A Feasibility Study of Answer-Agnostic Question Generation for Education
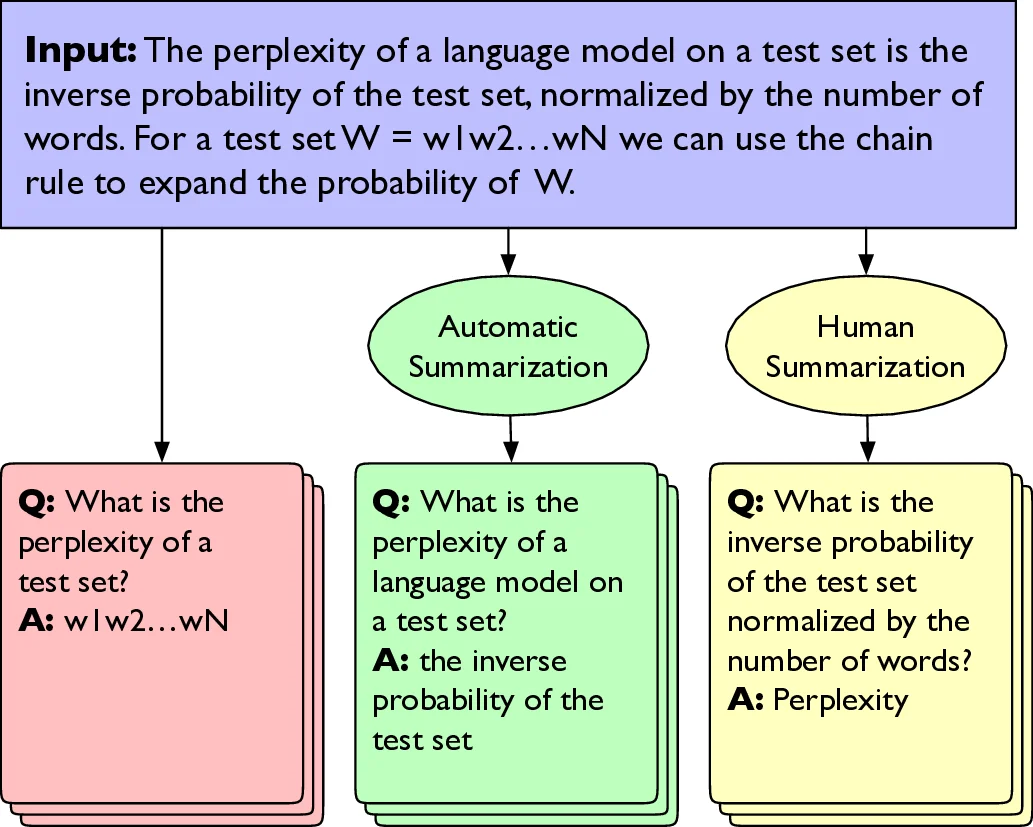
We conduct a feasibility study into the applicability of answer-agnostic question generation models to textbook passages. We show that a significant portion of errors in such systems arise from asking irrelevant or uninterpretable questions and that such errors can be ameliorated by providing summarized input. We find that giving these models human-written summaries instead of the original text results in a significant increase in acceptability of generated questions (33% $\rightarrow$ 83%) as determined by expert annotators. We also find that, in the absence of human-written summaries, automatic summarization can serve as a good middle ground.
💡 Research Summary
This paper investigates the feasibility of applying answer‑agnostic question generation (QG) models to textbook passages, focusing on the educational context where manually selecting answer spans is impractical. Traditional QG research has largely relied on answer‑aware models that require explicit answer span annotation, which adds overhead and limits scalability for educators. The authors adopt an answer‑agnostic approach, wherein a single T5‑base language model is fine‑tuned jointly on three tasks: answer extraction, question generation, and question answering. Answer extraction is performed by highlighting sentence boundaries and extracting at most one answer span per sentence; the extracted span then serves as input to the answer‑aware question generation component.
The central hypothesis is that providing a summarized version of the input passage—either human‑written or automatically generated—will improve the model’s ability to select salient answer candidates and consequently produce more relevant, interpretable, and usable questions. To test this, the authors use three chapters (2‑4) from Jurafsky & Martin’s “Speech and Language Processing” textbook. They create three experimental conditions: (1) raw textbook text, (2) human‑authored abstracts written by three research assistants, and (3) automatically generated summaries produced by a BART‑large model fine‑tuned on CNN/DailyMail. The human summaries were intentionally crafted for readability rather than machine‑friendliness, while the automatic summaries reflect a realistic, low‑cost alternative.
Across the three conditions, the model generates 1,208 question‑answer (QA) pairs from raw text, 667 pairs from human summaries, and 318 pairs from automatic summaries. For evaluation, 100 QA pairs are randomly sampled from each condition, yielding a balanced set of 300 items. Three annotators (the same research assistants) assess each item on five binary criteria: Acceptability (could be used directly as a flashcard), Grammaticality, Interpretability (makes sense out of context), Relevance (pertains to the chapter’s topic), and Correctness of the answer. Detailed annotation guidelines and examples are provided to ensure consistency.
Results show a dramatic improvement when human summaries are used: Acceptability rises from 33 % (raw text) to 83 %; Relevance from 61 % to 95 %; Interpretability from 56 % to 94 %; and Grammaticality remains high (≈98 %). Automatic summaries also improve over raw text, achieving 74 % Acceptability, 78 % Relevance, and 83 % Interpretability, though grammaticality drops slightly to around 90 %. Coverage analysis—searching for bolded key terms from the textbook within generated QA pairs—reveals that human summaries achieve both high precision and high recall, raw text yields high recall but low precision, and automatic summaries strike a middle ground.
Inter‑annotator agreement, measured with pairwise Cohen’s κ, is modest for the more subjective dimensions (≈0.4 for Relevance, Interpretability, and Acceptability), indicating fair but not perfect consensus, while agreement on Grammaticality and Correctness is low due to class imbalance. The authors note that the answer extraction component often selects irrelevant or ambiguous spans when applied to textbook material, which explains the prevalence of irrelevant or uninterpretable questions in the raw‑text condition.
The study concludes that summarization—especially human‑crafted—substantially mitigates the primary failure modes of answer‑agnostic QG in educational settings. Automatic summarization, while not matching human performance, still offers a practical compromise. Limitations include the model’s tendency to extract the same answer span repeatedly from a sentence, the limited size of the evaluation set, and the reliance on a single textbook domain.
Future work is outlined as follows: (1) integrate summarization and question generation into a unified end‑to‑end architecture that can learn to produce summaries optimized for downstream QG; (2) conduct longitudinal studies measuring the impact of generated flashcards on student learning outcomes; (3) develop more nuanced automatic evaluation metrics that capture relevance and interpretability beyond n‑gram overlap, addressing the known weak correlation between BLEU/ROUGE and human judgments in QG. The authors also reference concurrent work by Liu et al. (2021) that shows training QG models on synthetic data derived from summaries can further boost downstream QA performance. Overall, the paper provides strong empirical evidence that a simple preprocessing step—summarization—can transform answer‑agnostic QG from a research curiosity into a viable tool for educators.
Comments & Academic Discussion
Loading comments...
Leave a Comment