Text/Speech-Driven Full-Body Animation
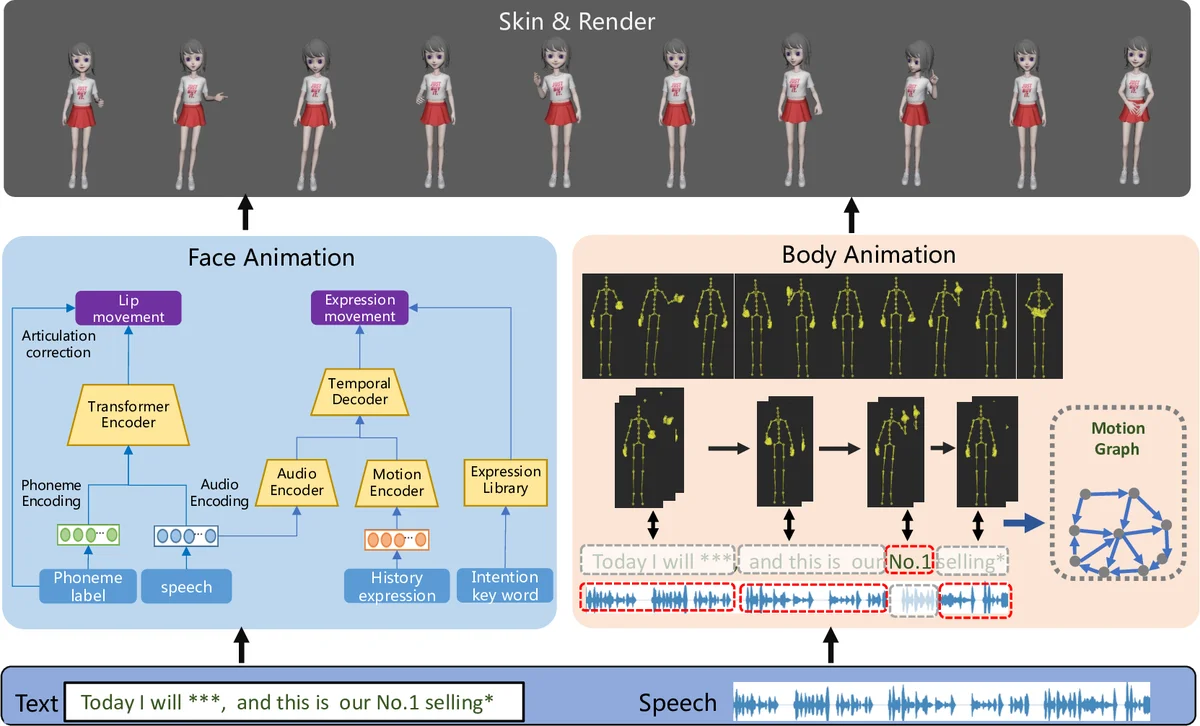
Due to the increasing demand in films and games, synthesizing 3D avatar animation has attracted much attention recently. In this work, we present a production-ready text/speech-driven full-body animation synthesis system. Given the text and corresponding speech, our system synthesizes face and body animations simultaneously, which are then skinned and rendered to obtain a video stream output. We adopt a learning-based approach for synthesizing facial animation and a graph-based approach to animate the body, which generates high-quality avatar animation efficiently and robustly. Our results demonstrate the generated avatar animations are realistic, diverse and highly text/speech-correlated.
💡 Research Summary
This paper presents a production‑ready system that synthesizes full‑body 3D avatar animation from simultaneous text and speech inputs. The authors identify a gap in prior work, which typically focuses on either facial or bodily motion, and argue that realistic avatar performance requires coordinated generation of both modalities driven by linguistic and acoustic cues. The proposed pipeline consists of two parallel branches that converge after skinning and rendering.
The facial animation branch uses a multi‑path transformer architecture. For lip synchronization, the model ingests concatenated phoneme embeddings (derived from forced alignment of the transcript) and acoustic features (MFCC and Mel filter‑bank coefficients) within a 25‑frame (≈1 s) window. A custom loss combines a shape term (L2 distance between predicted and ground‑truth blendshape parameters) and a motion term (difference of successive frames) to enforce both accurate geometry and smooth temporal dynamics. An articulation correction step enforces phoneme‑specific constraints (e.g., mouth closure for /b/, /p/, /m/). Upper‑face expression generation is split into rhythmic and intention‑driven components. The rhythmic component employs an audio encoder and a motion history encoder whose outputs are fused by a transformer decoder; training uses an SSIM‑based loss to preserve structural similarity. Intention‑driven expressions are triggered by semantic tags extracted via sentiment analysis of the transcript (e.g., happiness, sadness, emphasis). A curated library of 50+ intention‑specific expressions enables fusion of the rhythmic output with the appropriate high‑level affect.
The body animation branch adopts a motion‑graph approach. A motion capture database, collected with professional actors using a Vicon system, is divided into “semantic motions” (24 categories tightly linked to textual semantics such as numbers or directional cues) and “non‑semantic motions” (generic upper‑body gestures, foot steps, etc.). Each long capture is segmented at local minima of a motion‑strength signal to create graph nodes; edges are added when the transition cost—computed from joint position and velocity differences—falls below a threshold σ. Semantic motions are manually ensured to be complete sequences.
During synthesis, the input text‑speech segment is parsed into phrases. For each phrase, the system retrieves candidate motion nodes based on semantic keyword matching (for semantic phrases) and rhythmic similarity (for non‑semantic phrases). Similarity of rhythm is measured by comparing motion‑strength curves with audio onset envelopes extracted via librosa. An optimization problem selects a path through the graph that minimizes a weighted sum of transition costs, semantic‑text loss, and rhythmic‑alignment loss (Equation 3). Weight parameters λt, λs, λr allow users to prioritize smooth transitions, semantic fidelity, or rhythmic adherence. The resulting motion sequence is concatenated, blended, and combined with the facial animation.
The final stage skins the combined facial and skeletal motion onto a 3D avatar and renders a video stream suitable for real‑time applications such as live e‑commerce broadcasting. Qualitative results on both Chinese and English inputs demonstrate realistic, diverse, and highly correlated animations. The system can produce multiple distinct motions for the same input, reflecting the inherent one‑to‑many mapping between language and gesture. User studies indicate acceptance by both professional artists and lay users.
In conclusion, the authors deliver an end‑to‑end framework that leverages deep learning for fine‑grained facial synthesis and a graph‑based retrieval mechanism for robust body motion, achieving controllable, high‑quality full‑body animation from text and speech. Future work will explore richer emotional modeling, personality traits, and interactive behaviors to further enhance avatar expressiveness.
Comments & Academic Discussion
Loading comments...
Leave a Comment