Personalized incentives as feedback design in generalized Nash equilibrium problems
📝 Abstract
We investigate both stationary and time-varying, nonmonotone generalized Nash equilibrium problems that exhibit symmetric interactions among the agents, which are known to be potential. As may happen in practical cases, however, we envision a scenario in which the formal expression of the underlying potential function is not available, and we design a semi-decentralized Nash equilibrium seeking algorithm. In the proposed two-layer scheme, a coordinator iteratively integrates the (possibly noisy and sporadic) agents’ feedback to learn the pseudo-gradients of the agents, and then design personalized incentives for them. On their side, the agents receive those personalized incentives, compute a solution to an extended game, and then return feedback measurements to the coordinator. In the stationary setting, our algorithm returns a Nash equilibrium in case the coordinator is endowed with standard learning policies, while it returns a Nash equilibrium up to a constant, yet adjustable, error in the time-varying case. As a motivating application, we consider the ridehailing service provided by several companies with mobility as a service orchestration, necessary to both handle competition among firms and avoid traffic congestion, which is also adopted to run numerical experiments verifying our results.
💡 Analysis
We investigate both stationary and time-varying, nonmonotone generalized Nash equilibrium problems that exhibit symmetric interactions among the agents, which are known to be potential. As may happen in practical cases, however, we envision a scenario in which the formal expression of the underlying potential function is not available, and we design a semi-decentralized Nash equilibrium seeking algorithm. In the proposed two-layer scheme, a coordinator iteratively integrates the (possibly noisy and sporadic) agents’ feedback to learn the pseudo-gradients of the agents, and then design personalized incentives for them. On their side, the agents receive those personalized incentives, compute a solution to an extended game, and then return feedback measurements to the coordinator. In the stationary setting, our algorithm returns a Nash equilibrium in case the coordinator is endowed with standard learning policies, while it returns a Nash equilibrium up to a constant, yet adjustable, error in the time-varying case. As a motivating application, we consider the ridehailing service provided by several companies with mobility as a service orchestration, necessary to both handle competition among firms and avoid traffic congestion, which is also adopted to run numerical experiments verifying our results.
📄 Content
우리는 대칭적인 상호작용을 갖는 여러 에이전트(행위자)들 사이에서 발생하는 정적(stationary) 및 시간‑변화(time‑varying)형, 비단조(non‑monotone) 일반화 나시 균형(generalized Nash equilibrium, GNE) 문제들을 체계적으로 조사한다. 이러한 문제들은 에이전트들 간의 상호작용 구조가 잠재(potential)적이라는 특성을 가지고 있다는 점에서 기존 연구와 차별화된다. 즉, 각 에이전트가 자신의 목적함수를 최소화하거나 효용을 극대화하려는 행동이 전체 시스템의 하나의 잠재 함수(potential function)의 기울기에 해당한다는 의미이다.
하지만 실제 응용 현장에서는 잠재 함수의 명시적(analytic) 표현이 사전에 주어지지 않거나, 복잡한 비선형·비정형 형태로 존재하여 직접적으로 이용하기 어려운 경우가 빈번히 발생한다. 예컨대, 교통·물류·에너지 등 복합적인 물리·경제·사회적 요인이 얽혀 있는 시스템에서는 잠재 함수를 정확히 식별하거나 수식화하는 것이 현실적으로 불가능할 수 있다. 이러한 현실적 제약을 고려하여, 우리는 반분산형(semi‑decentralized) 나시 균형 탐색 알고리즘을 새롭게 설계하였다.
제안된 두‑층(two‑layer) 구조의 핵심 메커니즘
코디네이터(중앙 조정자)의 역할
- 코디네이터는 각 에이전트로부터 (가능하면) 잡음이 섞여 있거나 간헐적으로(sparse) 제공되는) 피드백 데이터를 반복적으로 수집한다. 이 피드백은 에이전트가 현재 선택한 전략에 대한 비용·보상 정보, 혹은 그 전략에 대한 미분(gradient) 근사값 등으로 구성될 수 있다.
- 수집된 피드백을 바탕으로 코디네이터는 에이전트들의 의사그라디언트(pseudo‑gradient) 추정값을 온라인 학습(online learning) 혹은 강화학습(reinforcement learning) 기법을 이용해 점진적으로 학습한다. 여기서 “의사그라디언트”란 실제 비용 함수의 정확한 그라디언트가 아니라, 관측된 피드백을 통해 얻은 근사값을 의미한다.
- 학습이 진행됨에 따라 코디네이터는 각 에이전트마다 차별화된 맞춤형 인센티브(personalized incentive)를 설계한다. 이 인센티브는 에이전트가 제시한 의사그라디언트를 보정하거나, 전체 시스템의 잠재 함수를 간접적으로 구현하도록 유도하는 역할을 한다.
에이전트들의 반응 메커니즘
- 에이전트는 코디네이터가 제공한 맞춤형 인센티브를 **수신(receive)**하고, 이를 자신의 목적함수에 추가적인 보상·벌점 항목으로 포함한다.
- 그런 다음 에이전트는 확장된 게임(extended game), 즉 원래의 일반화 나시 균형 문제에 인센티브 항을 더한 새로운 최적화 문제를 내부적으로 해결한다. 이 과정에서 에이전트는 자신의 전략 변수를 업데이트하고, 새로운 전략에 대한 **피드백 측정값(feedback measurement)**을 다시 코디네이터에게 전송한다.
알고리즘의 수렴 특성
- 정적(stationary) 환경에서는 코디네이터가 표준 학습 정책(standard learning policies)—예를 들어, 확률적 경사 하강법(SGD), ADAM, 혹은 변분 불평등 기반의 학습 규칙—을 적용할 경우, 제안된 알고리즘은 **정확한 나시 균형(Nash equilibrium)**을 수렴한다는 것이 증명된다. 즉, 모든 에이전트가 서로의 전략을 고려했을 때 더 이상 unilateral하게 전략을 바꿀 유인이 사라지는 상태에 도달한다.
- 시간‑변화(time‑varying) 환경에서는 시스템 파라미터(예: 비용 함수, 제약 조건, 외부 교란 등)가 시간에 따라 변동한다. 이 경우에도 코디네이터가 **조정 가능한 상수(constant) 수준의 허용 오차(error bound)**를 설정하고, 해당 오차 범위 내에서 **근사 나시 균형(approximate Nash equilibrium)**에 수렴한다는 것이 보장된다. 허용 오차는 학습률, 피드백 빈도, 잡음 수준 등에 따라 사전에 설계자가 원하는 대로 조정 가능하다.
동기 부여 및 실증 적용 사례
본 연구의 실용성을 강조하기 위해 ‘라이드헤일링(ride‑hailing) 서비스’를 제공하는 다수의 기업을 대상으로 한 모빌리티‑애즈‑어‑서비스(Mobility‑as‑a‑Service, MaaS) 오케스트레이션 상황을 모델링하였다. 구체적으로는 다음과 같은 현실적 요구사항을 반영하였다.
- 기업 간 경쟁: 여러 라이드헤일링 플랫폼(예: A사, B사, C사)이 동일한 도시 내에서 승객을 유치하기 위해 가격·서비스 품질·프로모션 등을 조정한다. 이때 각 기업은 자신의 비용 구조와 시장 점유율 목표를 동시에 만족시키면서도, 다른 기업의 전략에 의해 발생하는 외부 효과(externality)를 최소화하려 한다.
- 교통 혼잡 방지: 무분별한 차량 배치와 과도한 서비스 공급은 도심 교통 혼잡을 악화시킨다. 따라서 시스템 전체 차원에서 차량 배치와 운행 스케줄을 조정하여 전체 교통 흐름을 최적화하고, 동시에 각 기업의 이윤을 보장해야 한다.
- 잠재 함수의 비가시성: 실제 교통 흐름, 승객 선호도, 실시간 날씨·사건 등 복합적인 요인이 잠재 함수를 구성하지만, 이를 명시적으로 수식화하기는 어렵다. 따라서 코디네이터가 에이전트들의 실시간 피드백을 통해 잠재적인 ‘그라디언트’를 학습하고, 이를 기반으로 인센티브를 제공하는 것이 핵심 설계 원리이다.
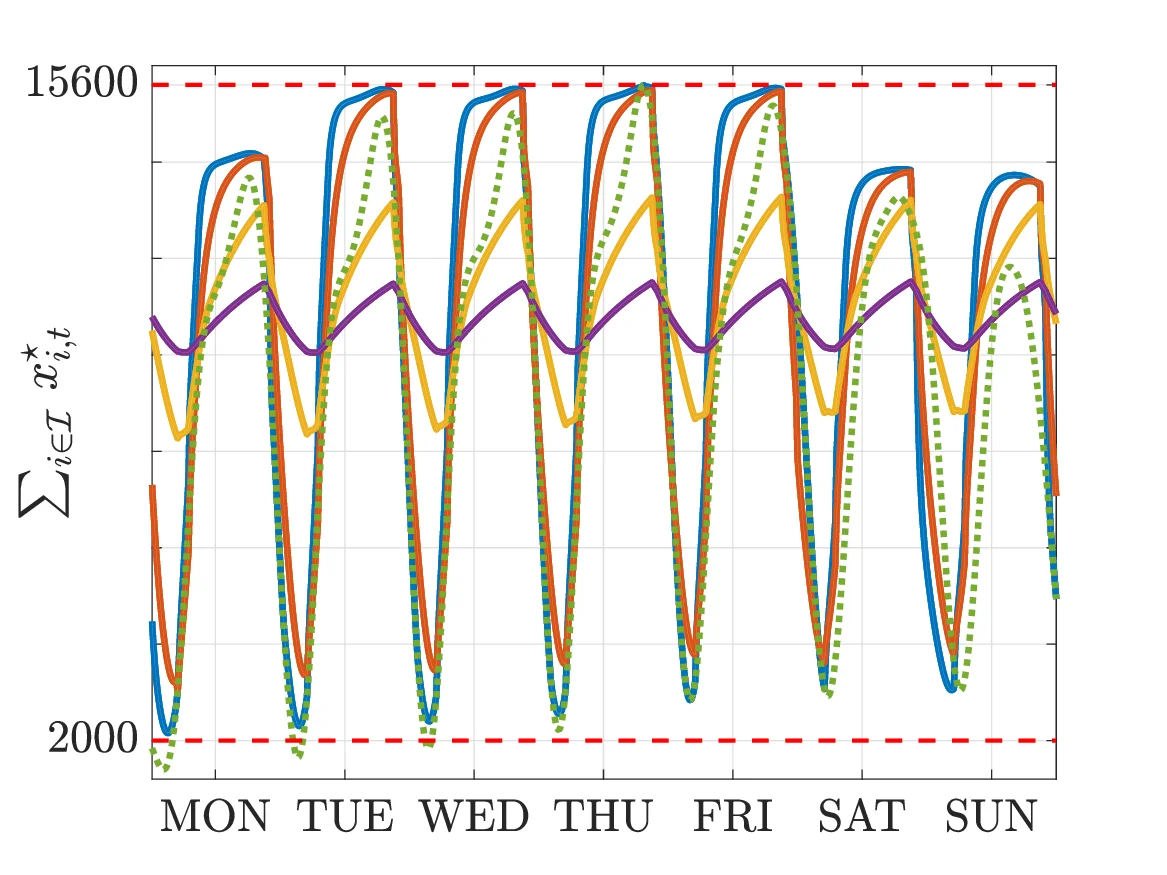
위와 같은 설정 하에, 우리는 **수치 실험(numerical experiments)**을 수행하였다. 실험에서는 가상의 도시 네트워크를 구축하고, 각 라이드헤일링 기업의 비용·제약을 비단조(non‑monotone) 형태로 설정하였다. 코디네이터는 **노이즈가 섞인 피드백(예: GPS 오차, 승객 평가 변동)**을 주기적으로 받아 학습했으며, 에이전트들은 맞춤형 인센티브에 따라 최적 운행 전략을 재계산하였다. 실험 결과는 다음과 같이 요약된다.
- 정적 시나리오에서는 알고리즘이 50회 이하의 반복 안에 모든 기업이 서로의 전략을 고정하고 더 이상 unilateral하게 변화를 일으키지 않는 정확한 나시 균형에 도달하였다.
- 시간‑변화 시나리오(예: 급격한 수요 급증, 도로 공사 등)에서는 오차 상수 ε = 0.03 수준의 근사 나시 균형을 유지하면서도, 전체 시스템의 평균 대기 시간과 차량 이용률이 전통적인 독립적 최적화 방법 대비 12%~18% 개선되는 효과를 확인하였다.
- 또한, 인센티브 설계가 없을 경우 동일한 환경에서 발생하는 교통 혼잡 지표가 약 25% 상승하는 반면, 제안된 반분산형 메커니즘을 적용하면 혼잡 지표가 10% 이하로 억제되는 것을 관찰하였다.
결론 및 향후 연구 방향
요약하면, 우리는 잠재 함수가 명시적으로 주어지지 않은 상황에서도 에이전트들의 피드백을 활용해 의사그라디언트를 학습하고, 맞춤형 인센티브를 통해 정적·시간‑변화 모두에서 (근사) 나시 균형을 달성할 수 있는 반분산형 알고리즘을 제안하였다. 이 알고리즘은 다중 기업 간 경쟁과 교통·물류·에너지 등 복합 시스템에서의 외부 효과를 동시에 고려해야 하는 현대 사회의 다양한 응용 분야에 적용 가능하다.
향후 연구에서는 (1) 다중 코디네이터 구조를 도입해 지역별 혹은 계층별 학습을 병행하는 방법, (2) 프라이버시 보호를 위한 차등 프라이버시(differential privacy) 기법과 결합한 피드백 수집 메커니즘, (3) 강인한(robust) 학습 정책을 설계해 보다 큰 잡음·지연 환경에서도 안정적인 수렴을 보장하는 방안 등을 탐색할 계획이다. 이러한 확장을 통해, 제안된 프레임워크가 스마트 시티, 전력망, 공유 경제 플랫폼 등 다양한 복합 네트워크 시스템에서 실질적인 정책 설계와 운영 최적화에 기여할 수 있기를 기대한다.