Optimizing Data Intensive Flows for Networks on Chips
Data flow analysis and optimization is considered for homogeneous rectangular mesh networks. We propose a flow matrix equation which allows a closed-form characterization of the nature of the minimal time solution, speedup and a simple method to determine when and how much load to distribute to processors. We also propose a rigorous mathematical proof about the flow matrix optimal solution existence and that the solution is unique. The methodology introduced here is applicable to many interconnection networks and switching protocols (as an example we examine toroidal networks and hypercube networks in this paper). An important application is improving chip area and chip scalability for networks on chips processing divisible style loads.
💡 Research Summary
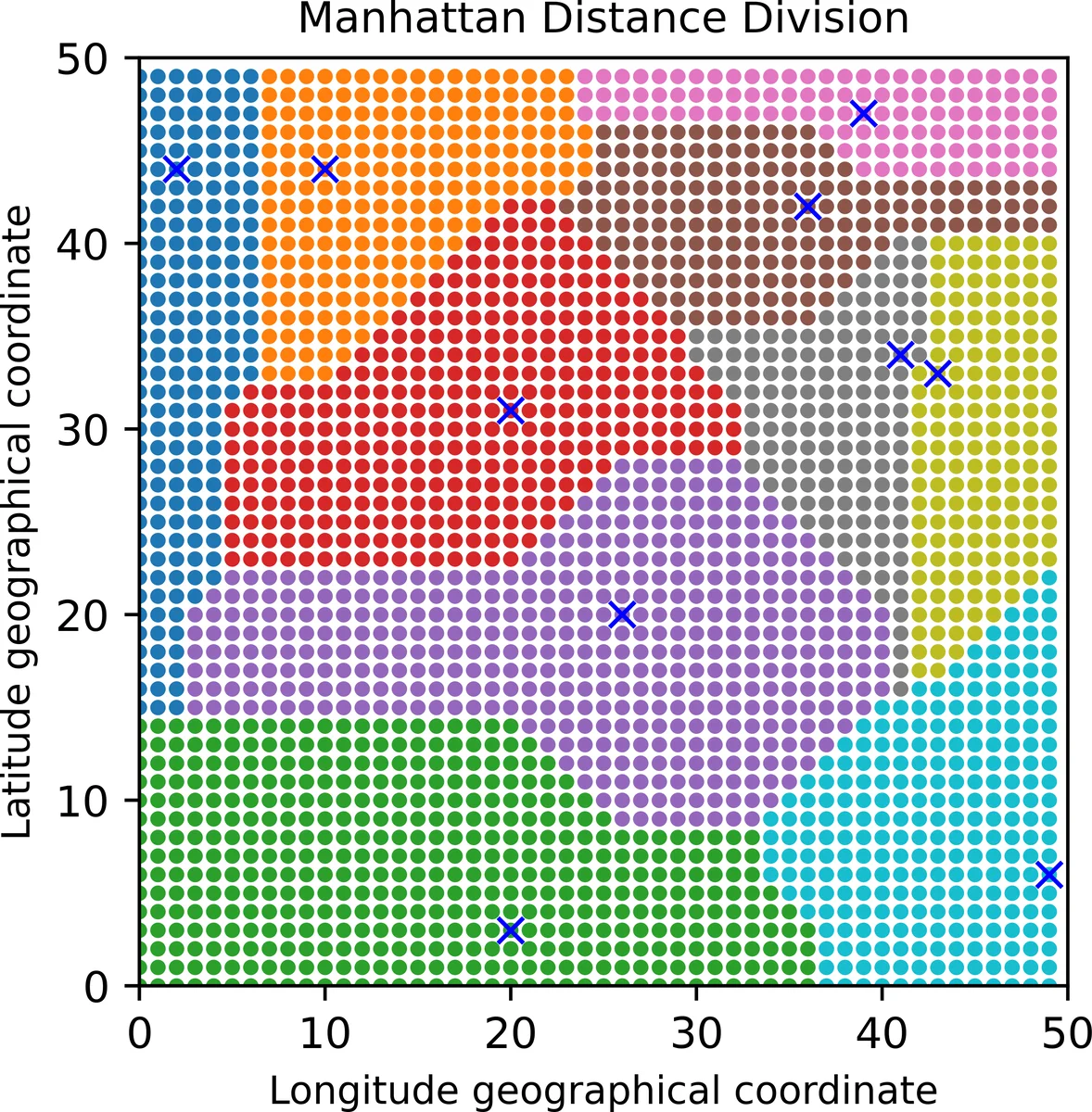
The paper addresses the problem of efficiently distributing data‑intensive workloads across a Network‑on‑Chip (NoC) when multiple data injection points are present. Building on divisible load theory, the authors introduce two complementary techniques: (1) a Voronoi‑diagram based clustering that partitions the homogeneous mesh into geographic cells, each centered on the nearest injection point, and (2) a novel mathematical construct called the “flow matrix” that captures the linear relationships among computation time, communication time, and the overall makespan for each processor.
In a homogeneous rectangular mesh, the distance from any processor to its nearest source is measured by Manhattan hops. For each hop distance D, the number of processors at that distance is counted; these counts form the first row of the flow matrix. Subsequent rows encode the communication‑to‑computation speed ratio σ = (z·T_cm)/(ω·T_cp) using a pattern of –σ and 1 entries. The resulting linear system A·α = b, where α is the vector of load fractions and b is a unit vector, can be solved analytically or with standard Gaussian elimination. The determinant of A directly yields the speedup (|det A| = 1/α₀) and the optimal load fractions for all processors.
The authors first illustrate the method on a 2 × 2 mesh, deriving closed‑form expressions for α₀, α₁, and α₃ as functions of σ. They then generalize to arbitrary m × n meshes, showing that the matrix rank r is at most the maximum hop distance plus one, so solving costs O(r³) time while constructing A costs O(m·n).
To handle multiple sources, three topological models are considered: (I) sources forming a connected induced subgraph, (II) sources that are mutually disconnected, and (III) a mixture of both. For each case the “Equivalence Processor Scheduling Algorithm (EPSA)” is proposed. EPSA collapses all source nodes into a single equivalent processor with speed ω_eq, computes the hop distances D_i for every processor relative to this virtual source, builds the corresponding flow matrix, and solves for the load fractions α_i. The algorithm’s complexity remains dominated by the O(r³) determinant calculation.
Extensive simulations on a 50 × 50 mesh (2 500 cores) explore a range of σ values. When σ ≤ 0.05 (communication much faster than computation), the entire network can be engaged, achieving speedups close to the number of active cores (e.g., ~36× for a 6 × 6 region). When σ ≈ 1 (communication and computation equally costly), only the processors within the first two hop layers (12 cores) are effectively used, yielding a ~12× speedup. Importantly, after solving the flow matrix each cluster’s load distribution is re‑balanced across clusters, reducing the total number of cores actually powered on by about 30 % while preserving the makespan.
The paper highlights several strengths: the flow‑matrix formulation is topology‑agnostic and can be applied to toroidal, hyper‑cube, or arbitrary NoC graphs; the determinant provides an immediate estimate of achievable speedup; and Voronoi clustering naturally minimizes intra‑cluster communication. Limitations include the assumption of homogeneous processors and links, neglect of return traffic, and perfect divisibility of the workload. The authors acknowledge that real‑world NoCs exhibit heterogeneity, dynamic load variations, and thermal/power constraints, suggesting future work to extend the model to non‑ideal conditions and to refine boundary‑cell load balancing.
In summary, the study delivers a mathematically rigorous yet computationally lightweight framework for multi‑source divisible‑load scheduling on NoCs. By combining Voronoi‑based clustering with the flow‑matrix linear system, it achieves both reduced chip area (fewer active cores) and substantial speedup, offering a valuable tool for designers of high‑performance, low‑power many‑core chips.
Comments & Academic Discussion
Loading comments...
Leave a Comment