Bayesian Learning to Discover Mathematical Operations in Governing Equations of Dynamic Systems
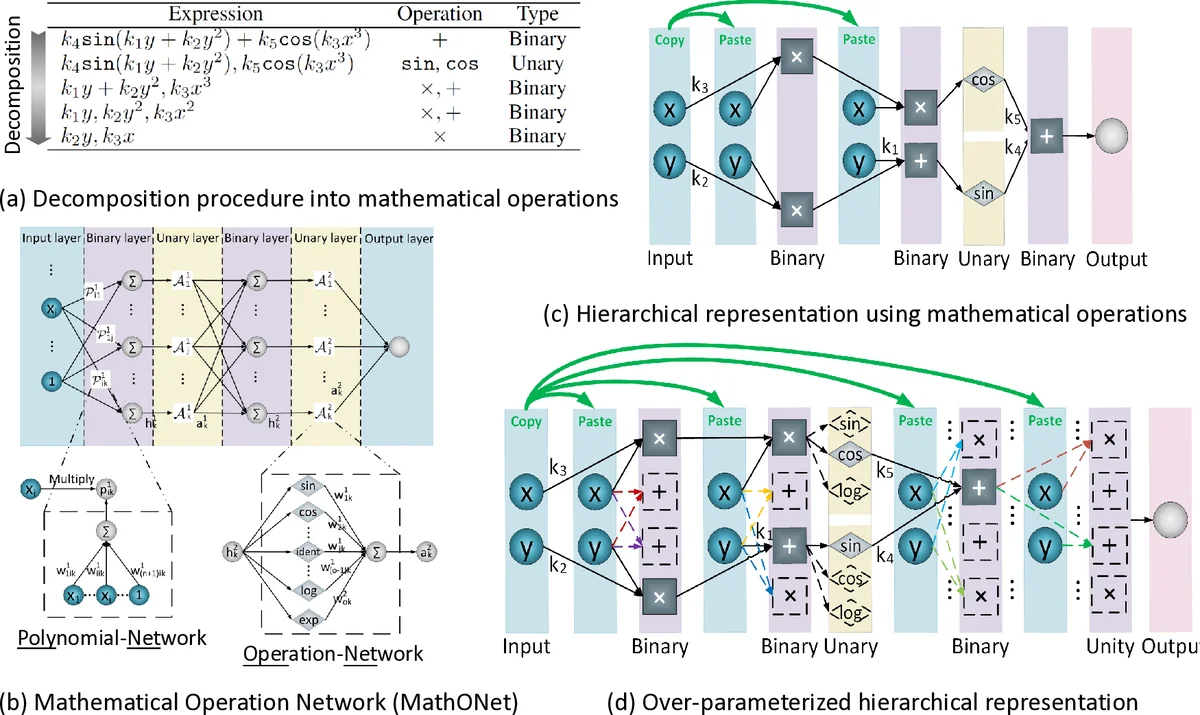
Discovering governing equations from data is critical for diverse scientific disciplines as they can provide insights into the underlying phenomenon of dynamic systems. This work presents a new representation for governing equations by designing the Mathematical Operation Network (MathONet) with a deep neural network-like hierarchical structure. Specifically, the MathONet is stacked by several layers of unary operations (e.g., sin, cos, log) and binary operations (e.g., +,-), respectively. An initialized MathONet is typically regarded as a super-graph with a redundant structure, a sub-graph of which can yield the governing equation. We develop a sparse group Bayesian learning algorithm to extract the sub-graph by employing structurally constructed priors over the redundant mathematical operations. By demonstrating the chaotic Lorenz system, Lotka-Volterra system, and Kolmogorov-Petrovsky-Piskunov system, the proposed method can discover the ordinary differential equations (ODEs) and partial differential equations (PDEs) from the observations given limited mathematical operations, without any prior knowledge on possible expressions of the ODEs and PDEs.
💡 Research Summary
The paper introduces a novel data‑driven framework for discovering the governing ordinary and partial differential equations (ODEs/PDEs) of dynamic systems without any prior knowledge of the equation form. The core idea is to represent any candidate equation as a hierarchical network of elementary mathematical operations—unary functions such as sin, cos, log, and binary operators such as addition and multiplication. This network, called the Mathematical Operation Network (MathONet), is built by stacking layers of “PolyNets” (linear combinations of inputs that implement binary operations) and “OperNets” (linear combinations of unary functions). When initialized, MathONet is heavily over‑parameterized, i.e., a super‑graph that contains many redundant connections. The true governing equation corresponds to a sub‑graph where only a small subset of connections have non‑zero weights.
To extract this sub‑graph, the authors first try Sparse‑Group Lasso, a regularizer that combines element‑wise L1 sparsity with group‑wise L2 sparsity. Experiments show that, although it prunes many weights, the resulting model remains overly dense (e.g., 651 terms for the Lorenz system) and fails to reproduce the dynamics accurately. Consequently, the authors develop a Bayesian alternative: a Sparse‑Group Bayesian Learning algorithm. Each weight receives an independent Gaussian prior, while each group of weights (the whole PolyNet or OperNet) receives a shared Gaussian prior. The hyper‑parameters (precision of these priors) are learned by maximizing the model evidence using a Laplace approximation. This yields closed‑form update rules involving the Hessian of the loss, allowing iterative refinement of both the weight posterior means and the sparsity‑inducing hyper‑parameters. The training proceeds in “epoch‑cycle” fashion: after a fixed number of epochs (a cycle) the network is pruned by zeroing weights whose posterior variance indicates irrelevance, and training resumes on the reduced graph.
The method is validated on three benchmark systems: the chaotic Lorenz attractor, the predator‑prey Lotka‑Volterra model, and the Kolmogorov‑Petrovsky‑Piskunov (KPP) reaction‑diffusion equation. In all cases, the Bayesian approach discovers a dramatically smaller set of terms (often just a handful) that exactly match the known governing equations and reproduce the observed trajectories with high fidelity, even in the presence of measurement noise. Compared with Sparse‑Group Lasso, the Bayesian method achieves far greater sparsity and accuracy without extensive hyper‑parameter tuning.
Key contributions are: (1) the design of MathONet, a DNN‑like architecture that treats mathematical operations as network layers, enabling a compact representation of a huge space of possible equations; (2) a principled Bayesian sparsity framework that jointly enforces element‑wise and group‑wise sparsity, leading to automatic model selection; (3) empirical evidence that the approach can recover both ODEs and PDEs from raw data using only a limited library of elementary functions.
Limitations include the need to pre‑specify the depth of MathONet, the number of neurons per layer, and the set of unary functions; the Laplace approximation and Hessian computation may become costly for very high‑dimensional problems; and the current function library does not cover piecewise or conditional operations that appear in some physical laws. Future work could explore variational Bayesian techniques for more scalable inference, automatic expansion of the function library, and efficient Hessian‑free approximations to handle large‑scale systems. Overall, the paper presents a compelling blend of symbolic‑like expression discovery with modern Bayesian deep learning, opening a promising direction for interpretable system identification.
Comments & Academic Discussion
Loading comments...
Leave a Comment