BRIDGE: Byzantine-resilient Decentralized Gradient Descent
Machine learning has begun to play a central role in many applications. A multitude of these applications typically also involve datasets that are distributed across multiple computing devices/machines due to either design constraints (e.g., multiagent systems) or computational/privacy reasons (e.g., learning on smartphone data). Such applications often require the learning tasks to be carried out in a decentralized fashion, in which there is no central server that is directly connected to all nodes. In real-world decentralized settings, nodes are prone to undetected failures due to malfunctioning equipment, cyberattacks, etc., which are likely to crash non-robust learning algorithms. The focus of this paper is on robustification of decentralized learning in the presence of nodes that have undergone Byzantine failures. The Byzantine failure model allows faulty nodes to arbitrarily deviate from their intended behaviors, thereby ensuring designs of the most robust of algorithms. But the study of Byzantine resilience within decentralized learning, in contrast to distributed learning, is still in its infancy. In particular, existing Byzantine-resilient decentralized learning methods either do not scale well to large-scale machine learning models, or they lack statistical convergence guarantees that help characterize their generalization errors. In this paper, a scalable, Byzantine-resilient decentralized machine learning framework termed Byzantine-resilient decentralized gradient descent (BRIDGE) is introduced. Algorithmic and statistical convergence guarantees for one variant of BRIDGE are also provided in the paper for both strongly convex problems and a class of nonconvex problems. In addition, large-scale decentralized learning experiments are used to establish that the BRIDGE framework is scalable and it delivers competitive results for Byzantine-resilient convex and nonconvex learning.
💡 Research Summary
The paper addresses a critical gap in decentralized machine learning: how to train models when a subset of participating nodes behave arbitrarily (Byzantine failures) and there is no central server to coordinate updates. Existing Byzantine‑resilient works focus largely on the parameter‑server or federated learning settings, and the few decentralized approaches either scale poorly (e.g., coordinate‑descent based ByRDiE) or lack rigorous statistical guarantees.
BRIDGE (Byzantine‑resilient decentralized gradient descent) is introduced as a scalable framework that retains the simplicity of gradient‑descent updates while incorporating a robust “screening” step to filter out malicious contributions. In each iteration every honest node computes its local d‑dimensional gradient and broadcasts its current model vector to its immediate neighbors. Upon receiving the set of neighbor models, a node applies a robust aggregation rule—such as trimmed‑mean, median, or other outlier‑resistant operators—to discard the most extreme β‑fraction of values (where β bounds the proportion of Byzantine nodes). The aggregated model is then used in a standard gradient‑descent update. Because each node exchanges only one model vector (and optionally its gradient) per round, the communication cost is O(d) per iteration, a dramatic improvement over ByRDiE’s O(d²) pattern that required d separate coordinate updates.
The authors focus on one concrete variant, BRIDGE‑T (trimmed‑mean based), and provide two families of theoretical results. For strongly convex, L‑smooth loss functions, they prove linear convergence of the iterates to the global optimum, matching the rates of the best known Byzantine‑resilient distributed algorithms. For a class of non‑convex but σ‑smooth objectives (including typical deep‑network losses), they establish a sub‑linear O(1/√T) bound on the expected optimality gap after T iterations, under a fixed stepsize and the same β‑screening condition. Moreover, they derive sample‑complexity (statistical) guarantees: the empirical risk minimizer obtained by the honest nodes converges to the true risk at a rate O(1/ε²), showing that the presence of Byzantine nodes does not inflate the number of samples needed for a given generalization error.
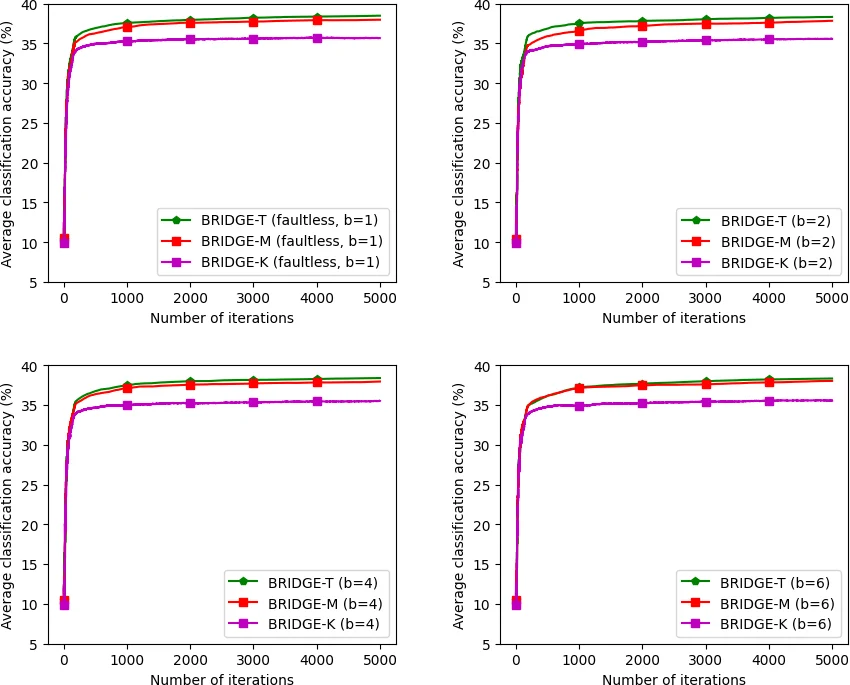
Experimental validation is performed on MNIST (logistic regression) and CIFAR‑10 (small convolutional network) with up to 200 nodes. Byzantine nodes are injected at rates of 10‑30 % and employ diverse attack strategies (random Gaussian noise, sign‑flipped models, scaled malicious updates). BRIDGE‑T maintains high accuracy—≈98 % on MNIST and ≈80 % on CIFAR‑10—even with 30 % Byzantine presence, while competing methods suffer noticeable degradation (10‑15 % accuracy loss). Communication measurements confirm that BRIDGE‑T transmits roughly 1/d of the data per round compared with prior decentralized schemes, enabling practical training of models with hundreds of thousands of parameters.
In summary, the contributions are threefold: (1) a novel decentralized gradient‑descent framework that is provably resilient to Byzantine attacks while keeping per‑iteration computation and communication linear in model dimension; (2) rigorous algorithmic and statistical convergence analyses for both convex and a meaningful class of non‑convex objectives; (3) extensive empirical evidence that the method scales to realistic deep‑learning workloads and outperforms existing Byzantine‑resilient decentralized algorithms. The paper also outlines future directions, including asynchronous updates, time‑varying network topologies, higher Byzantine fractions, and integration with differential privacy for stronger privacy guarantees.
Comments & Academic Discussion
Loading comments...
Leave a Comment