Quantifying the Burden of Exploration and the Unfairness of Free Riding
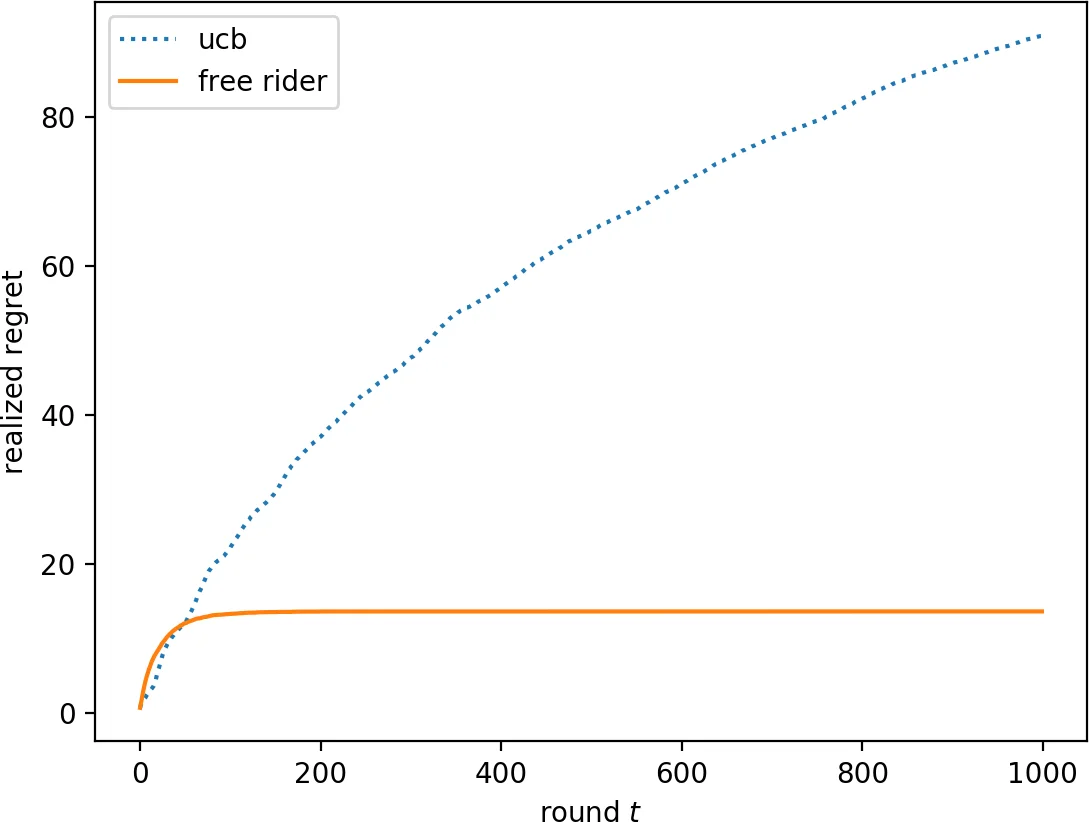
We consider the multi-armed bandit setting with a twist. Rather than having just one decision maker deciding which arm to pull in each round, we have $n$ different decision makers (agents). In the simple stochastic setting, we show that a “free-riding” agent observing another “self-reliant” agent can achieve just $O(1)$ regret, as opposed to the regret lower bound of $\Omega (\log t)$ when one decision maker is playing in isolation. This result holds whenever the self-reliant agent’s strategy satisfies either one of two assumptions: (1) each arm is pulled at least $\gamma \ln t$ times in expectation for a constant $\gamma$ that we compute, or (2) the self-reliant agent achieves $o(t)$ realized regret with high probability. Both of these assumptions are satisfied by standard zero-regret algorithms. Under the second assumption, we further show that the free rider only needs to observe the number of times each arm is pulled by the self-reliant agent, and not the rewards realized. In the linear contextual setting, each arm has a distribution over parameter vectors, each agent has a context vector, and the reward realized when an agent pulls an arm is the inner product of that agent’s context vector with a parameter vector sampled from the pulled arm’s distribution. We show that the free rider can achieve $O(1)$ regret in this setting whenever the free rider’s context is a small (in $L_2$-norm) linear combination of other agents’ contexts and all other agents pull each arm $\Omega (\log t)$ times with high probability. Again, this condition on the self-reliant players is satisfied by standard zero-regret algorithms like UCB. We also prove a number of lower bounds.
💡 Research Summary
The paper studies multi‑armed bandit problems in a setting where multiple agents act simultaneously rather than a single decision‑maker. The central question is how a “free‑riding” agent—one that can observe the actions (and possibly rewards) of other, self‑reliant agents—can dramatically reduce its own exploration cost. The authors show that, under fairly mild conditions that are satisfied by any standard zero‑regret algorithm (e.g., UCB, Thompson sampling), a free rider can achieve a cumulative regret that remains bounded by a constant (O(1)) even as the horizon T grows arbitrarily large.
Stochastic Bandits
Two sufficient conditions are identified. (1) If at least one self‑reliant agent pulls each arm at least γ·ln t times in expectation for all sufficiently large t, then the free rider can simply reuse the samples collected by that agent to estimate each arm’s mean. Because the sample size grows logarithmically, the estimation error shrinks fast enough that the free rider’s regret stays bounded. The constant γ is derived explicitly from the confidence‑bound parameter of the underlying algorithm (e.g., the α in α‑UCB). (2) If a self‑reliant agent achieves o(t) realized regret with high probability, the free rider does not even need to see the actual reward values; knowing only how many times each arm was selected suffices to construct a high‑quality estimate. This yields O(1) regret even in a partial‑information model where only actions are observable. Both conditions are satisfied by any algorithm that guarantees sub‑linear regret, such as UCB, Thompson sampling, or a round‑robin followed by exploitation phase.
Lower Bounds on Exploration
The authors also prove that any policy achieving O(T^{1‑ε}) regret must sample every sub‑optimal arm at least Ω(log T) times in expectation (Theorem 3) and, with high probability, must not sample any arm fewer than a logarithmic number of times (Theorem 4). Moreover, a deterministic lower bound (Theorem 5) shows that UCB necessarily pulls each arm Ω(log t) times. These results formalize the intuition that a certain amount of exploration is unavoidable for any low‑regret learner, and they provide the quantitative foundation for the free‑rider’s advantage.
Linear Contextual Bandits
The model is extended to linear contextual bandits where each arm i is associated with a distribution over parameter vectors θ_i, each agent p has a fixed context vector x_p, and the reward is ⟨x_p, θ_i⟩. The free rider can achieve O(1) regret if (i) its context can be expressed as a small‑norm linear combination of the other agents’ contexts, and (ii) every other agent pulls each arm at least Ω(log t) times with high probability. This mirrors the stochastic case: sufficient exploration by the observed agents together with a “similar” context enables the free rider to reconstruct accurate reward estimates without performing its own exploration.
Information Requirements
The paper further establishes that achieving sub‑logarithmic regret in the contextual setting requires full information: the free rider must know both the other agents’ contexts and the realized rewards (Theorems 10 and 11). If only actions are observed, the best achievable regret remains Ω(log t).
Practical Implications
The authors illustrate the relevance of their model with examples such as pharmaceutical firms sharing trial results, public restaurant‑review platforms (e.g., Yelp), and online advertising where competitors’ impressions and clicks can be monitored. In all these cases, a participant that can “free‑ride” on the exploratory efforts of others can dramatically cut its own cost, raising fairness concerns. The paper connects to recent work on algorithmic fairness in bandits, showing that the distribution of exploration cost can be highly asymmetric.
Conclusion
Overall, the work provides a rigorous quantification of the “burden of exploration” in multi‑agent bandits and demonstrates that free‑riding can reduce this burden to a constant under realistic assumptions. It also delineates the precise conditions—logarithmic exploration by observed agents and sufficient information sharing—under which such dramatic gains are possible, and it proves that without these conditions the free rider cannot escape the usual Ω(log t) regret lower bound. These insights are valuable for designing mechanisms that either mitigate free‑riding (e.g., by limiting information flow) or exploit it (e.g., by aggregating data from multiple users to accelerate learning).
Comments & Academic Discussion
Loading comments...
Leave a Comment