Data-driven discovery of coordinates and governing equations
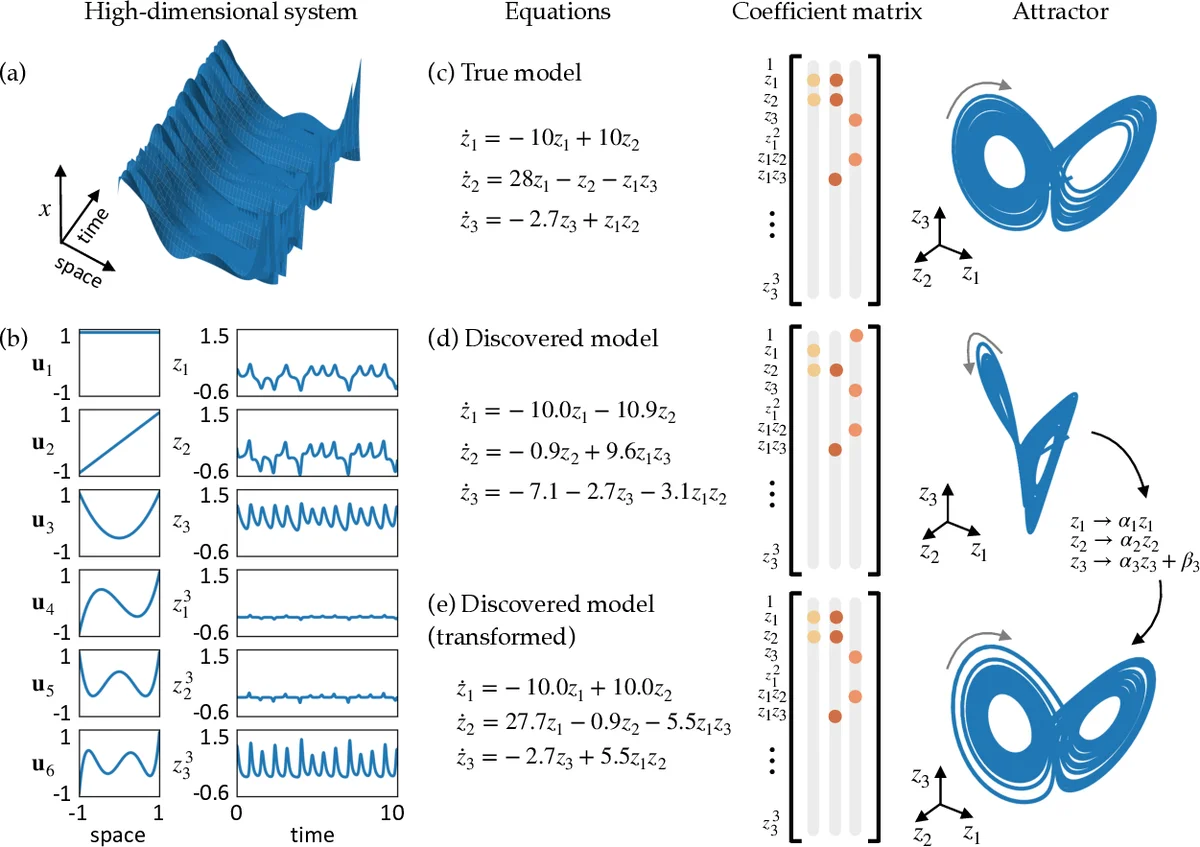
The discovery of governing equations from scientific data has the potential to transform data-rich fields that lack well-characterized quantitative descriptions. Advances in sparse regression are currently enabling the tractable identification of both the structure and parameters of a nonlinear dynamical system from data. The resulting models have the fewest terms necessary to describe the dynamics, balancing model complexity with descriptive ability, and thus promoting interpretability and generalizability. This provides an algorithmic approach to Occam’s razor for model discovery. However, this approach fundamentally relies on an effective coordinate system in which the dynamics have a simple representation. In this work, we design a custom autoencoder to discover a coordinate transformation into a reduced space where the dynamics may be sparsely represented. Thus, we simultaneously learn the governing equations and the associated coordinate system. We demonstrate this approach on several example high-dimensional dynamical systems with low-dimensional behavior. The resulting modeling framework combines the strengths of deep neural networks for flexible representation and sparse identification of nonlinear dynamics (SINDy) for parsimonious models. It is the first method of its kind to place the discovery of coordinates and models on an equal footing.
💡 Research Summary
The paper introduces a novel framework that simultaneously learns a low‑dimensional coordinate transformation and a parsimonious governing equation for high‑dimensional dynamical data. Traditional Sparse Identification of Nonlinear Dynamics (SINDy) excels at extracting sparse models when the state variables are already expressed in a coordinate system that yields a simple representation. However, in many modern applications the measured variables are not the natural coordinates, causing SINDy to either produce overly complex models or fail entirely. To overcome this limitation, the authors embed a custom autoencoder within the SINDy pipeline. The encoder ϕ maps the high‑dimensional measurements x ∈ ℝⁿ to latent variables z ∈ ℝᵈ (d ≪ n), while the decoder ψ reconstructs x ≈ ψ(z). Crucially, the training loss combines three terms: (1) reconstruction error, (2) a dynamics consistency term that enforces the latent time derivative ẋ to match a sparse linear combination of candidate functions Θ(z) with coefficients Ξ, and (3) an ℓ₁ regularization on Ξ to promote sparsity. The dynamics consistency term is derived by differentiating the encoder (∇ₓϕ) and multiplying by the measured state derivative ẋ, which can be obtained by numerical differentiation or sensor data. By jointly optimizing the neural network parameters and the sparse coefficients, the method forces the latent space to be one in which the dynamics are inherently sparse.
The authors demonstrate the approach on three benchmark problems. First, a 64‑dimensional embedding of the chaotic Lorenz system is processed; the autoencoder discovers a three‑dimensional latent space that exactly recovers the classic Lorenz equations, something standard SINDy cannot achieve on the raw data. Second, a reaction‑diffusion system that generates spiral waves is treated; despite the high‑dimensional spatial field, the latent coordinates capture the core spiral dynamics, and SINDy yields a compact polynomial model describing rotation and radial growth. Third, a nonlinear pendulum (θ, θ̇) is used to illustrate that even when the original system is low‑dimensional, the autoencoder can discover an energy‑conserving representation that simplifies the identified equations. In all cases, the reconstructed full‑state fields from the decoder match the original data closely, confirming that the latent coordinates retain essential information.
The paper also discusses limitations and future directions. Accurate estimation of ẋ is critical; noisy measurements can degrade the dynamics loss, suggesting the need for integral‑based losses, variational formulations, or physics‑informed regularization (e.g., enforcing conservation laws or symmetries). The choice of the candidate library Θ strongly influences model quality; adaptive or learned libraries could further improve flexibility. Finally, the current work focuses on offline training; extending the method to online learning, control synthesis, and multi‑scale or multi‑physics problems are promising avenues.
In summary, this work establishes a unified “coordinate‑and‑model discovery” paradigm that leverages the universal approximation power of deep autoencoders together with the interpretability of sparse regression. By ensuring that the learned latent space admits a sparse dynamical description, the authors provide a powerful tool for extracting interpretable, generalizable models from complex, high‑dimensional data—advancing the state of the art in data‑driven scientific discovery.
Comments & Academic Discussion
Loading comments...
Leave a Comment