Distributed Adaptive Newton Methods with Global Superlinear Convergence
This paper considers the distributed optimization problem where each node of a peer-to-peer network minimizes a finite sum of objective functions by communicating with its neighboring nodes. In sharp contrast to the existing literature where the fastest distributed algorithms converge either with a global linear or a local superlinear rate, we propose a distributed adaptive Newton (DAN) algorithm with a global quadratic convergence rate. Our key idea lies in the design of a finite-time set-consensus method with Polyak’s adaptive stepsize. Moreover, we introduce a low-rank matrix approximation (LA) technique to compress the innovation of Hessian matrix so that each node only needs to transmit message of dimension $\mathcal{O}(p)$ (where $p$ is the dimension of decision vectors) per iteration, which is essentially the same as that of first-order methods. Nevertheless, the resulting DAN-LA converges to an optimal solution with a global superlinear rate. Numerical experiments on logistic regression problems are conducted to validate their advantages over existing methods.
💡 Research Summary
The paper addresses the distributed optimization problem in a peer‑to‑peer network where each node i holds a local smooth convex function f_i(x) and the goal is to minimize the global sum f(x)=∑_{i=1}^n f_i(x). While first‑order distributed methods achieve only global linear convergence and existing second‑order methods are either locally superlinear or globally linear, the authors propose a novel Distributed Adaptive Newton (DAN) algorithm that attains global quadratic convergence, and a low‑rank variant (DAN‑LA) that retains global superlinear convergence with communication cost comparable to first‑order methods.
The key technical contributions are threefold. First, the authors design a finite‑time set‑consensus protocol called Distributed Selective Flooding (DSF). Unlike traditional average‑consensus which converges asymptotically, DSF guarantees that after at most n‑1 communication rounds on a tree (or n+d_G‑1 rounds on a strongly connected graph) every node possesses the complete set of messages from all nodes. The protocol avoids duplicate transmissions by using unique node identifiers, thereby halving the communication overhead relative to the classic Distributed Flooding (DF) method.
Second, the paper integrates Polyak’s adaptive stepsize into a distributed Newton framework. After each DSF round, every node computes its local gradient and Hessian, shares them, and forms the exact Newton direction d_k = –H_k^{-1}∇f(x_k). The adaptive stepsize α_k = (‖∇f(x_k)‖²)/(‖∇f(x_k)‖²+‖H_k d_k‖²) is computed locally without any line‑search. This stepsize is provably sufficient to guarantee a global Q‑quadratic convergence rate from any starting point, overcoming the usual requirement of a unit stepsize that may cause divergence far from the optimum.
Third, to keep the per‑iteration communication at O(p) (the dimension of the decision variable) the authors introduce a Low‑rank Approximation (LA) technique for the Hessian “innovation” ΔH_k = H_k – Ĥ_k. By approximating ΔH_k with a rank‑1 matrix s·w wᵀ (s∈{−1,1}, w∈ℝ^p) that minimizes the spectral norm error, each node only needs to transmit the vector w and a scalar sign. The approximation error is explicitly bounded and incorporated into the adaptive stepsize design, ensuring that the compressed Newton updates still achieve global Q‑superlinear convergence. This approach differs from quasi‑Newton schemes because the approximation error is controlled rather than being an uncontrolled by‑product.
Theoretical analysis rests on standard assumptions: each f_i is twice continuously differentiable, μ‑strongly convex, and has an L‑Lipschitz Hessian; the communication graph is strongly connected. Under these conditions, the authors prove (i) DSF yields exact set‑consensus in finite time, (ii) DAN converges globally quadratically, and (iii) DAN‑LA converges globally superlinearly despite the low‑rank compression. The proofs combine consensus dynamics, properties of Polyak’s stepsize, and perturbation analysis of the Hessian approximation.
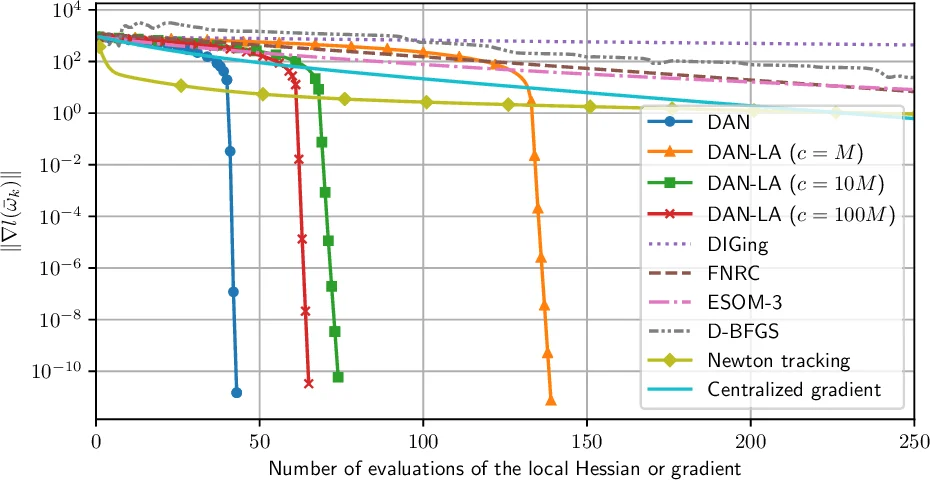
Empirical validation is performed on a logistic regression task using the Covtype dataset. The experiments compare DAN, DAN‑LA, several first‑order distributed algorithms (e.g., Nedic, Shi, Scaman), and existing second‑order distributed methods (e.g., Mokhtari, Qu). Results show that DAN reaches the optimal solution in dramatically fewer iterations than first‑order methods, while DAN‑LA achieves comparable accuracy with only O(p) communication per iteration. Moreover, both algorithms converge from random initializations, confirming the global nature of the theoretical guarantees, whereas the locally superlinear methods require initialization near the optimum.
In summary, the paper makes a significant advance in distributed optimization by delivering a Newton‑type method that is both communication‑efficient and globally superlinear (or quadratic) convergent. The combination of finite‑time set‑consensus, adaptive stepsize, and controlled low‑rank Hessian compression is novel and well‑justified both theoretically and experimentally. Future work suggested includes extensions to time‑varying or directed graphs, non‑convex objectives, and asynchronous implementations.
Comments & Academic Discussion
Loading comments...
Leave a Comment