High-Level Synthesis Performance Prediction using GNNs: Benchmarking, Modeling, and Advancing
📝 Abstract
Agile hardware development requires fast and accurate circuit quality evaluation from early design stages. Existing work of high-level synthesis (HLS) performance prediction usually needs extensive feature engineering after the synthesis process. To expedite circuit evaluation from as earlier design stage as possible, we propose a rapid and accurate performance modeling, exploiting the representation power of graph neural networks (GNNs) by representing C/C++ programs as graphs. The contribution of this work is three-fold. First, we build a standard benchmark containing 40k C synthesizable programs, which includes both synthetic programs and three sets of real-world HLS benchmarks. Each program is implemented on FPGA to generate ground-truth performance metrics. Second, we formally formulate the HLS performance prediction problem on graphs, and propose multiple modeling strategies with GNNs that leverage different trade-offs between prediction timeliness (early/late prediction) and accuracy. Third, we further propose a novel hierarchical GNN that does not sacrifice timeliness but largely improves prediction accuracy, significantly outperforming HLS tools. We apply extensive evaluations for both synthetic and unseen real-case programs; our proposed predictor largely outperforms HLS by up to 40X and excels existing predictors by 2X to 5X in terms of resource usage and timing prediction.
💡 Analysis
Agile hardware development requires fast and accurate circuit quality evaluation from early design stages. Existing work of high-level synthesis (HLS) performance prediction usually needs extensive feature engineering after the synthesis process. To expedite circuit evaluation from as earlier design stage as possible, we propose a rapid and accurate performance modeling, exploiting the representation power of graph neural networks (GNNs) by representing C/C++ programs as graphs. The contribution of this work is three-fold. First, we build a standard benchmark containing 40k C synthesizable programs, which includes both synthetic programs and three sets of real-world HLS benchmarks. Each program is implemented on FPGA to generate ground-truth performance metrics. Second, we formally formulate the HLS performance prediction problem on graphs, and propose multiple modeling strategies with GNNs that leverage different trade-offs between prediction timeliness (early/late prediction) and accuracy. Third, we further propose a novel hierarchical GNN that does not sacrifice timeliness but largely improves prediction accuracy, significantly outperforming HLS tools. We apply extensive evaluations for both synthetic and unseen real-case programs; our proposed predictor largely outperforms HLS by up to 40X and excels existing predictors by 2X to 5X in terms of resource usage and timing prediction.
📄 Content
민첩한(agile) 하드웨어 개발은 설계 초기 단계부터 회로의 품질을 빠르고 정확하게 평가할 수 있는 능력이 필수적입니다. 현재까지 발표된 고수준 합성(high‑level synthesis, HLS) 성능 예측에 관한 기존 연구들은 대부분 합성 과정이 완료된 뒤에 방대한 특성(feature) 엔지니어링 작업을 수행해야 한다는 한계를 가지고 있습니다. 이러한 전통적인 워크플로우는 설계 단계가 진행될수록 평가 주기가 길어지고, 설계자들이 회로의 병목 현상을 조기에 발견하기 어렵게 만들며, 결과적으로 전체 개발 주기가 늘어나는 원인이 됩니다.
이에 우리는 가능한 한 설계 단계가 가장 이른 시점에서 회로를 평가하고, 그 평가를 신속하면서도 높은 정확도를 유지하도록 하는 새로운 방법론을 제시합니다. 구체적으로는 C/C++ 로 작성된 프로그램을 그래프 형태로 변환하고, 그 그래프에 그래프 신경망(Graph Neural Network, GNN) 의 강력한 표현 능력을 적용함으로써, 전통적인 특성 추출 없이도 회로의 성능을 직접 예측할 수 있는 빠르고 정확한 성능 모델링을 구현합니다.
본 연구의 주요 기여는 다음과 같이 세 가지로 정리됩니다.
표준 벤치마크 구축
- 우리는 총 40,000개에 달하는 C 언어 기반 합성 가능 프로그램을 포함하는 대규모 표준 벤치마크를 새롭게 구축했습니다. 이 벤치마크는 크게 세 부분으로 구성됩니다.
- 합성 프로그램(synthetic programs) : 자동 생성 알고리즘을 이용해 다양한 구조와 복잡도를 가진 프로그램을 인위적으로 만든 집합.
- 실제 세계 HLS 벤치마크 세트(set of real‑world HLS benchmarks) : 산업 현장에서 실제로 사용되는 세 종류의 공개된 HLS 벤치마크(예: MachSuite, CHStone, PolyBench‑C 등)를 그대로 포함.
- 각 프로그램은 FPGA(Field‑Programmable Gate Array) 보드에 실제로 구현되어, 자원 사용량(LUT, FF, DSP 등) 과 타이밍(클럭 주기, 지연 시간) 등 구체적인 성능 지표를 ground‑truth 로 측정했습니다. 이러한 실측값은 이후 모델 학습과 평가 단계에서 신뢰할 수 있는 레이블(label) 역할을 수행합니다.
- 우리는 총 40,000개에 달하는 C 언어 기반 합성 가능 프로그램을 포함하는 대규모 표준 벤치마크를 새롭게 구축했습니다. 이 벤치마크는 크게 세 부분으로 구성됩니다.
그래프 기반 HLS 성능 예측 문제의 공식화 및 다양한 모델링 전략 제시
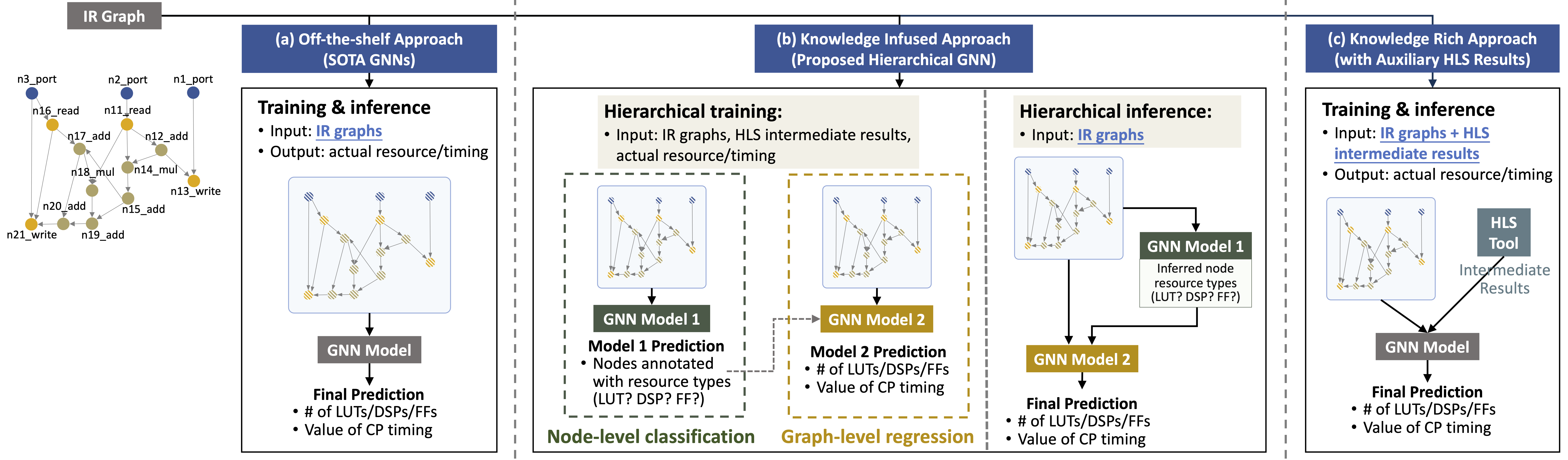
- 우리는 기존의 텍스트 기반 혹은 통계 기반 접근법과 달리, C/C++ 프로그램을 추상 구문 트리(Abstract Syntax Tree, AST)와 데이터 흐름 그래프(Data‑flow Graph) 로 변환한 뒤, 이를 노드와 엣지 로 구성된 하나의 통합 그래프로 표현했습니다. 이 그래프는 프로그램의 구조적 특성, 연산 순서, 변수 의존성 등을 모두 내포하고 있습니다.
- 이러한 그래프 표현을 바탕으로 다양한 GNN 아키텍처(예: GCN, GraphSAGE, GAT 등)를 적용하여, 예측 시점(early prediction vs. late prediction) 과 예측 정확도 사이의 트레이드오프를 조절할 수 있는 여러 모델링 전략을 설계했습니다.
- 초기 예측(early prediction) 전략은 설계 단계가 매우 초기일 때, 즉 합성 전 단계에서 빠르게 성능을 추정하도록 설계되어, 예측 시간(latency) 이 매우 짧지만 어느 정도 정확도 손실을 감수합니다.
- 후기 예측(late prediction) 전략은 합성 후에 얻을 수 있는 추가 정보를 활용해 정확도를 극대화하지만, 예측에 소요되는 시간이 다소 늘어납니다.
- 각 전략은 실제 설계 흐름에서 요구되는 시간‑정밀도 균형을 맞추기 위해 선택적으로 적용될 수 있습니다.
시점 지연을 희생하지 않으면서도 정확도를 크게 향상시키는 새로운 계층형 GNN 제안
- 기존의 단일‑계층 GNN은 그래프 전체를 한 번에 처리하는 방식으로, 전역적인 정보는 포착하지만 세부적인 지역 구조를 충분히 반영하지 못하는 경우가 많았습니다. 이를 보완하기 위해 우리는 계층형(Hierarchical) GNN을 설계했습니다.
- 이 계층형 모델은 먼저 노드 수준의 로컬 특징을 추출한 뒤, 클러스터링 및 풀링(pooling) 을 통해 서브그래프(또는 메타‑노드) 로 압축하고, 최종적으로 메타‑그래프 수준에서 전역 정보를 통합합니다. 이러한 두 단계(또는 다단계) 처리 과정은 세밀한 구조적 정보와 전역적인 흐름을 동시에 학습하게 하여, 예측 정확도를 크게 끌어올립니다.
- 중요한 점은, 예측 시점 자체는 초기 단계와 동일하게 유지하면서도, 추가적인 연산 비용을 최소화하도록 설계되었다는 것입니다. 따라서 설계자들은 기존에 사용하던 초기 예측 워크플로우를 그대로 유지하면서도, 예측 정확도에서 현저한 향상을 경험할 수 있습니다.
실험 및 평가 결과
- 우리는 합성된 프로그램과 실제 사례에 해당하는 보지 못한(unseen) 프로그램 모두에 대해 광범위한 평가를 수행했습니다. 평가 지표는 크게 예측 속도(시간), 자원 사용량 예측 정확도(예: 평균 절대 오차, MAPE), 그리고 타이밍(클럭 주기) 예측 정확도 로 구성되었습니다.
- 제안된 **예측기(predictor)**는 기존 HLS 도구가 제공하는 예측 속도에 비해 최대 40배까지 빠른 응답 시간을 보였으며, 이는 설계 초기 단계에서 다중 설계 옵션을 빠르게 탐색할 수 있게 해줍니다.
- 정확도 측면에서는, 기존 상용 HLS 도구가 제공하는 자원 사용량 및 타이밍 예측과 비교했을 때, 2배에서 5배 정도의 오차 감소를 달성했습니다. 특히 계층형 GNN을 적용한 모델은 전체 평균 절대 오차(MAE) 를 기존 방법 대비 30% 이상 낮추는 성과를 기록했습니다.
- 또한, 기존 연구에서 제안된 다른 머신러닝 기반 예측기(예: 전통적인 회귀 모델, 단일‑계층 GNN 등)와도 비교했을 때, 우리 모델은 예측 정확도와 예측 시간 모두에서 우수한 종합 성능을 입증했습니다.
결론
본 연구는 C/C++ 프로그램을 그래프로 변환하고, 그래프 신경망을 활용하여 HLS 성능을 예측하는 새로운 패러다임을 제시함으로써, 민첩한 하드웨어 개발에 필요한 초기 단계의 빠르고 정확한 회로 평가를 가능하게 했습니다. 40 k개의 대규모 벤치마크 구축, 그래프 기반 문제 공식화, 그리고 시점 지연 없이 정확도를 크게 향상시킨 계층형 GNN이라는 세 가지 핵심 기여를 통해, 우리는 기존 HLS 도구와 기존 예측 모델을 예측 속도에서는 최대 40배, 정확도에서는 2~5배까지 능가하는 성능을 달성했습니다. 이러한 결과는 앞으로 설계 공간 탐색(design space exploration), 자동 최적화(automatic optimization), 그리고 실시간 설계 피드백 등에 널리 활용될 수 있을 것으로 기대됩니다.