/backward passes are performed on a dramatically smaller graph, yielding speed‑ups of 8–12× and memory reductions of over 70 % in the authors’ experiments.
The second stage deals with the remaining peripheral nodes. Since the graph is assumed featureless (X = I) in this stage, the only information available is topology. The authors introduce a simple propagation heuristic: nodes directly adjacent to the core receive the average (or weighted average) of the embeddings of their already‑embedded neighbors; this process is iterated outward, allowing embeddings to “flow” from the core to the periphery. The propagation respects mutual connections among newly embedded nodes, which empirically improves stability and downstream performance. This step runs in linear time and requires no additional learnable parameters.
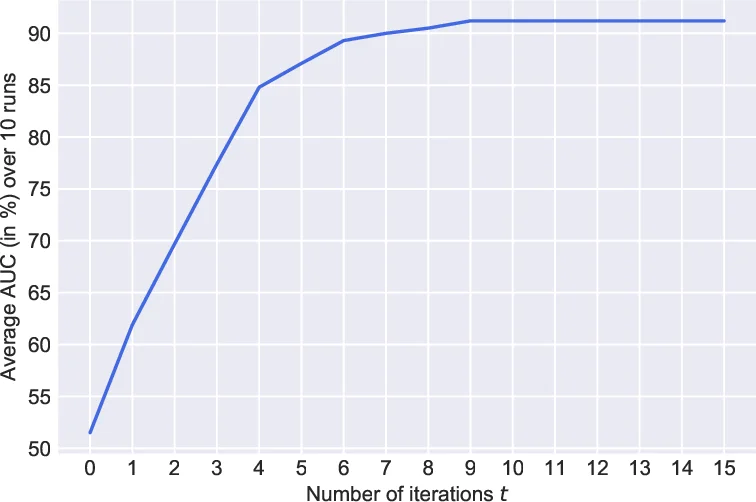
Empirical evaluation covers ten variants of GAE/VGAE across two representative tasks—link prediction and node clustering—on both medium‑size citation graphs (Cora, Citeseer, Pubmed) and massive real‑world networks (Reddit, Amazon, ogbn‑products) containing up to millions of nodes and edges. Compared with classic scalable embedding methods such as DeepWalk, node2vec, and LINE, the degenerate models achieve comparable or slightly superior AUC, AP, and F1 scores while being far more efficient. The authors also analyze the trade‑off between the chosen k and performance: higher k yields faster training but risks discarding too much structural information, whereas lower k retains performance at the cost of reduced speed gains. Their experiments suggest that k = 2 (removing leaves) offers a sweet spot for most large graphs.
Importantly, the framework is encoder‑agnostic; the authors demonstrate that more expressive GNNs (e.g., spectral Chebyshev filters, attention‑based GAT) can be plugged into the same pipeline without breaking scalability. This flexibility opens the door to future research on powerful graph autoencoders that were previously infeasible on large networks.
In summary, the paper introduces a practical, theoretically grounded method to scale graph autoencoders to industrial‑scale graphs. By training on a carefully selected k‑core and propagating embeddings outward, it achieves dramatic reductions in computational cost while maintaining state‑of‑the‑art embedding quality, thereby making GAE/VGAE viable for a wide range of large‑scale graph learning applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment