A Unified Approach to Reinforcement Learning, Quantal Response Equilibria, and Two-Player Zero-Sum Games
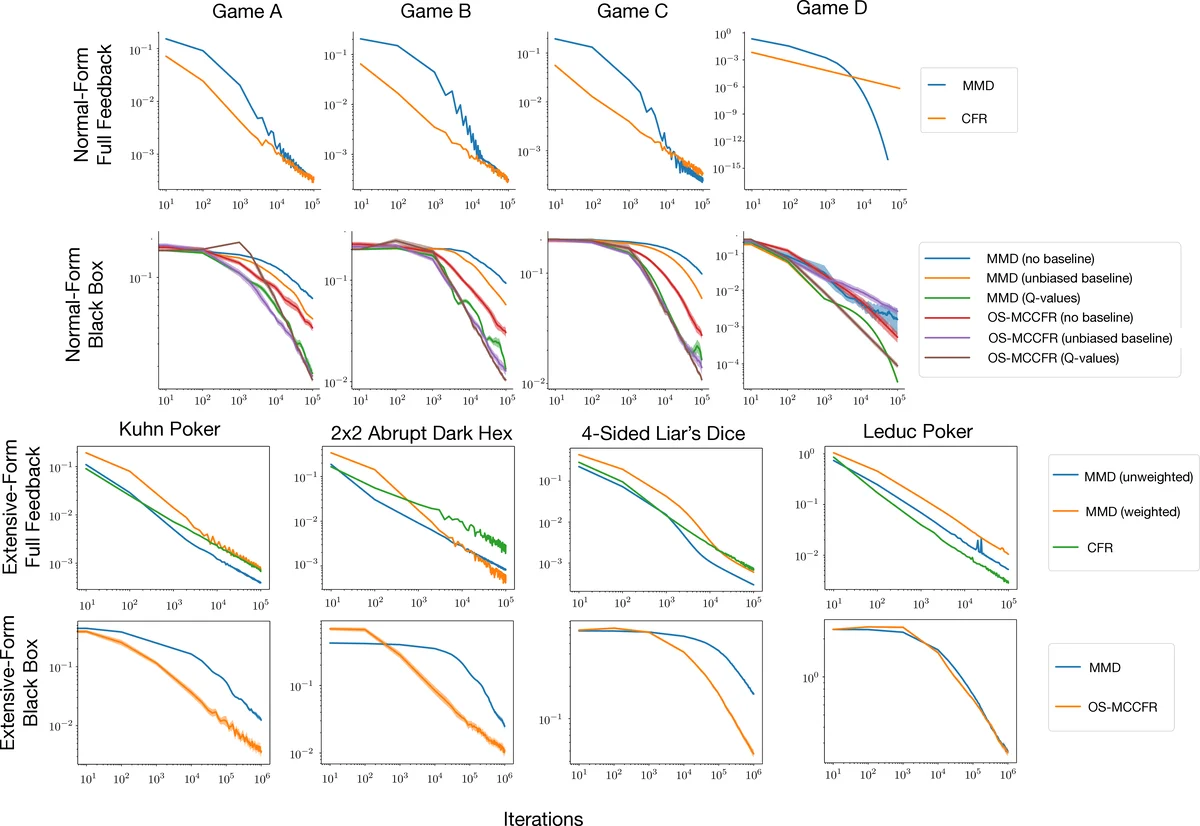
This work studies an algorithm, which we call magnetic mirror descent, that is inspired by mirror descent and the non-Euclidean proximal gradient algorithm. Our contribution is demonstrating the virtues of magnetic mirror descent as both an equilibrium solver and as an approach to reinforcement learning in two-player zero-sum games. These virtues include: 1) Being the first quantal response equilibria solver to achieve linear convergence for extensive-form games with first order feedback; 2) Being the first standard reinforcement learning algorithm to achieve empirically competitive results with CFR in tabular settings; 3) Achieving favorable performance in 3x3 Dark Hex and Phantom Tic-Tac-Toe as a self-play deep reinforcement learning algorithm.
💡 Research Summary
The paper introduces Magnetic Mirror Descent (MMD), a novel algorithm that unifies reinforcement learning, quantal response equilibrium (QRE) computation, and two‑player zero‑sum game solving. Building on mirror descent and the non‑Euclidean proximal gradient method, the authors first recast the regularized min‑max problem of a zero‑sum game as a variational inequality (VI) with a composite operator G = F + α∇g. Here F captures the smooth bilinear payoff term, while g represents entropy‑type regularization. Under standard assumptions—ψ is 1‑strongly convex, F is monotone and L‑smooth, and g is relatively strongly convex with respect to ψ—the paper proves a new linear‑convergence theorem (Theorem 3.4) for the general VI algorithm (Algorithm 3.1). The step‑size condition η < α/L² guarantees that the Bregman distance to the unique solution shrinks geometrically.
Specializing this framework to two‑player games yields MMD, where each player updates its strategy by solving a proximal problem that pulls the current iterate toward a “magnet” (either a fixed reference policy or the current iterate itself) while simultaneously performing a gradient ascent/descent on the opponent’s payoff. When ψ is negative entropy, the update reduces to a KL‑regularized policy improvement step that exactly matches the logit QRE fixed‑point condition. Consequently, in both normal‑form and extensive‑form games, simultaneous MMD updates converge exponentially fast to the α‑QRE (or the behavioral A‑QRE when using action‑value feedback).
Empirically, the authors validate the theory on synthetic normal‑form and sequence‑form games, confirming linear convergence to QREs. They then demonstrate that, as a standard reinforcement‑learning algorithm, MMD attains performance comparable to Counterfactual Regret Minimization (CFR) in tabular self‑play benchmarks—a first for a conventional RL method. Finally, deep multi‑agent experiments on 3×3 Dark Hex and Phantom Tic‑Tac‑Toe show that MMD can be integrated with neural policy networks, successfully reducing exploitability and achieving competitive results.
Overall, the work provides (1) the first first‑order method with linear convergence guarantees for QREs in extensive‑form games, (2) a reinforcement‑learning algorithm that matches CFR’s empirical strength in tabular settings, and (3) evidence that the same algorithm scales to deep self‑play. By bridging optimization theory, equilibrium computation, and practical RL, Magnetic Mirror Descent offers a unified and powerful approach to two‑player zero‑sum problems.
Comments & Academic Discussion
Loading comments...
Leave a Comment