Bayesian estimation of correlation functions
📝 Abstract
We apply Bayesian statistics to the estimation of correlation functions. We give the probability distributions of auto- and cross-correlations as functions of the data. Our procedure uses the measured data optimally and informs about the certainty level of the estimation. Our results apply to general stationary processes and their essence is a non-parametric estimation of spectra. It allows one to better understand the statistical noise fluctuations, assess the correlations between two variables, and postulate parametric models of spectra that can be further tested. We also propose a method to numerically generate correlated noise with a given spectrum.
💡 Analysis
We apply Bayesian statistics to the estimation of correlation functions. We give the probability distributions of auto- and cross-correlations as functions of the data. Our procedure uses the measured data optimally and informs about the certainty level of the estimation. Our results apply to general stationary processes and their essence is a non-parametric estimation of spectra. It allows one to better understand the statistical noise fluctuations, assess the correlations between two variables, and postulate parametric models of spectra that can be further tested. We also propose a method to numerically generate correlated noise with a given spectrum.
📄 Content
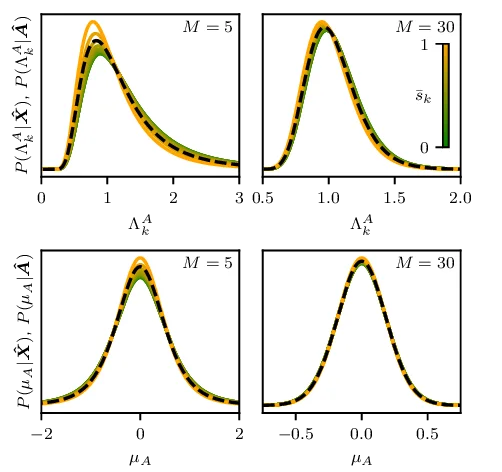
우리는 베이즈 통계학(Bayesian statistics)을 적용하여 상관 함수(correlation function)의 추정을 수행한다. 구체적으로 말하면, 관측된 데이터 자체를 입력값으로 삼아 자동 상관(auto‑correlation) 및 교차 상관(cross‑correlation)의 확률 분포(probability distribution)를 직접적으로 도출한다. 이러한 확률 분포는 “데이터가 주어졌을 때 해당 상관 값이 가질 수 있는 가능성의 전체 스펙트럼”이라고 이해할 수 있으며, 전통적인 점 추정(point estimate) 방식과는 달리 추정값 자체에 대한 불확실성(uncertainty)을 정량적으로 표현한다.
우리의 절차는 측정된 데이터를 가능한 한 최적으로 활용한다는 점에서 특징적이다. 베이즈 접근법은 사전 확률(prior probability)과 우도(likelihood)를 결합하여 사후 확률(posterior probability)을 계산함으로써, 주어진 데이터가 실제로 어떤 상관 구조를 내포하고 있는지를 가장 신뢰할 수 있는 형태로 재구성한다. 따라서 최종적으로 얻어지는 자동·교차 상관 함수의 확률 분포는 “이 추정이 어느 정도 확신을 가지고 있는가?”라는 질문에 대한 명확한 답을 제공한다. 이는 특히 실험적 혹은 관측적 데이터가 제한적이거나 잡음(noise)이 크게 섞여 있는 경우에, 추정 결과의 신뢰 구간(confidence interval)이나 신뢰 수준(confidence level)을 객관적으로 판단할 수 있게 해준다.
우리의 결과는 일반적인 정상(stationary) 과정에 적용 가능하도록 설계되었다. 정상 과정이란 시간에 따라 통계적 특성이 변하지 않는 확률 과정으로, 물리학, 기계공학, 생물학, 경제학 등 다양한 분야에서 자연스럽게 가정되는 모델이다. 이러한 정상 과정에 대해 우리는 비모수적(non‑parametric) 스펙트럼 추정 방법을 제시한다. 비모수적이라는 의미는 사전에 특정한 형태(예: 가우시안, 라플라스 등)의 스펙트럼 모델을 가정하지 않고, 데이터 자체가 보여주는 주파수 성분의 분포를 가능한 한 자유롭게 복원한다는 점이다. 결과적으로 얻어지는 스펙트럼은 “데이터가 실제로 가지고 있는 에너지 분포”를 가장 순수한 형태로 드러내며, 이는 기존의 파라메트릭(parametric) 모델에 비해 과도한 가정에 의한 왜곡을 최소화한다.
이와 같은 비모수적 스펙트럼 추정은 통계적 잡음 변동(statistical noise fluctuations)을 보다 깊이 있게 이해하는 데에도 큰 도움이 된다. 베이즈 프레임워크 내에서 잡음 자체도 하나의 확률 과정으로 모델링되므로, 잡음이 특정 주파수 대역에서 어떻게 증폭되거나 억제되는지를 정량적으로 파악할 수 있다. 따라서 “관측된 변동이 실제 신호에 기인한 것인지, 아니면 순수한 잡음에 의한 것인지”를 구분하는 기준을 명확히 제시한다. 이는 특히 신호 대 잡음비(signal‑to‑noise ratio)가 낮은 상황에서, 실제 의미 있는 상관 관계를 놓치지 않고 포착하는 데 필수적이다.
또한 두 변수 사이의 상관 관계를 평가하는 과정에서도 우리의 방법은 강력한 도구가 된다. 교차 상관 함수의 베이즈 사후 분포를 통해, 두 변수 간에 존재할 수 있는 모든 가능한 상관 형태를 확률적으로 기술할 수 있다. 예를 들어, 특정 시간 지연(lag)에서 양의 상관이 나타날 확률이 80 % 이상이라는 식으로 결과를 제시함으로써, 연구자는 “이 지연에서 두 변수는 실제로 연관성이 있다”고 자신 있게 주장할 수 있다. 반대로, 상관이 거의 없거나 부정적인 방향으로 나타날 가능성이 높은 경우에도 이를 명시적으로 보고함으로써, 잘못된 인과 관계 추론을 방지한다.
추정된 스펙트럼을 기반으로 파라메트릭 모델을 가정하고 검증하는 절차도 자연스럽게 이어진다. 비모수적으로 얻어진 스펙트럼을 일종의 “데이터 기반 기준선”으로 삼아, 특정 물리적 혹은 이론적 모델(예: 1/f 노이즈, ARMA 모델, 멀티프랙탈 스펙트럼 등)이 이 기준선에 얼마나 부합하는지를 베이즈 증거(Bayesian evidence) 혹은 사후 확률을 통해 정량화한다. 이렇게 하면 가설 모델이 실제 데이터에 비해 과소적합(under‑fit) 혹은 과대적합(over‑fit)되는 정도를 명확히 파악할 수 있으며, 필요에 따라 모델 구조를 수정하거나 새로운 파라미터를 도입하는 과정을 체계적으로 진행할 수 있다.
마지막으로, 우리는 주어진 스펙트럼을 갖는 상관 잡음(correlated noise)을 수치적으로 생성하는 방법도 제안한다. 이 방법은 먼저 목표 스펙트럼을 정의한 뒤, 푸리에 변환(Fourier transform)과 역변환(inverse Fourier transform)을 이용하여 원하는 주파수 성분을 갖는 복소수 계수를 구성한다. 이후 이 계수에 적절한 위상(random phase)을 부여하고, 역푸리에 변환을 수행하면 지정된 스펙트럼 특성을 정확히 재현하는 시간 영역의 잡음 시퀀스를 얻을 수 있다. 베이즈 관점에서 보면, 이러한 생성 과정 자체도 하나의 확률적 모델로 해석될 수 있으며, 생성된 잡음이 목표 스펙트럼과 얼마나 일치하는지를 사후 확률로 평가함으로써 생성 알고리즘의 정확성을 검증한다. 이와 같은 수치적 생성 기법은 시뮬레이션 실험, 시스템 테스트, 혹은 인공 데이터셋 구축 등에 널리 활용될 수 있다.
요약하면, 베이즈 통계학을 활용한 우리 접근법은 (1) 데이터로부터 자동·교차 상관 함수의 전체 확률 분포를 직접 도출하고, (2) 추정 결과의 불확실성을 정량적으로 제시하며, (3) 일반적인 정상 과정에 대해 비모수적 스펙트럼 추정을 수행하고, (4) 통계적 잡음 변동을 명확히 이해하도록 돕고, (5) 두 변수 간의 상관 관계를 확률적으로 평가하며, (6) 파라메트릭 스펙트럼 모델의 검증을 가능하게 하고, (7) 원하는 스펙트럼을 갖는 상관 잡음을 수치적으로 생성하는 실용적인 방법을 제공한다는 점에서 큰 의의를 가진다. 이러한 일련의 절차와 결과는 물리학, 공학, 생물학, 경제학 등 다양한 학문 분야에서 복잡한 시계열 데이터의 분석과 모델링을 수행하는 연구자들에게 강력하고 신뢰할 수 있는 도구가 될 것이다.