Combining No-regret and Q-learning
Counterfactual Regret Minimization (CFR) has found success in settings like poker which have both terminal states and perfect recall. We seek to understand how to relax these requirements. As a first step, we introduce a simple algorithm, local no-regret learning (LONR), which uses a Q-learning-like update rule to allow learning without terminal states or perfect recall. We prove its convergence for the basic case of MDPs (and limited extensions of them) and present empirical results showing that it achieves last iterate convergence in a number of settings, most notably NoSDE games, a class of Markov games specifically designed to be challenging to learn where no prior algorithm is known to achieve convergence to a stationary equilibrium even on average.
💡 Research Summary
The paper addresses two restrictive assumptions of Counterfactual Regret Minimization (CFR)—perfect recall and the existence of terminal states—that limit its applicability beyond games like poker. To relax these constraints, the authors introduce Local No‑Regret learning (LONR), an algorithm that places a copy of a no‑regret learner at every state of a Markov Decision Process (MDP) and updates the associated Q‑values in a fashion reminiscent of Q‑learning. Unlike CFR, LONR does not require a full history of visited states (perfect recall) nor does it wait for an episode to terminate before performing updates; instead, it uses immediate “counterfactual” rewards for all actions, akin to a planning setting.
A central technical contribution is the definition of a “no‑absolute‑regret” property, a stronger version of standard no‑regret. An algorithm satisfying this property guarantees that the absolute regret at round k is bounded by a sequence ρₖ that vanishes as k→∞. By feeding the current Q‑values as the loss vectors to the no‑absolute‑regret learners, the authors derive a series of lemmas that bound the deviation of the empirical average Qₖ from the Bellman operator T. Lemma 4.1 shows that −γρₖ₋₁ + TQₖ ≤ Qₖ ≤ γρₖ₋₁ + TQₖ, linking the learning dynamics directly to the contraction property of T. Lemma 4.2 bounds the range of Qₖ, while Lemma 4.3 proves that the distance ‖Qₖ − TQₖ‖∞ shrinks at a rate O(1/k) + γρₖ₋₁. Lemma 4.4, a standard fixed‑point argument, then guarantees that any sequence of approximate fixed points converges to the unique fixed point Q* of T. Theorem 4.5 combines these results to establish that the average Q‑values generated by LONR converge to Q* for any discounted‑reward MDP.
Although the core convergence proof is limited to standard MDPs, the authors extend the analysis in two directions. First, they show that the same reasoning applies to “online MDPs” where transition dynamics are stationary but rewards may change over time, and to normal‑form games (a single‑state MDP). Second, they propose two practical extensions: (1) asynchronous updates, where at each iteration a single state is chosen uniformly at random for update, and (2) bandit feedback, where only the reward of the action actually taken is observed. Under the simplifying assumption of uniform random state selection, they prove that convergence still holds, providing intuition for more realistic sampling schemes.
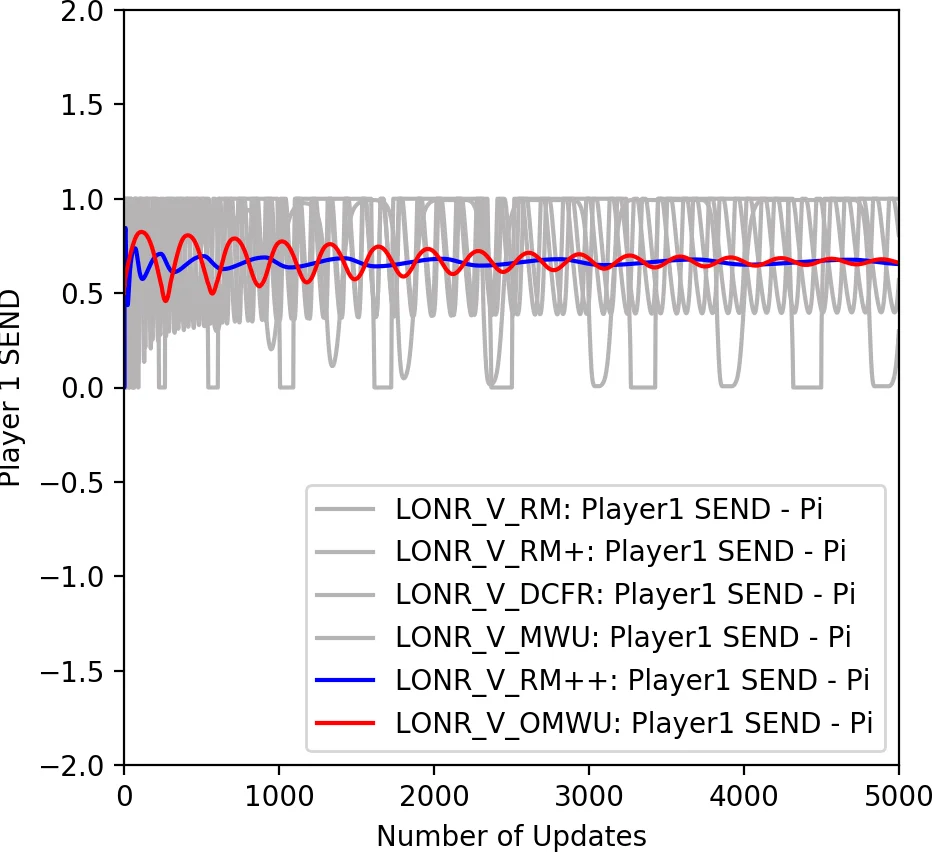
The experimental section focuses on NoSDE Markov games, a class of two‑player, finite‑state games deliberately constructed to be hard for conventional Q‑learning: all stationary equilibria are mixed, and Q‑values alone cannot reveal the correct randomization. Prior work could only guarantee convergence to a non‑stationary equilibrium or average‑policy convergence. Using LONR with a novel variant of regret‑matching (which, while not strictly no‑regret, empirically exhibits last‑iterate convergence), the authors demonstrate that both the average policy and the current (last‑iterate) policy converge to the stationary mixed equilibrium. This is notable because most no‑regret algorithms, including standard regret‑matching, only guarantee average‑policy convergence and often exhibit cyclic behavior in the last iterate. The results thus provide a concrete example of last‑iterate convergence in a non‑trivial multi‑agent setting, bridging a gap between game‑theoretic learning and reinforcement learning.
In summary, the paper makes three key contributions: (1) a simple algorithm, LONR, that merges the local policy selection of CFR with the value‑iteration style updates of Q‑learning, thereby removing the need for perfect recall and terminal states; (2) a rigorous convergence proof for discounted MDPs and extensions to online MDPs and normal‑form games; (3) empirical evidence that LONR can achieve stable last‑iterate convergence in challenging multi‑agent Markov games where traditional RL methods fail. The work opens a promising direction for integrating no‑regret learning into broader reinforcement‑learning frameworks, especially in settings where function approximation and multi‑agent interactions make traditional Q‑learning unstable.
Comments & Academic Discussion
Loading comments...
Leave a Comment