Visualizing probabilistic models: Intensive Principal Component Analysis
Unsupervised learning makes manifest the underlying structure of data without curated training and specific problem definitions. However, the inference of relationships between data points is frustrated by the `curse of dimensionality’ in high-dimensions. Inspired by replica theory from statistical mechanics, we consider replicas of the system to tune the dimensionality and take the limit as the number of replicas goes to zero. The result is the intensive embedding, which is not only isometric (preserving local distances) but allows global structure to be more transparently visualized. We develop the Intensive Principal Component Analysis (InPCA) and demonstrate clear improvements in visualizations of the Ising model of magnetic spins, a neural network, and the dark energy cold dark matter ({\Lambda}CDM) model as applied to the Cosmic Microwave Background.
💡 Research Summary
The paper introduces a novel manifold‑learning technique called Intensive Principal Component Analysis (InPCA) that addresses the “curse of dimensionality” inherent in visualizing high‑dimensional probabilistic models. Starting from a generic likelihood function (L(x|\theta)), the authors first embed each model’s probability distribution onto a hypersphere using the square‑root mapping (z_x(\theta)=\sqrt{L(x|\theta)}). The Euclidean distance on this hypersphere coincides with the Hellinger distance and, via the Fisher Information Metric, preserves local geometry. However, as the data dimension grows, all points become nearly equidistant on the sphere, destroying relative contrast and rendering standard dimensionality‑reduction methods ineffective.
To overcome this, the authors borrow the replica trick from statistical physics. By considering (N) independent replicas of the system, the distance per replica scales as (-8\log\langle L(\cdot|\theta_1),L(\cdot|\theta_2)\rangle/N). Taking the limit (N\to0) yields a new “intensive distance” (d_I^2(\theta_1,\theta_2)=-8\log\langle L(\cdot|\theta_1),L(\cdot|\theta_2)\rangle). This distance remains isometric to the Fisher metric, but it is non‑Euclidean (it does not satisfy the triangle inequality), allowing distances to diverge rather than saturate. Consequently, the intensive distance retains discriminability even in extremely high dimensions, effectively curing the concentration‑of‑distances problem.
Using this distance, the authors construct an intensive cross‑covariance matrix (W_{ij}=4\log\langle L(\cdot|\theta_i),L(\cdot|\theta_j)\rangle). Unlike the ordinary covariance matrix, (W) can have negative eigenvalues, leading to complex principal components—a reflection of the underlying non‑Euclidean geometry. Performing an eigen‑decomposition of (W) defines the InPCA algorithm, which projects model parameters onto a low‑dimensional space while preserving both local and global structure.
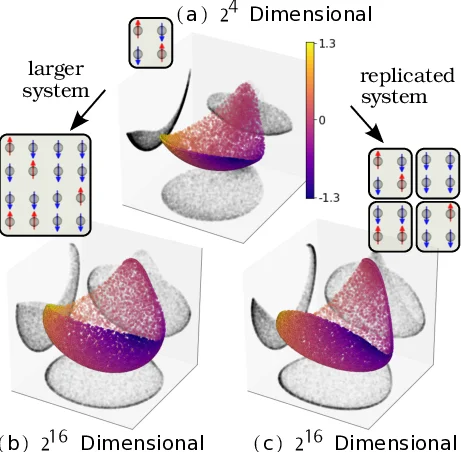
The method is demonstrated on three distinct systems: (1) the Ising model on 2×2 and 4×4 lattices, where increasing system size (or replica number) causes the hyperspherical embedding to wrap and lose contrast, yet the intensive embedding cleanly recovers the underlying two‑dimensional manifold; (2) a feed‑forward neural network trained on handwritten digits, where InPCA visualizes the learning trajectory, showing a rapid initial spread followed by convergence into tight clusters; (3) the ΛCDM cosmological model, where six fundamental parameters generate CMB angular power spectra. Compared with t‑SNE, Diffusion Maps, and UMAP, InPCA better preserves the global parameter relationships while still revealing local clustering, facilitating physical interpretation of the model manifold.
In summary, by applying the zero‑replica limit of the replica trick, the authors derive an intensive distance proportional to the Bhattacharyya divergence, which serves as a robust metric for probability distributions. InPCA leverages this metric to produce visualizations that simultaneously retain fine‑grained local distances and the overall shape of the model manifold, offering a powerful new tool for exploring high‑dimensional probabilistic models across physics, astronomy, and machine learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment