BERTphone: Phonetically-Aware Encoder Representations for Utterance-Level Speaker and Language Recognition
We introduce BERTphone, a Transformer encoder trained on large speech corpora that outputs phonetically-aware contextual representation vectors that can be used for both speaker and language recognition. This is accomplished by training on two objectives: the first, inspired by adapting BERT to the continuous domain, involves masking spans of input frames and reconstructing the whole sequence for acoustic representation learning; the second, inspired by the success of bottleneck features from ASR, is a sequence-level CTC loss applied to phoneme labels for phonetic representation learning. We pretrain two BERTphone models (one on Fisher and one on TED-LIUM) and use them as feature extractors into x-vector-style DNNs for both tasks. We attain a state-of-the-art $C_{\text{avg}}$ of 6.16 on the challenging LRE07 3sec closed-set language recognition task. On Fisher and VoxCeleb speaker recognition tasks, we see an 18% relative reduction in speaker EER when training on BERTphone vectors instead of MFCCs. In general, BERTphone outperforms previous phonetic pretraining approaches on the same data. We release our code and models at https://github.com/awslabs/speech-representations.
💡 Research Summary
The paper introduces BERTphone, a Transformer‑based encoder that is pretrained on large speech corpora with two complementary objectives and then used as a frozen feature extractor for both speaker recognition (SR) and language recognition (LR). The first objective adapts the masked language modeling paradigm to continuous speech: 5 % of the time steps are selected, each covering a span of three stacked frames (≈100 ms). These spans are replaced with zero vectors, and the model is trained to reconstruct the entire sequence using an L1 loss. This span‑masking strategy, inspired by SpanBERT and SpecAugment, forces the encoder to learn higher‑level acoustic patterns rather than simply copying locally correlated frames.
The second objective is a sequence‑level connectionist temporal classification (CTC) loss applied to context‑independent phoneme labels derived from the CMUdict lexicon (39 non‑silence symbols). By using CTC, the model learns to align phonetic information to each frame without requiring forced alignments, thereby embedding phonetic knowledge directly into the encoder’s representations. The total loss is a weighted sum L = λ·√T·L_recons + (1 − λ)·L_CTC, where √T rescales the frame‑wise reconstruction loss to be comparable with the sequence‑level CTC loss.
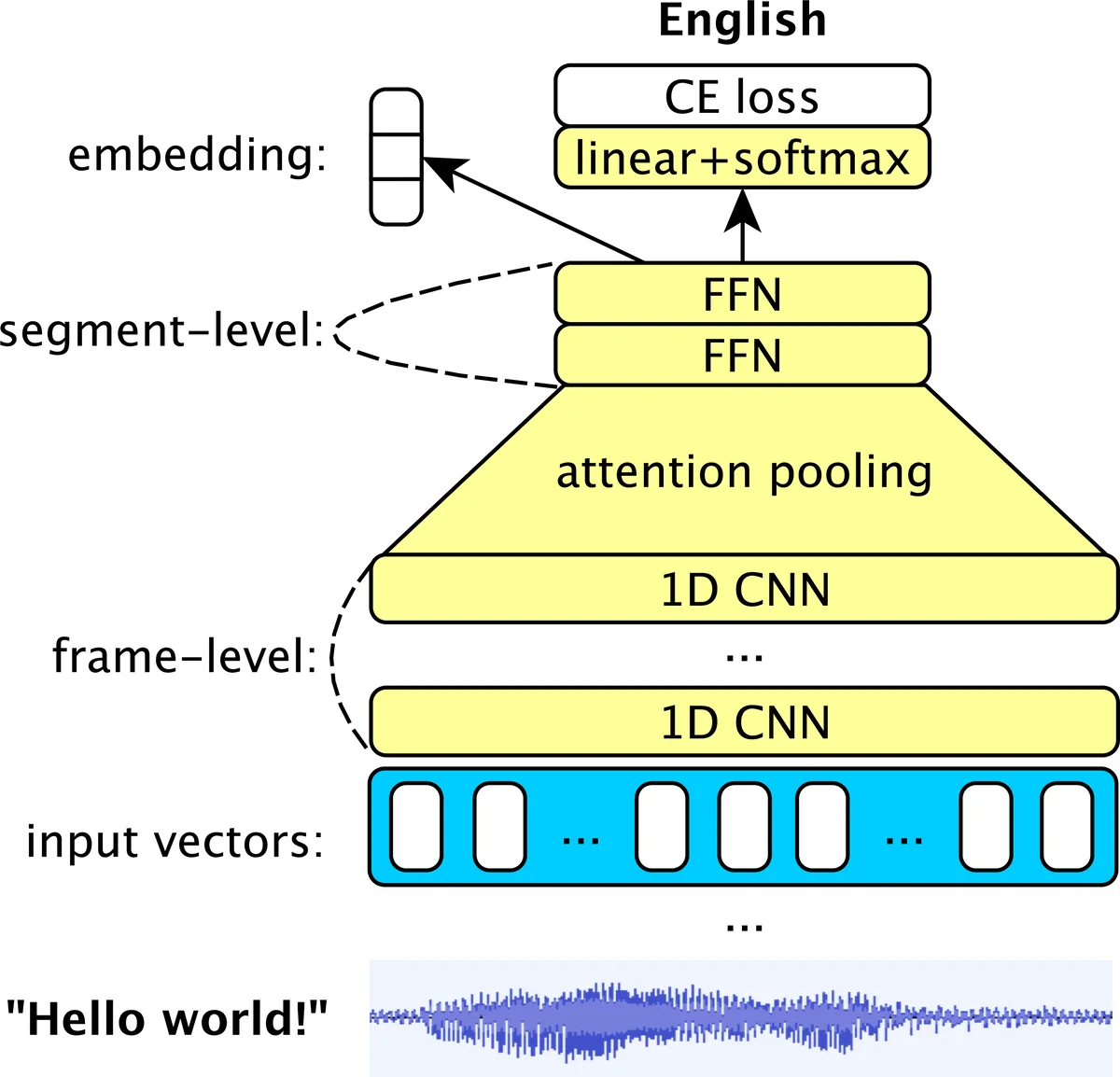
Architecturally, BERTphone mirrors BERT‑base: 12 self‑attention layers, hidden size 768, feed‑forward dimension 3072, and 12 attention heads. Input features are 40‑dim MFCCs (25 ms window, 10 ms hop) mean‑normalized and stacked every three frames, yielding a 120‑dim vector per time step. Positional embeddings are added before the Transformer stack. Two separate models are pretrained: one on the 8 kHz Fisher telephone conversation corpus and another on the 16 kHz TED‑LIUM lecture corpus, each using the appropriate sampling rate to preserve acoustic fidelity.
After pretraining, only the final layer of the encoder is retained as a fixed feature extractor. These “BERTphone vectors” are fed into an x‑vector‑style downstream network that replaces the original time‑delay neural network (TDNN) layers with five 1‑D convolutional layers (kernel sizes 2, 2, 3, 1, 1) and substitutes the conventional statistics pooling with multi‑head self‑attention pooling (SAP). SAP assigns learned importance weights to each frame, improving robustness to variable utterance lengths. For SR, the resulting utterance‑level embeddings are compared using probabilistic linear discriminant analysis (PLDA); for LR, a softmax classifier directly predicts language categories.
Experimental evaluation covers three tasks. In closed‑set speaker verification on the Fisher dataset, BERTphone‑based embeddings achieve an equal error rate (EER) of 1.23 % versus 1.39 % for a prior multitask phonetic‑x‑vector system, and outperform i‑vector and vanilla x‑vector baselines. On the large‑scale VoxCeleb corpus (over 7 k speakers, 2 M utterances), training on TED‑LIUM BERTphone vectors yields an 18 % relative reduction in EER compared with training directly on MFCCs. For language recognition, the model is evaluated on the NIST LRE07 3‑second closed‑set task (14 languages). BERTphone‑based features achieve a C_avg of 6.16, surpassing previous state‑of‑the‑art systems that use CNN‑BLSTM or LDE pooling.
Ablation studies examine the impact of the loss weighting λ, fine‑tuning deeper encoder layers, and replacing phoneme CTC targets with grapheme targets. Results indicate that λ≈0.5 provides the best trade‑off between acoustic reconstruction and phonetic supervision, and that using phoneme labels yields superior downstream performance compared with graphemes. Fine‑tuning beyond the final layer offers marginal gains but increases computational cost.
In summary, BERTphone demonstrates that a jointly trained acoustic‑reconstruction and phoneme‑CTC objective can produce versatile, high‑level speech representations that transfer effectively to both speaker and language recognition without task‑specific fine‑tuning. The approach outperforms traditional bottleneck or tandem features, offers competitive phoneme error rates, and opens avenues for applying the same pretrained encoder to other speech tasks such as automatic speech recognition, emotion detection, or spoken language understanding.
Comments & Academic Discussion
Loading comments...
Leave a Comment