Linear classifier, least-squares cost function, and outliers
A set of introductory notes on the subject of data classification using a linear classifier and least-squares cost function, and the negative effect of the presence of outliers on the decision boundary of the linear discriminant. We also show how a simple scaling could make the outlier less significant, thereby obtaining a much better decision boundary. We present some numerical results.
💡 Research Summary
The paper investigates the well‑known vulnerability of linear classifiers trained with a least‑squares (LS) error function to outliers. Starting from the standard binary linear discriminant y(x)=wᵀx+w₀ and the LS cost C(w)=½N∑ₙ(y(xₙ)−tₙ)², the authors derive the closed‑form solution w = (XᵀX)⁻¹Xᵀt, where X contains the augmented input vectors. They then construct a synthetic two‑dimensional scenario consisting of two large Gaussian‑like clouds (normal data) and small peripheral clouds (potential outliers). By decomposing the data into class‑wise means ( \bar{x}^{(k)} for normal points and \bar{x}^{(k+)} for outliers) and densities ρ(k), they analytically show how the presence of even a few outliers can dominate the matrix (XᵀX)⁻¹ and pull the decision boundary toward the outlier region. The effect is quantified in terms of the outlier proportion γ and the distance of the outlier mean from the normal cluster.
To mitigate this problem, the authors propose a very simple preprocessing step: scale each augmented input vector by its Euclidean norm, i.e., replace x′ with x̃ = x′/‖x′‖. Because the LS formulation is homogeneous, the same cost function and closed‑form solution apply to the scaled data. The scaling effectively re‑weights each sample by 1/‖x′‖, which reduces the influence of points with large norms (the outliers) while amplifying the contribution of typical points whose norms are smaller. The paper re‑derives the expressions for S = Xᵀt and I = (XᵀX)⁻¹ under scaling and demonstrates that the terms involving the outlier mean are divided by its large norm, thereby diminishing its pull on the weight vector.
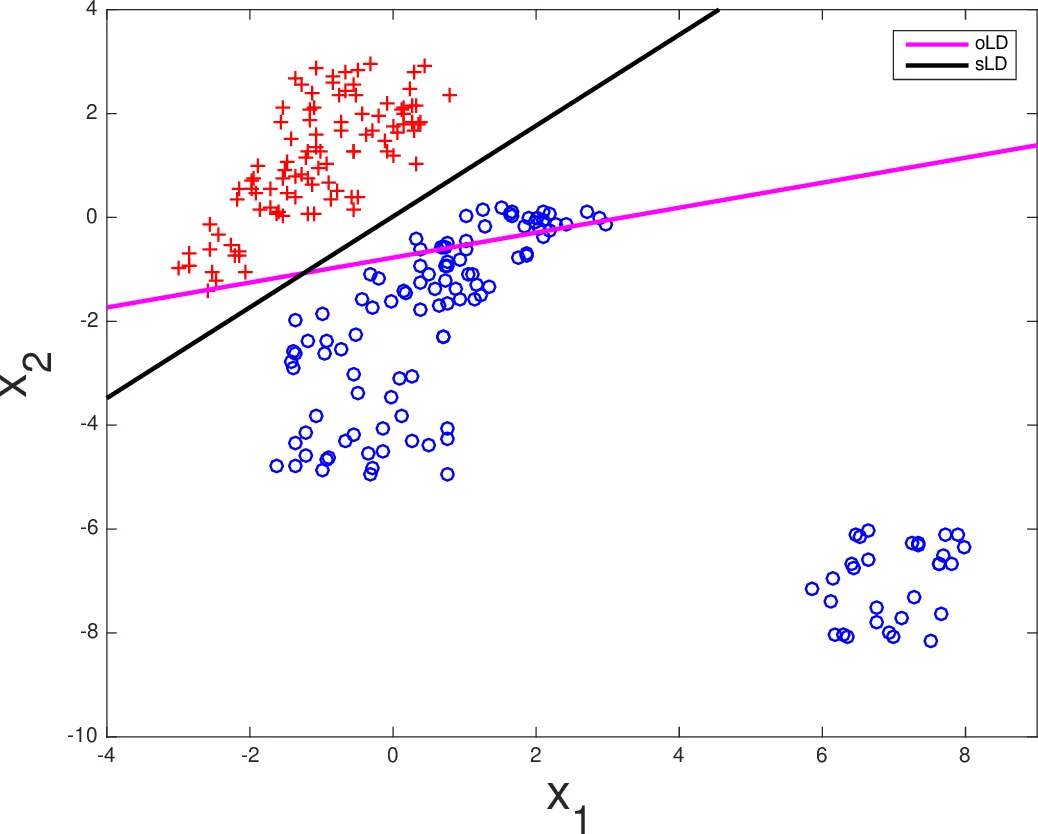
Experimental validation is provided in two parts. First, a 2‑D synthetic dataset illustrates the geometric effect: without scaling the LS classifier’s boundary is severely skewed toward the outlier cloud; with scaling the boundary re‑centers between the two normal clouds. Second, the authors apply the method to the MNIST handwritten digit dataset using a multi‑class LS classifier (one‑vs‑all). After scaling the input vectors, overall classification accuracy improves by about 1–2 % and the error rate on noisy test samples drops noticeably, confirming that the technique works in high‑dimensional settings.
The discussion acknowledges limitations: scaling does not replace robust regression techniques, it may be sensitive to the distribution of norms in very high dimensions, and it assumes that outliers have larger norms than typical points. Nevertheless, the authors argue that the approach offers a low‑cost, easy‑to‑implement alternative to more complex outlier‑robust methods. They suggest future work on combining norm‑scaling with regularization, extending the idea to kernelized classifiers, and exploring adaptive scaling factors based on local data density.
Comments & Academic Discussion
Loading comments...
Leave a Comment