Overcoming catastrophic forgetting in neural networks
The ability to learn tasks in a sequential fashion is crucial to the development of artificial intelligence. Neural networks are not, in general, capable of this and it has been widely thought that catastrophic forgetting is an inevitable feature of connectionist models. We show that it is possible to overcome this limitation and train networks that can maintain expertise on tasks which they have not experienced for a long time. Our approach remembers old tasks by selectively slowing down learning on the weights important for those tasks. We demonstrate our approach is scalable and effective by solving a set of classification tasks based on the MNIST hand written digit dataset and by learning several Atari 2600 games sequentially.
💡 Research Summary
The paper addresses the long‑standing problem of catastrophic forgetting in neural networks, which hampers the ability of artificial agents to learn tasks sequentially. Inspired by biological synaptic consolidation, the authors propose Elastic Weight Consolidation (EWC), a method that selectively slows learning on weights that are important for previously learned tasks.
From a Bayesian perspective, learning a new task B after task A can be expressed as maximizing the posterior p(θ|D_B, D_A). By approximating the posterior after task A with a Gaussian whose mean is the optimal parameters θ*_A and whose precision is given by the diagonal of the Fisher information matrix F, the authors derive a regularized loss:
L(θ) = L_B(θ) + (λ/2) Σ_i F_i (θ_i – θ*_A,i)²
The first term is the standard loss for the current task, while the second term acts as a set of elastic springs pulling each weight back toward its previous value, with stiffness proportional to its Fisher information. The scalar λ balances stability (preserving old tasks) against plasticity (learning new tasks). For multiple past tasks, the quadratic penalties can be summed, effectively accumulating constraints.
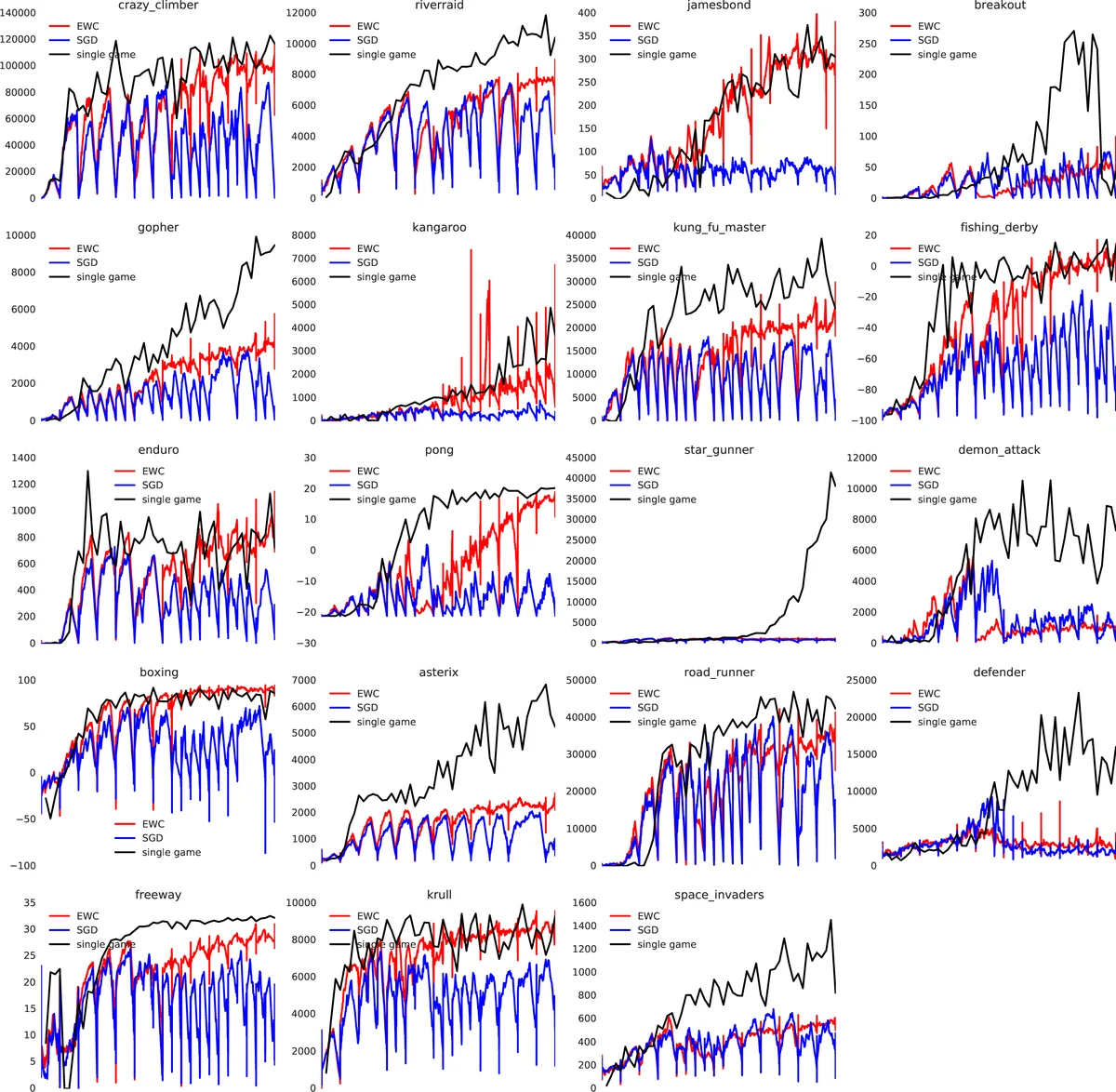
The method is evaluated in two domains.
-
Supervised learning – Permuted MNIST: Each task consists of the MNIST digit classification problem with a fixed random pixel permutation. Plain stochastic gradient descent quickly forgets the first task when training on the second. L2 regularization helps only marginally because it treats all weights equally. EWC, by contrast, retains high accuracy on earlier permutations while still achieving strong performance on new ones. Analysis of the overlap between Fisher matrices shows that when permutations are very different, early layers allocate distinct parameters to each task, whereas deeper layers share representations because the output space (digit labels) remains the same.
-
Reinforcement learning – Atari 2600 games: The authors integrate EWC into a Deep Q‑Network (DQN) and compute a Fisher matrix at each game switch. A hidden Markov model is used to infer the current game (task context) and to add new generative models when novel games are encountered (the “forget‑me‑not” process). Across ten randomly selected Atari games, a single network with EWC maintains performance on previously learned games while continuing to improve on the current game. This contrasts with prior continual‑RL approaches that either expand network capacity or train separate networks per game. EWC requires only modest additional computation and no replay buffer that scales with the number of tasks.
Key contributions:
- A principled, Bayesian‑derived regularizer that quantifies weight importance via the Fisher information.
- Demonstration that a single fixed‑capacity network can learn many supervised and reinforcement tasks sequentially without catastrophic forgetting.
- Empirical evidence that EWC enables both parameter sharing and task‑specific allocation, depending on task similarity.
Limitations include the diagonal Fisher approximation (ignoring weight correlations), sensitivity to the λ hyper‑parameter, and the storage cost of Fisher matrices for very large models. Future work may explore full‑covariance Fisher approximations, meta‑learning of λ, and application to non‑stationary data streams.
Overall, Elastic Weight Consolidation provides a scalable, biologically motivated solution to continual learning, bridging a critical gap between deep learning successes and the lifelong learning capabilities observed in biological systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment