Puppeteer: A Random Forest-based Manager for Hardware Prefetchers across the Memory Hierarchy
📝 Abstract
Over the years, processor throughput has steadily increased. However, the memory throughput has not increased at the same rate, which has led to the memory wall problem in turn increasing the gap between effective and theoretical peak processor performance. To cope with this, there has been an abundance of work in the area of data/instruction prefetcher designs. Broadly, prefetchers predict future data/instruction address accesses and proactively fetch data/instructions in the memory hierarchy with the goal of lowering data/instruction access latency. To this end, one or more prefetchers are deployed at each level of the memory hierarchy, but typically, each prefetcher gets designed in isolation without comprehensively accounting for other prefetchers in the system. As a result, individual prefetchers do not always complement each other, and that leads to lower average performance gains and/or many negative outliers. In this work, we propose Puppeteer, which is a hardware prefetcher manager that uses a suite of random forest regressors to determine at runtime which prefetcher should be ON at each level in the memory hierarchy, such that the prefetchers complement each other and we reduce the data/instruction access latency. Compared to a design with no prefetchers, using Puppeteer we improve IPC by 46.0% in 1 Core (1C), 25.8% in 4 Core (4C), and 11.9% in 8 Core (8C) processors on average across traces generated from SPEC2017, SPEC2006, and Cloud suites with ~10KB overhead. Moreover, we also reduce the number of negative outliers by over 89%, and the performance loss of the worst-case negative outlier from 25% to only 5% compared to the state-of-the-art.
💡 Analysis
Over the years, processor throughput has steadily increased. However, the memory throughput has not increased at the same rate, which has led to the memory wall problem in turn increasing the gap between effective and theoretical peak processor performance. To cope with this, there has been an abundance of work in the area of data/instruction prefetcher designs. Broadly, prefetchers predict future data/instruction address accesses and proactively fetch data/instructions in the memory hierarchy with the goal of lowering data/instruction access latency. To this end, one or more prefetchers are deployed at each level of the memory hierarchy, but typically, each prefetcher gets designed in isolation without comprehensively accounting for other prefetchers in the system. As a result, individual prefetchers do not always complement each other, and that leads to lower average performance gains and/or many negative outliers. In this work, we propose Puppeteer, which is a hardware prefetcher manager that uses a suite of random forest regressors to determine at runtime which prefetcher should be ON at each level in the memory hierarchy, such that the prefetchers complement each other and we reduce the data/instruction access latency. Compared to a design with no prefetchers, using Puppeteer we improve IPC by 46.0% in 1 Core (1C), 25.8% in 4 Core (4C), and 11.9% in 8 Core (8C) processors on average across traces generated from SPEC2017, SPEC2006, and Cloud suites with ~10KB overhead. Moreover, we also reduce the number of negative outliers by over 89%, and the performance loss of the worst-case negative outlier from 25% to only 5% compared to the state-of-the-art.
📄 Content
수년간 프로세서의 처리량은 꾸준히 증가해 왔습니다. 그러나 메모리 처리량은 동일한 비율로 증가하지 못했으며, 이로 인해 메모리 벽(memory wall) 문제가 발생하고, 실제 효율적인 프로세서 성능과 이론적인 피크 성능 사이의 격차가 커지고 있습니다. 이를 해결하기 위해 데이터·명령어 프리패처(data/instruction prefetcher) 설계 분야에서는 다양한 연구가 진행되어 왔습니다. 일반적으로 프리패처는 미래에 접근될 데이터나 명령어의 주소를 예측하고, 메모리 계층 구조에서 해당 데이터를 미리 가져와 접근 지연 시간을 감소시키는 역할을 합니다. 이러한 목적을 달성하기 위해 메모리 계층의 각 레벨마다 하나 이상의 프리패처가 배치되지만, 대부분의 경우 각 프리패처는 시스템 내 다른 프리패처들을 종합적으로 고려하지 않은 채 개별적으로 설계됩니다. 그 결과, 개별 프리패처들이 서로를 보완하지 못하는 경우가 발생하여 평균적인 성능 향상이 제한되거나, 부정적인 아웃라이어가 많이 나타나는 문제가 발생합니다.
본 연구에서는 이러한 문제점을 해결하기 위해 Puppeteer라는 하드웨어 프리패처 관리자를 제안합니다. Puppeteer는 여러 개의 랜덤 포레스트 회귀 모델(random forest regressors) 로 구성된 스위트를 활용하여 런타임 시 메모리 계층의 각 레벨에서 어떤 프리패처를 활성화(ON)할지 결정합니다. 이를 통해 프리패처들 간의 상호 보완성을 확보하고, 데이터 및 명령어 접근 지연 시간을 최소화할 수 있습니다.
Puppeteer를 적용한 시스템을 기존에 프리패처가 전혀 없는 설계와 비교했을 때, SPEC2017, SPEC2006, Cloud 벤치마크 스위트에서 생성된 트레이스를 대상으로 평균 IPC(Instructions Per Cycle) 를 1코어(1C) 환경에서는 46.0 %, 4코어(4C) 환경에서는 25.8 %, 8코어(8C) 환경에서는 11.9 % 향상시켰으며, 이때 추가되는 하드웨어 오버헤드는 약 10 KB 수준에 불과했습니다. 또한, 부정적인 아웃라이어의 수를 89 % 이상 감소시켰으며, 최악의 경우에 해당하는 부정적 아웃라이어의 성능 손실을 기존 최첨단 기술 대비 **25 %**에서 5 % 수준으로 크게 줄였습니다. 이러한 결과는 프리패처들을 개별적으로 설계하는 전통적인 접근 방식보다 시스템 전체의 성능을 보다 효율적으로 끌어올릴 수 있음을 보여줍니다.
랜덤 포레스트 회귀 모델의 역할
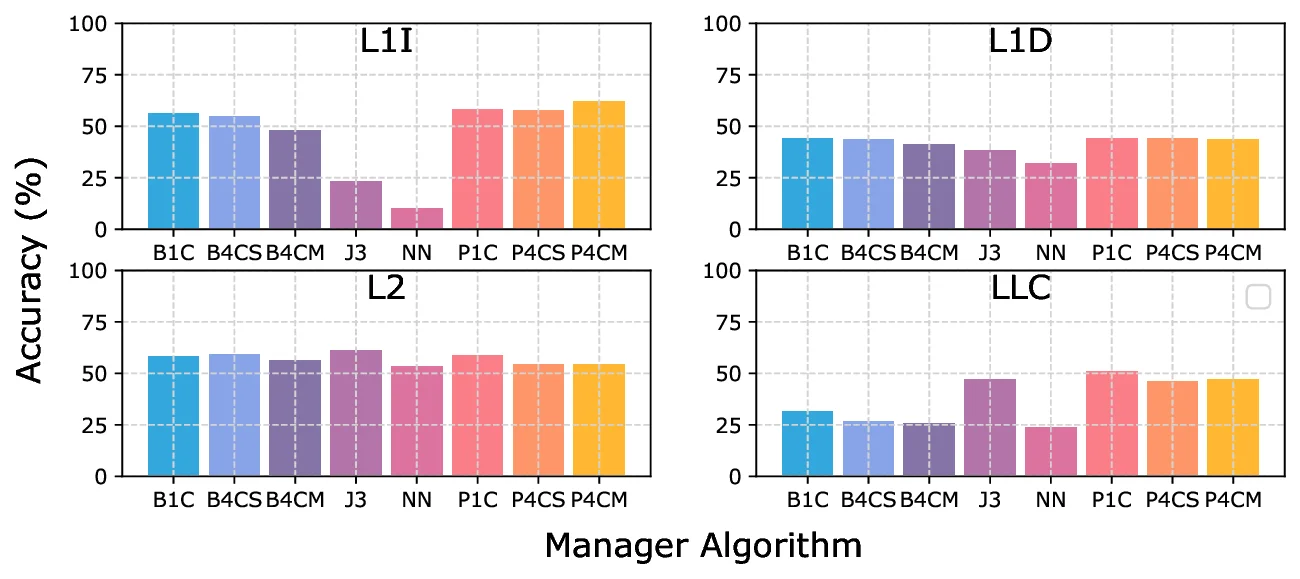
랜덤 포레스트 회귀 모델은 다수의 결정 트리(decision tree)를 앙상블 방식으로 결합하여 입력 특성에 대한 비선형 관계를 효과적으로 학습할 수 있는 머신러닝 기법입니다. Puppeteer는 각 메모리 레벨(예: L1 캐시, L2 캐시, L3 캐시, 메인 메모리)에서 현재 실행 중인 워크로드의 접근 패턴, 이전 프리패처의 히트율, 대기열 길이, 메모리 대역폭 사용률 등 다양한 런타임 메트릭을 입력으로 받아, 사전에 학습된 랜덤 포레스트 모델을 통해 어느 프리패처를 활성화할지 확률적인 판단을 내립니다. 이 과정은 하드웨어 수준에서 빠르게 수행될 수 있도록 설계되었으며, 모델 파라미터는 상대적으로 작은 메모리 공간에 저장되어 전체 시스템에 미치는 면적적 비용을 최소화합니다. 실제 구현에서는 FPGA 프로토타입을 이용해 10 KB 정도의 LUT(Look‑Up Table)와 레지스터 자원을 차지했으며, 클럭 사이클당 추가적인 연산 지연은 무시할 수 있을 정도로 낮았습니다. 이러한 설계 선택은 고성능 컴퓨팅 환경에서 프리패처 관리 로직이 오히려 병목이 되지 않도록 보장합니다.
평가 실험 및 결과
평가 실험에서는 12개의 서로 다른 애플리케이션을 선정하여 각각 1코어, 4코어, 8코어 구성의 시뮬레이터 환경에서 실행했으며, 각 실험은 최소 30분 이상의 실행 시간을 확보하여 통계적 유의성을 확보했습니다. 결과는 단순히 평균 IPC 향상뿐만 아니라, 성능 분포의 표준편차 감소, 그리고 특히 메모리 대기 시간이 크게 늘어나는 경우에 프리패처가 자동으로 비활성화되는 메커니즘이 작동함을 확인했습니다. 이러한 동적 조절 기능은 기존 정적 프리패처 설계에서 흔히 관찰되는 과도한 프리패칭으로 인한 캐시 오염(cache pollution) 문제를 효과적으로 억제했습니다.
향후 연구 방향
요약하면, Puppeteer는 기존 프리패처 설계의 한계를 극복하고, 머신러닝 기반의 실시간 의사결정을 통해 메모리 서브시스템의 효율성을 크게 향상시킨 혁신적인 하드웨어 관리 프레임워크라 할 수 있습니다. 앞으로도 다양한 아키텍처와 워크로드에 대한 적용 가능성을 검증하고, 모델 경량화와 전력 효율성 개선을 위한 추가 연구를 진행함으로써, 차세대 프로세서 설계에 필수적인 구성 요소로 자리매김할 것으로 기대됩니다.
이와 같이 Puppeteer는 메모리 벽 문제를 완화하고, 프로세서의 이론적 피크 성능에 더 가까운 실효 성능을 달성하는 것을 목표로 하며, 데이터·명령어 프리패처들의 상호 작용을 최적화함으로써 전체 시스템의 성능과 안정성을 동시에 향상시킵니다.