Evolution of HEP Processing Frameworks
HEP data-processing software must support the disparate physics needs of many experiments. For both collider and neutrino environments, HEP experiments typically use data-processing frameworks to manage the computational complexities of their large-scale data processing needs. Data-processing frameworks are being faced with new challenges this decade. The computing landscape has changed from the past three decades of homogeneous single-core x86 batch jobs running on grid sites. Frameworks must now work on a heterogeneous mixture of different platforms: multi-core machines, different CPU architectures, and computational accelerators; and different computing sites: grid, cloud, and high-performance computing. We describe these challenges in more detail and how frameworks may confront them. Given their historic success, frameworks will continue to be critical software systems that enable HEP experiments to meet their computing needs. Frameworks have weathered computing revolutions in the past; they will do so again with support from the HEP community
💡 Research Summary
The paper provides a comprehensive review of the challenges facing High‑Energy Physics (HEP) data‑processing frameworks as the computing ecosystem evolves from a homogeneous, single‑core x86 grid to a heterogeneous landscape that includes many‑core CPUs, ARM processors, GPUs, FPGAs, and a mixture of execution sites such as traditional grid farms, high‑performance computing (HPC) centers, and commercial clouds.
It begins by defining a “framework” as the software layer that orchestrates simulation, reconstruction, and data‑product generation, offering services such as user‑algorithm scheduling, provenance tracking, dataset organization, and event‑loop control. These capabilities have become indispensable for physicists, embedding the framework deeply into the experiment’s software stack.
The authors then examine three parallel‑processing models. The multithreaded model runs many threads within a single process, sharing memory and thus reducing overall memory footprints, but it introduces synchronization complexities (race conditions, deadlocks). The multiprocess model isolates memory per process, avoiding thread‑safety issues, yet incurs higher inter‑process communication costs and can lead to larger memory usage if immutable data are duplicated. A hybrid approach combines the two, allowing a main multithreaded application to launch external single‑threaded processes (e.g., Monte‑Carlo generators) as tasks, thereby exploiting both thread‑level parallelism for safe code and process‑level isolation for legacy or non‑thread‑safe components. The paper cites concrete examples from ATLAS, CMS, LHCb, ALICE, Mu2e, GlueX, and Jefferson Lab, illustrating how each experiment has adopted or is exploring these models.
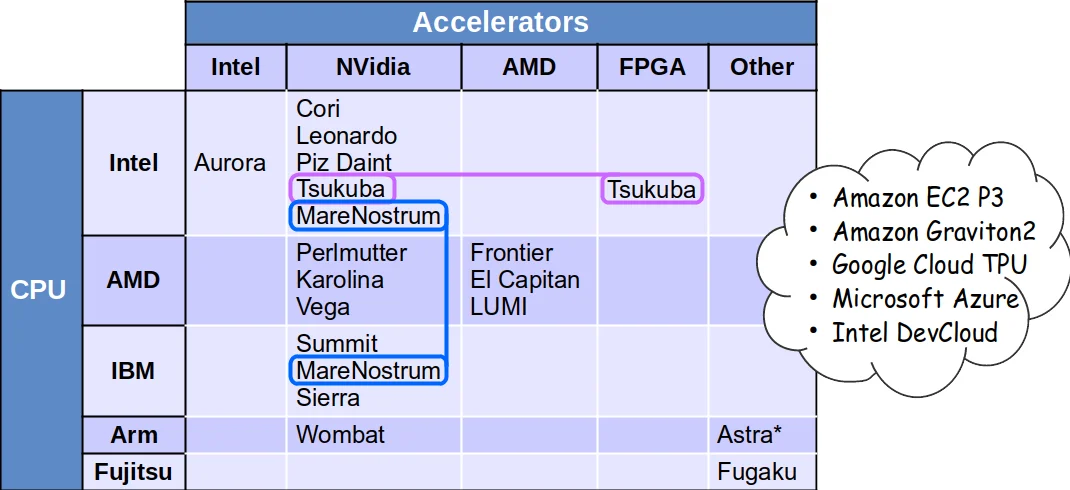
Next, the paper discusses the shift in CPU architectures. The dominance of Intel‑compatible x86 CPUs is waning as HPC facilities adopt energy‑efficient alternatives: ARM‑based low‑power CPUs, AMD GPUs, and heterogeneous chiplet designs that integrate CPUs with accelerators. This diversification raises two major issues for frameworks: (1) ensuring numerical reproducibility across architectures, especially for floating‑point operations, and (2) managing a proliferation of binary builds. Three mitigation strategies are evaluated: “fat binaries” that embed multiple code variants and select the appropriate one at runtime; “selective optimization” that compiles only the most performance‑critical components for each architecture; and “on‑site builds” that compile directly on the target machine. The authors note that each strategy brings trade‑offs in storage, distribution complexity, and validation effort.
The section on computational accelerators highlights the growing prevalence of GPUs and, to a lesser extent, FPGAs. While they promise superior energy efficiency and raw throughput, integrating them into existing HEP workflows is non‑trivial. Challenges include scheduling work across CPUs and accelerators, handling data movement between host and device memory, and supporting multiple programming models (CUDA, HIP, OpenCL, SYCL, etc.). The paper also points out that I/O bottlenecks can limit scaling; for example, CMS observed a drop in CPU efficiency beyond eight threads due to sequential ROOT I/O calls. Ongoing DOE CCE research aims to develop more concurrent I/O mechanisms, but further work is required.
Finally, the authors analyze the three major categories of compute sites. Traditional grid sites excel at large‑scale batch processing with long‑running jobs, making them well‑matched to existing frameworks. HPC centers provide massive parallelism, high‑speed interconnects, and often require checkpoint/restart capabilities because pre‑emptible allocations are common. Commercial clouds offer on‑demand elasticity and short‑lived instances, demanding that frameworks support rapid job termination, periodic result checkpointing, and possibly stateless execution. To operate efficiently across all these environments, frameworks must expose a hardware‑agnostic abstraction layer while allowing site‑specific plug‑ins for scheduling, resource management, and data handling.
In conclusion, the paper argues that HEP frameworks have successfully navigated past revolutions (e.g., the transition from single‑core to multi‑core) and will need to continue evolving through modular design, standardized interfaces, automated build‑test‑validation pipelines, and sophisticated runtime schedulers that can orchestrate heterogeneous resources. By investing in these research and development directions, the community can ensure that data‑processing frameworks remain robust, scalable, and scientifically productive throughout the coming decade of diverse computing architectures.
Comments & Academic Discussion
Loading comments...
Leave a Comment