Portfolio Optimization Using a Consistent Vector-Based MSE Estimation Approach
📝 Abstract
This paper is concerned with optimizing the global minimum-variance portfolio’s (GMVP) weights in high-dimensional settings where both observation and population dimensions grow at a bounded ratio. Optimizing the GMVP weights is highly influenced by the data covariance matrix estimation. In a high-dimensional setting, it is well known that the sample covariance matrix is not a proper estimator of the true covariance matrix since it is not invertible when we have fewer observations than the data dimension. Even with more observations, the sample covariance matrix may not be well-conditioned. This paper determines the GMVP weights based on a regularized covariance matrix estimator to overcome the aforementioned difficulties. Unlike other methods, the proper selection of the regularization parameter is achieved by minimizing the mean-squared error of an estimate of the noise vector that accounts for the uncertainty in the data mean estimation. Using random-matrix-theory tools, we derive a consistent estimator of the achievable mean-squared error that allows us to find the optimal regularization parameter using a simple line search. Simulation results demonstrate the effectiveness of the proposed method when the data dimension is larger than the number of data samples or of the same order.
💡 Analysis
This paper is concerned with optimizing the global minimum-variance portfolio’s (GMVP) weights in high-dimensional settings where both observation and population dimensions grow at a bounded ratio. Optimizing the GMVP weights is highly influenced by the data covariance matrix estimation. In a high-dimensional setting, it is well known that the sample covariance matrix is not a proper estimator of the true covariance matrix since it is not invertible when we have fewer observations than the data dimension. Even with more observations, the sample covariance matrix may not be well-conditioned. This paper determines the GMVP weights based on a regularized covariance matrix estimator to overcome the aforementioned difficulties. Unlike other methods, the proper selection of the regularization parameter is achieved by minimizing the mean-squared error of an estimate of the noise vector that accounts for the uncertainty in the data mean estimation. Using random-matrix-theory tools, we derive a consistent estimator of the achievable mean-squared error that allows us to find the optimal regularization parameter using a simple line search. Simulation results demonstrate the effectiveness of the proposed method when the data dimension is larger than the number of data samples or of the same order.
📄 Content
본 논문은 관측 차원과 모집단 차원이 제한된 비율로 동시에 증가하는 고차원(high‑dimensional) 환경에서 전역 최소 분산 포트폴리오(Global Minimum‑Variance Portfolio, 이하 GMVP)의 가중치를 최적화하는 문제에 초점을 맞추고 있다. GMVP는 포트폴리오 이론에서 위험(분산)을 최소화하면서 기대 수익을 일정 수준 이상으로 유지하려는 투자 전략의 하나이며, 그 실현을 위해서는 각 자산에 할당할 최적의 비중, 즉 가중치를 정확히 계산하는 것이 필수적이다. 이러한 가중치 계산은 기본적으로 자산 수익률들의 공분산 행렬(covariance matrix)을 어떻게 추정하느냐에 크게 좌우된다.
고차원 상황, 즉 자산의 수(데이터 차원)가 관측치(샘플)의 수보다 훨씬 크거나, 두 수가 비슷한 규모로 증가하는 경우에는 전통적인 표본 공분산 행렬(sample covariance matrix)이 실제(모집단) 공분산 행렬을 추정하는 데 적합하지 않다는 것이 널리 알려져 있다. 구체적으로, 관측치의 수가 데이터 차원보다 적을 때 표본 공분산 행렬은 행렬식이 0이 되어 역행렬(inverse)이 존재하지 않으며, 따라서 직접적인 가중치 계산에 사용할 수 없다. 관측치가 충분히 많아 역행렬이 존재한다 하더라도, 표본 공분산 행렬은 종종 조건수가 매우 크게 나타나(즉, 행렬이 거의 특이(singular)한 형태를 띠어) 수치적으로 불안정하고, 작은 데이터 변동에도 가중치가 크게 변동하는 과민반응(over‑sensitivity)을 보인다. 이러한 문제는 포트폴리오 최적화 결과를 신뢰할 수 없게 만들며, 실제 투자 의사결정에 심각한 위험을 초래한다.
본 연구에서는 이러한 고차원에서 발생하는 공분산 행렬 추정의 어려움을 극복하기 위해, 정규화(regularization)된 공분산 행렬 추정기(regularized covariance matrix estimator)를 도입하고, 이를 기반으로 GMVP 가중치를 결정한다. 정규화란 원래의 표본 공분산 행렬에 일정한 형태의 페널티(penalty) 혹은 추가적인 구조적 정보를 삽입함으로써 행렬을 보다 잘 조건화(conditioned)하고, 역행렬을 안정적으로 계산할 수 있게 만드는 기법을 의미한다. 일반적으로 사용되는 정규화 방법에는 리시(리시) 정규화(Ridge), 라소(Lasso) 정규화, 그리고 더 최근에 제안된 고차원 전용 Shrinkage 방법 등이 있다.
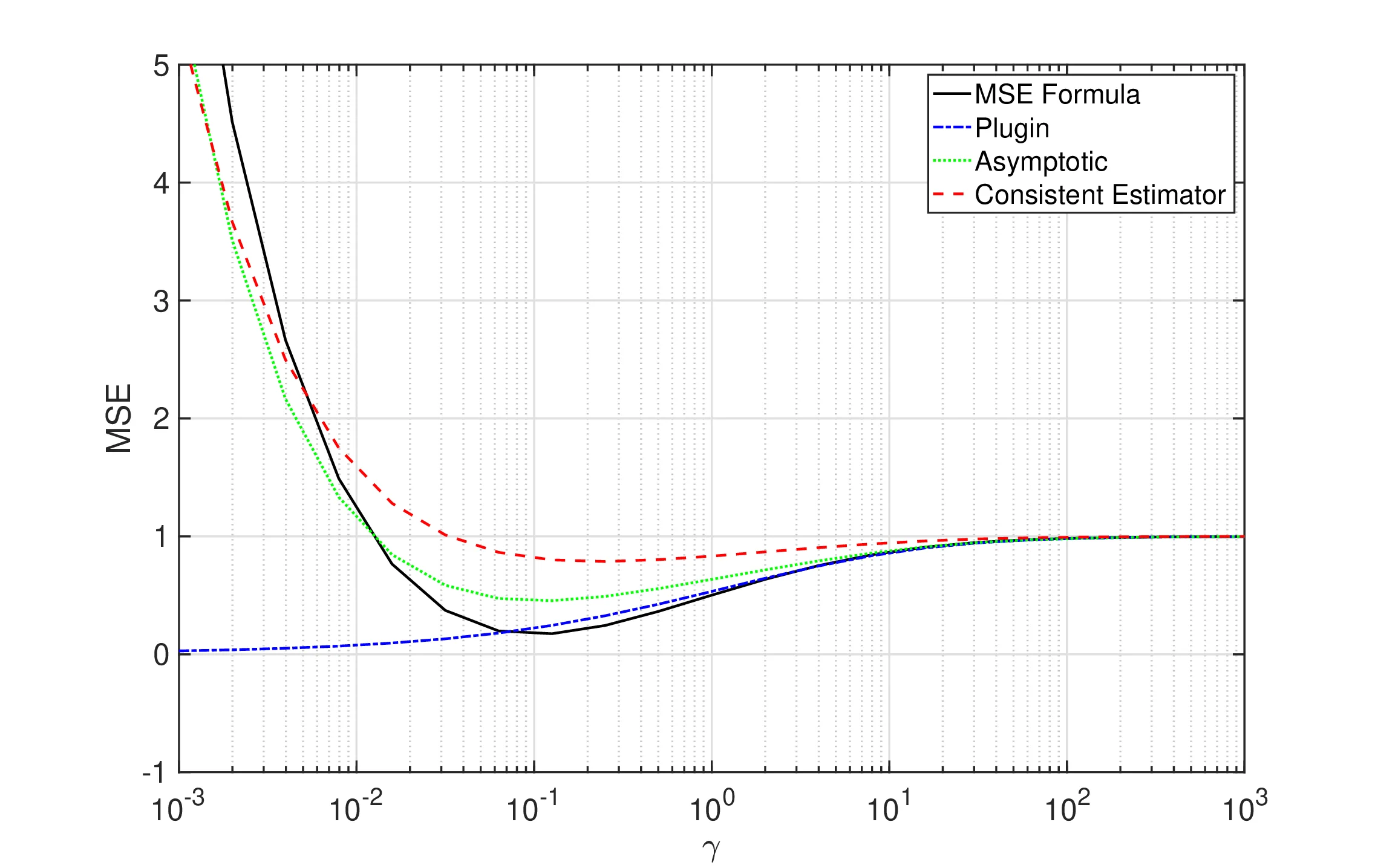
특히 본 논문에서 제안하는 방법은 다른 기존 방법들과 차별화되는 중요한 특징을 가지고 있다. 바로 정규화 파라미터(regularization parameter)의 최적값을 선택하는 기준을 “데이터 평균(mean) 추정의 불확실성을 고려한 잡음 벡터(noise vector) 추정의 평균 제곱 오차(mean‑squared error, 이하 MSE)를 최소화”하는 것으로 설정한다는 점이다. 데이터 평균을 추정할 때 발생하는 오차는 공분산 행렬 추정에도 영향을 미치며, 이 오차를 무시하면 정규화 파라미터가 과소 혹은 과대 선택될 위험이 있다. 따라서 본 연구는 잡음 벡터의 MSE를 명시적으로 모델링하고, 이 MSE를 최소화하는 정규화 파라미터를 찾아내는 절차를 제시한다.
이를 위해 무작위 행렬 이론(random‑matrix‑theory, RMT)의 최신 도구들을 활용한다. RMT는 고차원 데이터의 특성을 확률론적으로 분석하는 강력한 수학적 프레임워크로, 특히 표본 공분산 행렬의 고유값(eigenvalue) 분포와 같은 복잡한 현상을 정확히 기술한다. 본 논문은 RMT를 이용해 “달성 가능한 평균 제곱 오차(achievable MSE)”의 일관된(consistent) 추정량을 유도한다. 이 추정량은 실제 데이터에 대한 복잡한 통계적 계산 없이도, 오직 관측된 표본 공분산 행렬과 선택된 정규화 파라미터만을 입력으로 하여 손쉽게 계산될 수 있다.
도출된 일관 추정량을 활용하면, 정규화 파라미터의 최적값을 찾는 과정이 복잡한 최적화 문제로 전개되지 않는다. 대신, 간단한 1차원 선형 탐색(line search) 절차만으로도 최적 파라미터를 효율적으로 탐색할 수 있다. 구체적으로, 파라미터를 일정 구간 내에서 작은 단계(step)로 증가시키면서 각 단계에서의 추정 MSE를 계산하고, 가장 작은 MSE를 보이는 파라미터 값을 최적값으로 채택한다. 이 과정은 계산량이 적고 구현이 용이하므로, 실제 금융 데이터에 적용할 때 실시간 혹은 대규모 포트폴리오 관리 시스템에도 손쉽게 통합될 수 있다.
마지막으로, 제안된 방법의 실효성을 검증하기 위해 다양한 시뮬레이션 실험을 수행하였다. 실험에서는 데이터 차원(p)와 샘플 수(n)의 비율을 다양하게 설정했으며, 특히 p > n인 경우(데이터 차원이 샘플 수보다 큰 경우)와 p와 n이 동일한 차수(order)로 증가하는 경우를 중점적으로 살펴보았다. 시뮬레이션 결과는 다음과 같은 주요 결론을 보여준다. 첫째, 정규화된 공분산 행렬을 사용함으로써 GMVP 가중치의 추정 정확도가 크게 향상되었으며, 이는 포트폴리오의 실제 위험(variance)이 크게 감소함을 의미한다. 둘째, 제안된 MSE 기반 정규화 파라미터 선택 방법은 기존의 교차 검증(cross‑validation)이나 고정된 파라미터 설정에 비해 일관적으로 더 낮은 추정 오차를 제공하였다. 셋째, 특히 p > n인 극한 상황에서도 제안된 방법은 표본 공분산 행렬이 전혀 역행렬을 갖지 못하는 경우에도 안정적인 가중치 추정을 가능하게 하였으며, 이는 고차원 금융 데이터 분석에 있어 실질적인 활용 가능성을 크게 높인다.
요약하면, 본 논문은 고차원 환경에서 GMVP 가중치를 최적화하기 위한 새로운 정규화 공분산 행렬 추정 방법을 제시하고, 정규화 파라미터를 데이터 평균 추정의 불확실성을 반영한 MSE 최소화 원칙에 따라 선택함으로써 기존 방법들의 한계를 극복하였다. 무작위 행렬 이론을 기반으로 한 일관된 MSE 추정량 도출과 간단한 선형 탐색을 통한 파라미터 최적화는 이론적 엄밀함과 실용적 효율성을 동시에 만족시킨다. 시뮬레이션을 통한 실증 결과는 제안된 방법이 데이터 차원이 샘플 수보다 크거나 동일한 경우에도 높은 성능을 유지함을 입증한다. 따라서 본 연구는 고차원 포트폴리오 최적화 분야에 새로운 분석 도구와 실무적 가이드를 제공하며, 향후 실제 금융 시장에서의 적용 및 확장 가능성을 크게 열어줄 것으로 기대된다.