The Effects of Data Quality on the Analysis of Corporate Board Interlock Networks
Nowadays, social networks of ever increasing size are studied by researchers from a range of disciplines. The data underlying these networks is often automatically gathered from API’s, websites or existing databases. As a result, the quality of this data is typically not manually validated, and the resulting networks may be based on false, biased or incomplete data. In this paper, we investigate the effect of data quality issues on the analysis of large networks. We focus on the global board interlock network, in which nodes represent firms across the globe, and edges model social ties between firms – shared board members holding a position at both firms. First, we demonstrate how we can automatically assess the completeness of a large dataset of 160 million firms, in which data is missing not at random. Second, we present a novel method to increase the accuracy of the entries in our data. By comparing the expected and empirical characteristics of the resulting network topology, we develop a technique that automatically prunes and merges duplicate nodes and edges. Third, we use a case study of the board interlock network of Sweden to show how poor quality data results in incorrect network topologies, biased centrality values and abnormal influence spread under a well-known diffusion model. Finally, we demonstrate how our data quality assessment methods help restore the correct network structure, ultimately allowing us to derive meaningful and correct results from analyzing the network.
💡 Research Summary
The paper investigates how data quality issues affect the analysis of large corporate board‑interlock networks. Using a snapshot of the Orbis database (≈160 million firms, 90 million directors) the authors first address data completeness. They demonstrate that the dataset suffers from missing‑not‑at‑random (MNAR) bias, especially for small firms in many countries. To quantify this bias they model firm size (revenue) as a log‑normal distribution, calibrate the scale parameter σ≈2.0 from high‑quality countries, and estimate the location parameter μ for each country using aggregated statistics from Eurostat. This allows them to infer the proportion of firms missing from each national sample and to correct for systematic under‑representation of small enterprises.
The second contribution tackles data accuracy. Corporate databases often contain duplicate entries (entity‑resolution errors) and administrative subsidiaries that should not be treated as independent nodes. The authors propose an automated pruning and merging technique that compares node attributes (country, revenue, employee count) and network‑level features (degree, shared‑director counts) to detect spurious nodes and edges. By aligning the observed degree distribution and giant‑component size with their theoretical expectations, the method iteratively removes duplicates, yielding a cleaner topology.
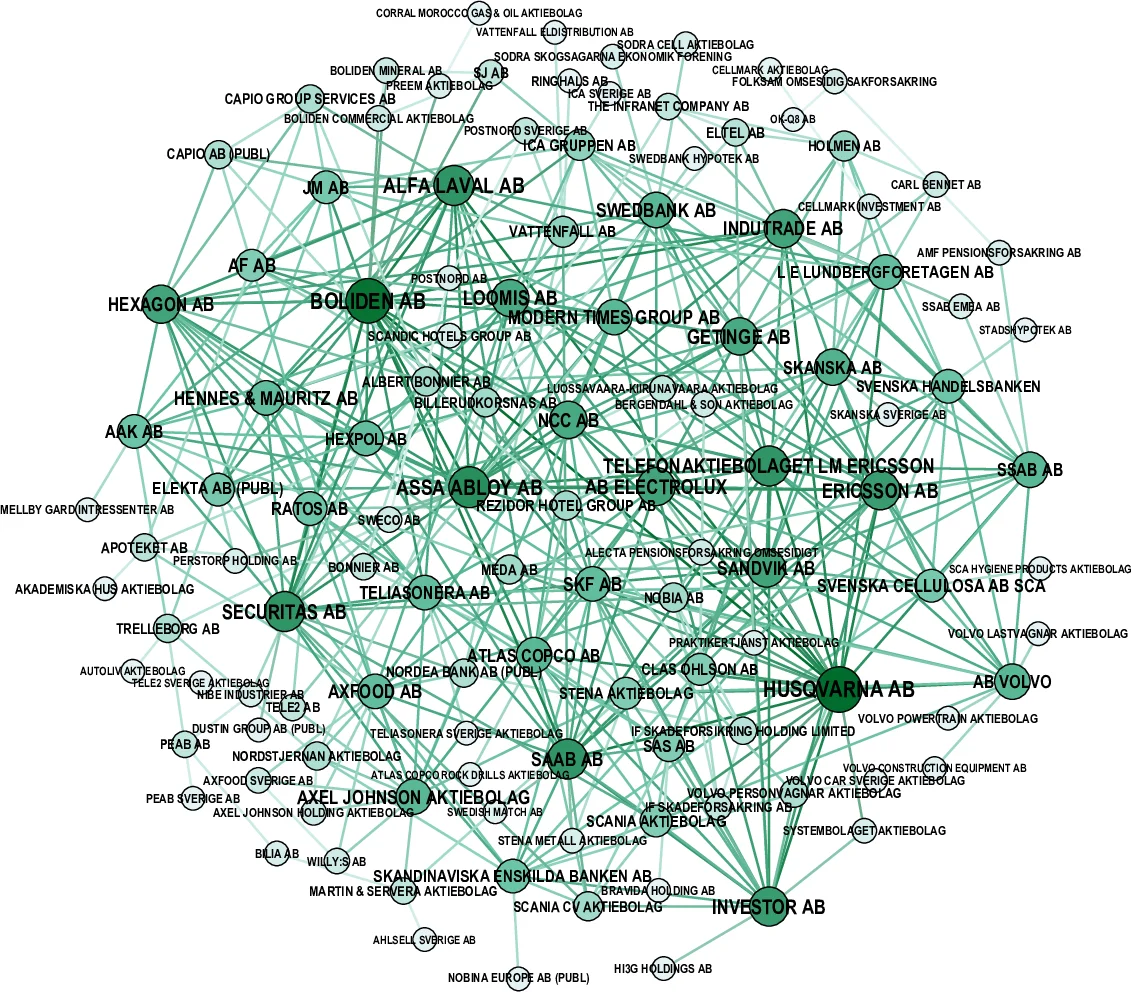
A case study on Sweden’s board‑interlock network (≈94 k nodes, 1.05 M edges in the giant component) illustrates the practical impact. In the raw data, centrality measures (betweenness, closeness) are heavily biased, and a simple SIS diffusion model predicts unrealistically rapid spread of influence. After applying the completeness correction and the duplicate‑pruning algorithm, the degree distribution conforms to the expected power‑law tail, centrality rankings shift to reflect truly influential firms (e.g., Volvo, Ericsson, Atlas Copco), and diffusion simulations produce more plausible influence ranges.
The authors argue that their two‑step quality assessment—statistical completeness estimation followed by topology‑driven accuracy correction—is broadly applicable to other large‑scale social and economic networks where data are automatically harvested. They emphasize that acknowledging MNAR bias and exploiting external aggregate statistics are essential for producing reliable network‑science insights in the era of big data. Future work is suggested on refining duplicate detection, extending the framework to non‑numeric data sources, and integrating the methods into standard network‑analysis pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment