A Method for Hiding the Increased Non-Volatile Cache Read Latency
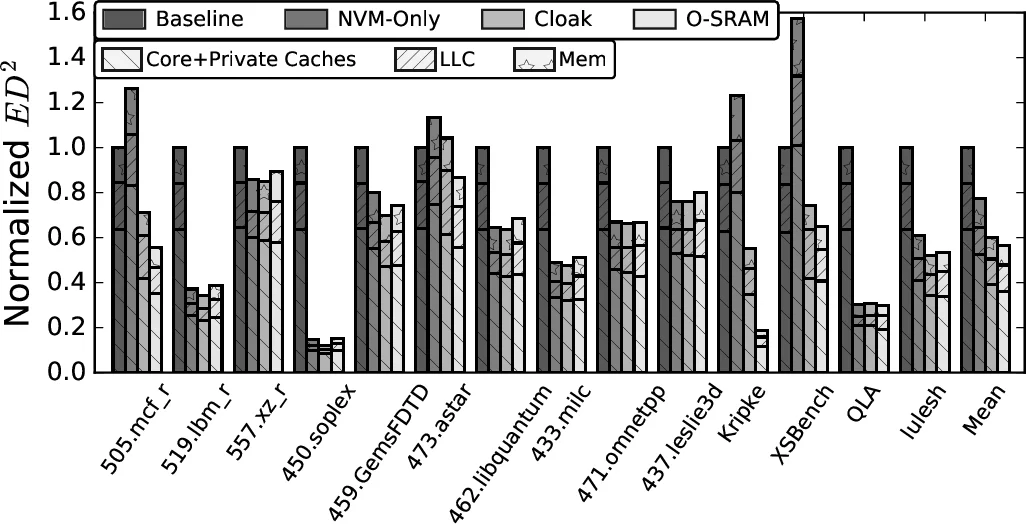
The increased memory demands of workloads is putting high pressure on Last Level Caches (LLCs). Unfortunately, there is limited opportunity to increase the capacity of LLCs due to the area and power requirements of the underlying SRAM technology. Interestingly, emerging Non-Volatile Memory (NVM) technologies promise a feasible alternative to SRAM for LLCs due to their higher area density. However, NVMs have substantially higher read and write latencies, which offset their area density benefit. Although researchers have proposed methods to tolerate NVM’s increased write latency, little emphasis has been placed on reducing the critical NVM read latency. To address this problem, this paper proposes Cloak. Cloak exploits data reuse in the LLC at the page level, to hide NVM read latency. Specifically, on certain L1 TLB misses to a page, Cloak transfers LLC-resident data belonging to the page from the LLC NVM array to a set of small SRAM Page Buffers that will service subsequent requests to this page. Further, to enable the high-bandwidth, low-latency transfer of lines of a page to the page buffers, Cloak uses an LLC layout that accelerates the discovery of LLC-resident cache lines from the page. We evaluate Cloak with full-system simulations of a 4-core processor across 14 workloads. We find that, on average, Cloak outperforms an SRAM LLC by 23.8% and an NVM-only LLC by 8.9% – in both cases, with negligible additional area. Further, Cloak’s ED^2 is 39.9% and 17.5% lower, respectively, than these designs.
💡 Research Summary
The paper addresses the growing pressure on Last‑Level Caches (LLCs) caused by data‑intensive workloads and the limited scalability of SRAM‑based caches due to their large area and leakage power. Emerging non‑volatile memories (NVMs), particularly STT‑RAM, offer 4× higher density and lower static power, but suffer from read latencies 10‑30× and write latencies 25‑100× higher than SRAM. While prior work has largely focused on mitigating the write latency of NVM caches, the authors observe that read latency remains a critical bottleneck, especially for high‑reliability STT‑RAM where the read latency can be as high as 3 ns compared with 300 ps for SRAM.
To hide this latency, the authors propose Cloak, a hardware mechanism that exploits page‑level temporal locality. The key observation is that when an L1 data TLB miss refills a page that has been accessed before, a large fraction of the page’s cache lines are already resident in the LLC. Empirical data from 14 benchmark applications show that 94.9 % of L3 hits originate from pages that were previously in the L1 TLB, and that many of those pages have multiple lines still cached in the LLC, especially as the LLC size grows.
Cloak adds a set of small SRAM Page Buffers (PBs) to the LLC. Each PB holds a subset of the NVM‑resident lines belonging to a single virtual page. When an L1 TLB miss occurs, the hardware checks the page‑table entry’s Accessed/Dirty bits (or L2 TLB presence) to determine whether the page has been referenced before. If so, the LLC controller locates all lines of that page in the NVM array and copies them into an available PB. To make this discovery fast, the authors redesign the LLC data layout so that all lines of a given page are placed in the same physical cache row, enabling a high‑bandwidth, low‑latency bulk transfer.
Subsequent memory accesses to the same page first probe the PBs. A PB hit satisfies the request entirely from SRAM, thereby bypassing the slow NVM read path. If the PB misses, the request proceeds to the NVM array as usual. The PB replacement policy is adaptive: it considers the reuse frequency of pages and the current occupancy of the buffers, aiming to keep high‑reuse pages resident while evicting low‑benefit entries.
The authors evaluate Cloak using full‑system simulations of a 4‑core processor with a 16 MB (4 MB per core) NVM LLC across 14 workloads (including mcf, lbm, soplex, GemsFDTD, etc.). Results show that Cloak achieves an average 23.8 % performance improvement over a pure SRAM LLC and 8.9 % over a pure NVM‑only LLC, despite the latter having larger capacity. Energy‑delay product (ED²) improves by 39.9 % relative to SRAM and 17.5 % relative to NVM‑only designs. The area overhead is negligible because the PBs occupy only a tiny fraction of the total cache area.
Compared with prior hybrid cache schemes that partition ways between SRAM and NVM or employ large monitoring structures, Cloak requires far less SRAM, avoids costly line migrations, and directly tackles the non‑pipelined nature of NVM reads. The design does rely on the presence of page‑level reuse; workloads with low spatial locality within pages may see reduced benefits. Additionally, the paper does not elaborate on coherence or consistency mechanisms for data that may be updated while residing in PBs, leaving that as future work.
In conclusion, Cloak demonstrates a practical, low‑area architectural technique to hide the high read latency of dense NVM LLCs by proactively moving likely‑to‑reuse page lines into fast SRAM buffers. The approach preserves the density advantage of NVM while delivering performance comparable to, or better than, traditional SRAM caches. Future extensions could explore dynamic sizing of PBs, integration with other NVM technologies (e.g., PCM), and more sophisticated coherence handling.
Comments & Academic Discussion
Loading comments...
Leave a Comment