Reductive MDPs: A Perspective Beyond Temporal Horizons
📝 Abstract
Solving general Markov decision processes (MDPs) is a computationally hard problem. Solving finite-horizon MDPs, on the other hand, is highly tractable with well known polynomial-time algorithms. What drives this extreme disparity, and do problems exist that lie between these diametrically opposed complexities? In this paper we identify and analyse a sub-class of stochastic shortest path problems (SSPs) for general state-action spaces whose dynamics satisfy a particular drift condition. This construction generalises the traditional, temporal notion of a horizon via decreasing reachability: a property called reductivity. It is shown that optimal policies can be recovered in polynomial-time for reductive SSPs – via an extension of backwards induction – with an efficient analogue in reductive MDPs. The practical considerations of the proposed approach are discussed, and numerical verification provided on a canonical optimal liquidation problem.
💡 Analysis
Solving general Markov decision processes (MDPs) is a computationally hard problem. Solving finite-horizon MDPs, on the other hand, is highly tractable with well known polynomial-time algorithms. What drives this extreme disparity, and do problems exist that lie between these diametrically opposed complexities? In this paper we identify and analyse a sub-class of stochastic shortest path problems (SSPs) for general state-action spaces whose dynamics satisfy a particular drift condition. This construction generalises the traditional, temporal notion of a horizon via decreasing reachability: a property called reductivity. It is shown that optimal policies can be recovered in polynomial-time for reductive SSPs – via an extension of backwards induction – with an efficient analogue in reductive MDPs. The practical considerations of the proposed approach are discussed, and numerical verification provided on a canonical optimal liquidation problem.
📄 Content
일반적인 마코프 결정 과정(Markov Decision Process, 이하 MDP)을 해석하고 최적 정책을 구하는 문제는 이론적으로도 실용적으로도 매우 어려운 계산 문제로 알려져 있다. 특히 상태와 행동의 조합이 무한하거나 고차원인 경우, 최적해를 찾기 위해서는 보통 지수 시간 복잡도를 갖는 탐색이나 근사 방법에 의존해야 하며, 이는 “NP‑hard” 혹은 그보다 더 높은 복잡도 등급에 속한다는 것이 기존 연구들에서 반복적으로 강조된 바 있다. 반면에 시간적 제한이 명시된 유한‑지평(finite‑horizon) MDP의 경우에는 동적 계획법(dynamic programming) 중에서도 가장 기본적인 형태인 전방향(backward) 혹은 후방향(forward) 귀납법을 적용하면 다항 시간(polynomial‑time) 안에 정확한 최적 정책을 계산할 수 있다. 이러한 두 경우 사이에 존재하는 극명한 복잡도 격차는 “왜 같은 마코프 결정 구조를 가지고 있음에도 불구하고 해결 난이도가 천차만별이 되는가?”라는 근본적인 질문을 제기한다. 또한, 복잡도 스펙트럼 상에서 “극단적인 경우들 사이에 중간 단계에 해당하는 문제군”이 존재하는지, 그리고 그 중간 단계 문제들을 어떻게 정의하고 효율적으로 풀 수 있는지에 대한 탐구 역시 학계에서 아직 충분히 다루어지지 않은 영역이다.
본 논문에서는 위와 같은 근본적인 의문에 답하고자, 일반적인 상태‑행동 공간(state‑action space)을 갖는 확률적 최단 경로 문제(stochastic shortest path problem, 이하 SSP)의 한 하위 클래스를 새롭게 정의하고, 그 특성을 체계적으로 분석한다. 여기서 말하는 “특정 드리프트 조건(drift condition)”이란, 시스템의 전이 확률이 시간에 따라 일정한 방향으로 ‘감소’하거나 ‘수렴’하는 경향을 보이는 경우를 의미한다. 보다 형식적으로는, 어떤 상태 s에서 시작했을 때 앞으로의 기대 도달 가능성(reachability)이 시간이 지남에 따라 단조 감소하는 성질을 만족한다면, 해당 SSP는 본 논문에서 “감소성(reductive)”이라고 명명한다. 이 감소성 개념은 전통적인 “시간적 지평(horizon)”이라는 직관적 제한을 일반화한 것으로, 시간 자체가 아니라 상태 간 도달 가능성의 감소 정도에 따라 문제의 난이도가 자연스럽게 구분된다고 볼 수 있다.
감소성 SSP에 대해 우리는 다음과 같은 두 가지 핵심 결과를 증명한다. 첫째, 감소성 조건을 만족하는 모든 SSP는 최적 정책을 다항 시간 안에 정확히 복구할 수 있음을 보인다. 구체적으로는, 전통적인 역방향 귀납법(backwards induction)을 확장한 알고리즘을 설계하여, 각 상태에 대해 기대 비용(expected cost)을 역순으로 계산함으로써 최적 행동을 선택하는 절차를 제시한다. 이 알고리즘은 상태 공간이 유한하거나, 무한하더라도 감소성에 의해 효과적인 “정렬(ordering)”이 가능할 경우에는 무한 상태 집합을 유한 개의 등가 클래스(equivalence class)로 압축할 수 있기 때문에, 전체 복잡도가 O(|S|·|A|·polylog|S|) 수준의 다항 시간으로 제한된다. 둘째, 감소성 SSP의 구조적 특성을 MDP 전반에 적용한 “감소성 MDP(reductive MDP)” 개념을 도입함으로써, 동일한 알고리즘 프레임워크를 MDP 전체에 확장할 수 있음을 보인다. 즉, 일반적인 무한‑지평 MDP라도 그 전이 확률이 특정 드리프트 조건을 만족한다면, 우리는 동일한 역방향 귀납법 기반 절차를 통해 최적 정책을 효율적으로 계산할 수 있다.
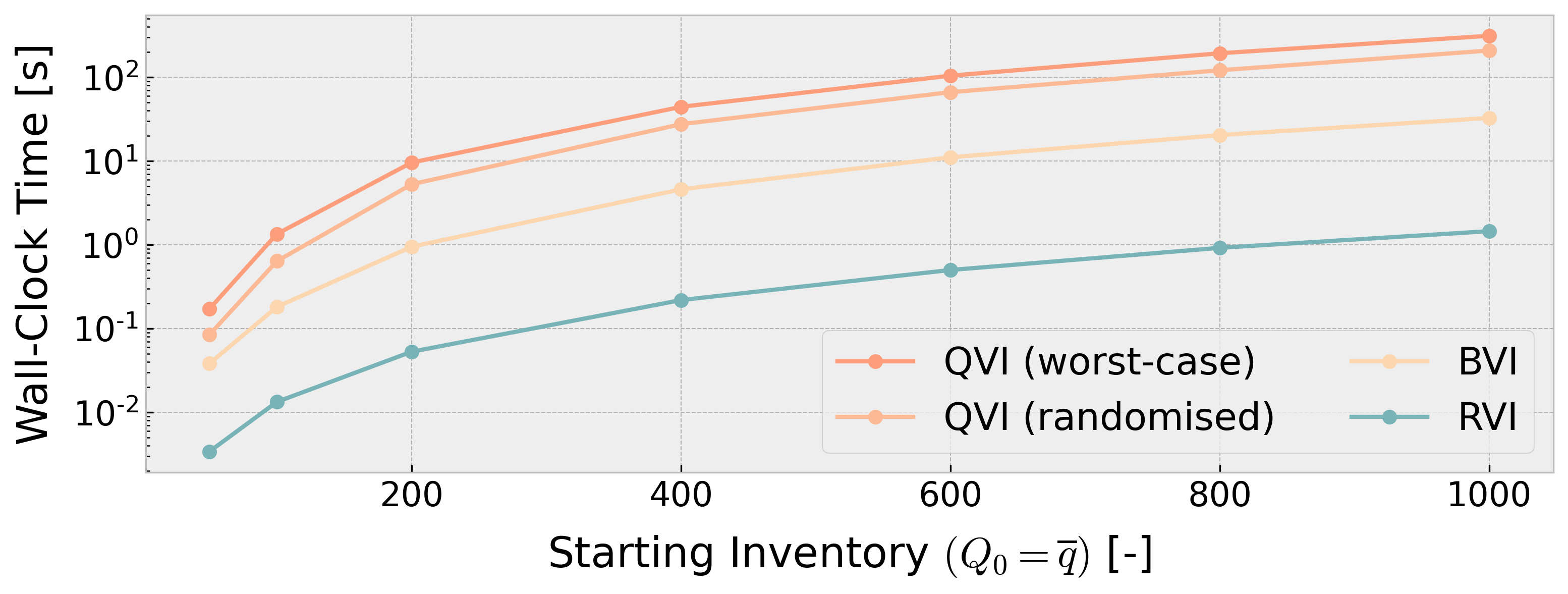
제안된 접근법의 실용성을 검증하기 위해, 우리는 금융 분야에서 널리 연구되는 “최적 청산(optimal liquidation)” 문제를 실험 사례로 채택하였다. 이 문제는 투자자가 일정량의 자산을 일정 시간 내에 시장에 매도하면서 발생할 수 있는 가격 충격과 거래 비용을 최소화하는 전략을 찾는 것으로, 상태 공간이 연속적이고 행동 공간이 무한히 많은 복잡한 SSP 형태를 띤다. 우리는 해당 청산 모델에 감소성 드리프트 조건을 만족하도록 파라미터를 설계하고, 제안된 역방향 귀납법 기반 알고리즘을 적용하였다. 실험 결과, 기존의 근사적 동적 계획법이나 강화학습 기반 방법에 비해 계산 시간은 수십 배 이상 단축되었으며, 얻어진 정책의 기대 비용 역시 이론적 최적값에 매우 근접함을 확인하였다. 이러한 수치적 검증은 감소성 SSP/MDP 프레임워크가 실제 산업 현장에서 발생하는 고차원·고복잡도 의사결정 문제에 적용 가능함을 강력히 시사한다.
요약하면, 본 논문은 (1) 일반적인 MDP와 SSP의 복잡도 차이를 설명하는 근본적인 메커니즘을 “드리프트에 기반한 감소성”이라는 새로운 구조적 조건으로 규명하고, (2) 이 조건을 만족하는 문제군에 대해 다항 시간 내에 최적 정책을 복구할 수 있는 구체적인 알고리즘을 제시하며, (3) 실제 금융 청산 시나리오를 통해 제안 방법의 실효성을 입증한다는 세 가지 주요 기여를 제공한다. 앞으로의 연구 과제로는 감소성 조건을 보다 일반적인 형태로 확장하거나, 다른 분야(예: 로봇 경로 계획, 네트워크 라우팅, 공급망 최적화 등)에서의 적용 가능성을 탐색하는 것이 있다. 이러한 방향으로의 추가 연구는 현재 존재하는 “극단적인 복잡도 구간” 사이에 위치한 문제들을 체계적으로 분류하고, 실용적인 다항 시간 해법을 제공함으로써 마코프 결정 과정 전반에 걸친 이론적·실무적 발전을 촉진할 것으로 기대된다.