rVAD: An Unsupervised Segment-Based Robust Voice Activity Detection Method
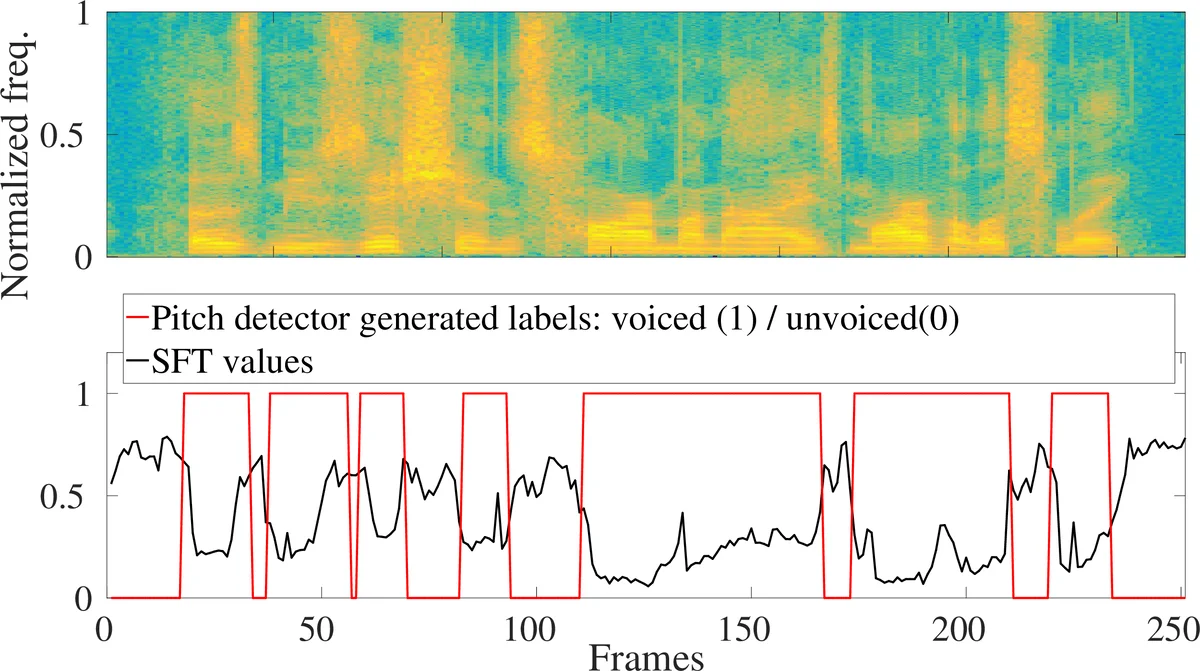
This paper presents an unsupervised segment-based method for robust voice activity detection (rVAD). The method consists of two passes of denoising followed by a voice activity detection (VAD) stage. In the first pass, high-energy segments in a speech signal are detected by using a posteriori signal-to-noise ratio (SNR) weighted energy difference and if no pitch is detected within a segment, the segment is considered as a high-energy noise segment and set to zero. In the second pass, the speech signal is denoised by a speech enhancement method, for which several methods are explored. Next, neighbouring frames with pitch are grouped together to form pitch segments, and based on speech statistics, the pitch segments are further extended from both ends in order to include both voiced and unvoiced sounds and likely non-speech parts as well. In the end, a posteriori SNR weighted energy difference is applied to the extended pitch segments of the denoised speech signal for detecting voice activity. We evaluate the VAD performance of the proposed method using two databases, RATS and Aurora-2, which contain a large variety of noise conditions. The rVAD method is further evaluated, in terms of speaker verification performance, on the RedDots 2016 challenge database and its noise-corrupted versions. Experiment results show that rVAD is compared favourably with a number of existing methods. In addition, we present a modified version of rVAD where computationally intensive pitch extraction is replaced by computationally efficient spectral flatness calculation. The modified version significantly reduces the computational complexity at the cost of moderately inferior VAD performance, which is an advantage when processing a large amount of data and running on low resource devices. The source code of rVAD is made publicly available.
💡 Research Summary
The paper introduces rVAD, an unsupervised, segment‑based voice activity detection (VAD) framework that achieves high robustness to both stationary and burst‑type noises while maintaining low computational cost. The method consists of two denoising passes followed by a VAD stage that relies on posterior SNR‑weighted energy differences and pitch (or spectral flatness) information.
In the first pass, high‑energy segments are identified using a posteriori SNR‑weighted energy difference d(m)=q·|e(m)−e(m−1)|·max(SNR_post(m),0). If a high‑energy segment contains no detectable pitch, it is classified as a high‑energy noise segment and its samples are zero‑ed out. This step removes the most disruptive burst‑like noises that traditional spectral subtraction cannot suppress.
The second pass applies a conventional speech enhancement technique (e.g., minimum‑statistics noise estimation, MMSE, or MCRA) together with spectral subtraction to further attenuate the remaining, more stationary noise components.
After denoising, frames with detected pitch are grouped into “pitch segments”. These segments are then extended on both ends based on simple speech statistics (average energy, SNR, etc.) so that they encompass voiced, unvoiced, and transitional non‑speech portions that are likely to belong to the same utterance. The extended pitch segments serve as anchors that guarantee the presence of speech within each segment, thereby simplifying threshold selection for VAD.
Within each extended segment, the same posterior SNR‑weighted energy difference is recomputed and compared against a pre‑learned threshold; frames exceeding the threshold are labeled as speech. Because the decision is made at the segment level, the method avoids the cumbersome frame‑selection procedures used in earlier work and provides a more stable decision boundary.
A lightweight variant, rVAD‑fast, replaces the computationally intensive pitch detector with a spectral flatness (SFT) measure. SFT is computed directly from the FFT magnitude spectrum and serves as a proxy for pitch presence. Experiments show that rVAD‑fast runs roughly ten times faster than the original rVAD while incurring only a modest 2–3 % drop in VAD accuracy, making it suitable for real‑time or embedded applications.
The authors evaluate rVAD on three public corpora: RATS (telephone channel noise), Aurora‑2 (various additive noises and SNRs from –5 dB to 20 dB), and RedDots 2016 (speaker verification). Performance metrics include Detection Cost Function (DCF), Equal Error Rate (EER), and DET curves. Compared with a range of baselines—ETSI AFE VAD, MFB‑VAD, LTSV‑VAD, NLSM‑GMM, and recent deep‑learning based VADs—rVAD consistently yields lower DCF and EER, especially in low‑SNR and burst‑noise conditions. In speaker verification experiments, applying rVAD as a front‑end preprocessing step reduces the verification EER by about 1.2 % absolute relative to using no VAD or conventional VADs.
Key contributions of the paper are:
- A two‑stage denoising strategy that first eliminates high‑energy, non‑speech bursts and then suppresses stationary noise.
- The use of pitch (or spectral flatness) as an anchor to guarantee speech presence, removing the need for the “speech‑always‑present” assumption common in many unsupervised VADs.
- A segment‑based VAD decision that simplifies threshold selection and improves robustness across diverse noise environments.
- An open‑source implementation in both MATLAB and Python, together with a fast variant for low‑resource platforms.
Overall, rVAD offers a practical, reproducible solution for robust voice activity detection in real‑world scenarios, balancing detection accuracy with computational efficiency, and its publicly released code facilitates further research and deployment in speech‑processing systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment