Optimizing thermodynamic trajectories using evolutionary and gradient-based reinforcement learning
Using a model heat engine, we show that neural network-based reinforcement learning can identify thermodynamic trajectories of maximal efficiency. We consider both gradient and gradient-free reinforcement learning. We use an evolutionary learning algorithm to evolve a population of neural networks, subject to a directive to maximize the efficiency of a trajectory composed of a set of elementary thermodynamic processes; the resulting networks learn to carry out the maximally-efficient Carnot, Stirling, or Otto cycles. When given an additional irreversible process, this evolutionary scheme learns a previously unknown thermodynamic cycle. Gradient-based reinforcement learning is able to learn the Stirling cycle, whereas an evolutionary approach achieves the optimal Carnot cycle. Our results show how the reinforcement learning strategies developed for game playing can be applied to solve physical problems conditioned upon path-extensive order parameters.
💡 Research Summary
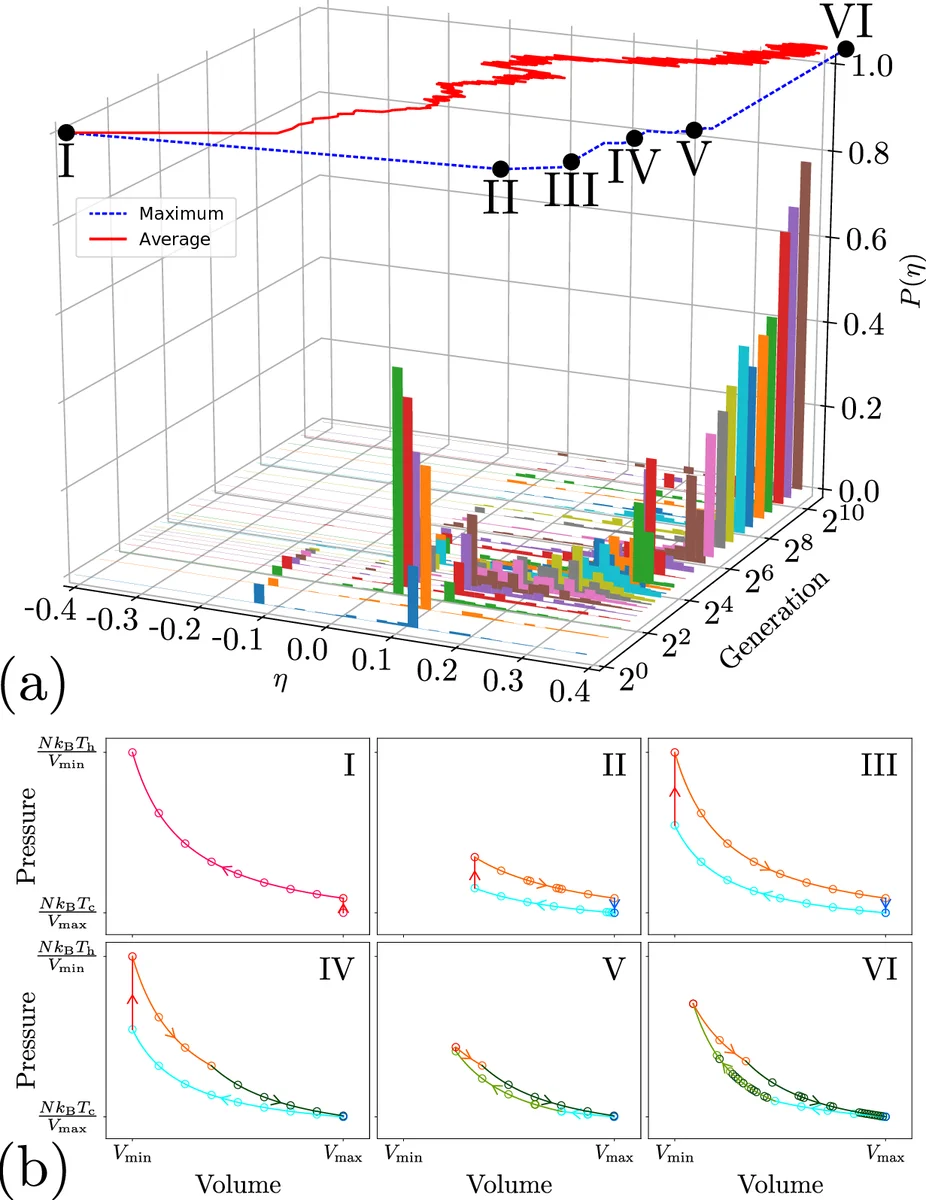
This paper demonstrates how reinforcement learning (RL), both gradient‑free (evolutionary) and gradient‑based (policy‑gradient), can be used to discover thermodynamically optimal cycles for a simple model heat engine. The engine consists of a monatomic ideal gas confined in a frictionless piston whose volume V and temperature T define the system state. The gas can exchange heat with a hot reservoir at 500 K and a cold reservoir at 300 K, and a set of elementary thermodynamic actions—adiabatic/compressive, isothermal, and iso‑choric heating/cooling—are available. Each action changes the state, producing a work increment ΔW and a heat increment ΔQ; the total efficiency of a trajectory of K = 200 steps is defined as η = ΣΔW / ΣΔQ_in, a path‑extensive quantity that serves as the learning objective.
A neural network policy maps the normalized state (T‑scaled, V‑scaled) to a probability distribution over the M ≤ 8 possible actions. The network has two input neurons, one hidden layer of 1024 tanh‑activated units, and M output neurons; the action with the highest output is selected deterministically. The network parameters θ (weights and biases) are initialized from a zero‑mean unit‑variance Gaussian.
Evolutionary (gradient‑free) learning proceeds by maintaining a population of 100 networks. After each generation, the top 25 % (by η) are retained, and 75 offspring are created by adding Gaussian noise (σ = 0.05) to all parameters of randomly chosen parents. Repeating this process for ~100 generations drives the efficiency distribution P(η) toward the Carnot limit η_max = 1 − T_c/T_h ≈ 0.4. The resulting trajectories form closed P‑V cycles that are visually indistinguishable from the textbook Carnot cycle (alternating isothermal and adiabatic branches). When the action set is restricted (e.g., removing adiabats), the algorithm discovers the Stirling or Otto cycles, which are the theoretical optima under those constraints. Adding a non‑reversible action leads to a previously unknown cycle, illustrating the method’s capacity to explore novel thermodynamic protocols.
Policy‑gradient (gradient‑based) learning uses a REINFORCE‑type update: the log‑probability gradient of the selected action is multiplied by the total trajectory efficiency and used to adjust θ. Two extra input nodes provide the scaled temperature and volume, enriching the state representation. This approach successfully learns a Stirling‑like cycle but fails to reach the Carnot efficiency; convergence is slower and the final efficiency remains below the theoretical optimum. The authors attribute this to the sparsity of the global reward (η) and the difficulty of fine‑grained control in a high‑dimensional action space.
The paper quantitatively compares the learned efficiencies with analytical expressions for Carnot, Stirling, and Otto cycles, showing that the evolutionary method matches the Carnot value to four decimal places, while the policy‑gradient method attains only an approximate Stirling efficiency (≈ 0.28). The authors discuss why the evolutionary scheme is more robust for global, path‑dependent objectives, whereas gradient methods excel when smooth, local feedback is available.
Overall, the study establishes that RL techniques originally devised for games can be repurposed to solve physics problems where the objective is a path‑extensive quantity. It highlights the strengths of gradient‑free evolution for global optimization and points to future extensions involving multiple heat reservoirs, non‑equilibrium engines, and quantum thermodynamic devices, where human intuition may not readily identify optimal protocols.
Comments & Academic Discussion
Loading comments...
Leave a Comment