Dijkstra-Through-Time: Ahead of time hardware scheduling method for deterministic workloads
Most of the previous works on data flow optimizations for Machine Learning hardware accelerators try to find algorithmic re-factorization such as loop-reordering and loop-tiling. However, the analysis and information they provide are still at very high level and one must further map them onto instructions that hardware can understand. This paper presents “Dijkstra-Through-Time” (DTT), an ahead of time compute and memory scheduling-mapping algorithm for deterministic workloads. It provides a simple implementation and supports accelerators with complex NoC configurations, at the expense of a long compilation process. This initial paper illustrates a proof of concept implementation to merge scheduling and data cache coherence mechanisms to get more optimized data flows.
💡 Research Summary
The paper addresses a gap in current data‑flow optimization techniques for machine‑learning accelerators: most existing methods operate at a high level (loop re‑ordering, tiling, etc.) and leave the detailed mapping of operations and data movements to a later stage, often requiring hand‑crafted or generic hardware instructions. To bridge this gap, the authors introduce “Dijkstra‑Through‑Time” (DTT), an ahead‑of‑time (compile‑time) scheduling and mapping algorithm specifically designed for deterministic workloads—i.e., workloads whose control flow does not depend on runtime data.
DTT consists of two distinct phases. The first, called the placing step, assigns each operation (typically a dot‑product or multiplication) to a concrete hardware actor (e.g., a MAC array). Because the routing step is computationally expensive, the placing step uses a lightweight heuristic. The authors implement a simple “First‑Best‑Fit” heuristic that selects the actor with the highest affinity, where affinity can be defined as the amount of required input data already cached in that actor. The output of this phase is a list of instructions indicating which datum should be sent, to which actor, and at what cycle it must arrive.
The second phase, the routing step, determines the exact data‑movement schedule that satisfies the placement constraints while respecting bandwidth, latency, and contention on the interconnect. The authors model the hardware as a set of Node objects (memory elements, registers, processing elements) and Wire objects (physical or virtual connections). Each node maintains a per‑cycle history of which datum it holds. The routing problem is then expressed as a shortest‑path problem on a time‑expanded graph where each vertex is a (Node, cycle) pair. Dijkstra’s algorithm is applied to this graph to find the minimum‑cost path for each datum from its source to its destination at the required cycle. The cost function incorporates bus width, latency, and current usage, effectively preventing oversubscription of a bus in any cycle.
A concrete example is presented using a tiny hardware model: a 4 KB SRAM, a 2‑input register, a 8‑bit multiplier, and two 8‑bit buses with different widths and latencies. The authors walk through the placement of a simple multiplication, then show how Dijkstra’s algorithm routes operand A and operand B through the graph, respecting the fact that bus 1 can only carry one 8‑bit word per cycle. The resulting schedule demonstrates that operand B must wait one cycle in the register while A uses the bus, illustrating how DTT automatically handles resource contention.
The paper then scales the method to a more realistic accelerator consisting of a DRAM, multiple SRAM banks, four PEs, and an output SRAM. Detailed tables describe hardware costs, actor parameters (cool‑down cycles, multiplication latency, etc.), and a sample workload consisting of several dot‑products with data dependencies. The placing step distributes the dot‑products across the four PEs using the First‑Best‑Fit heuristic. The routing step then produces a full timeline (Table IV) showing when each datum moves from DRAM to SRAM, from SRAM to registers, and finally to the PEs. Two notable observations emerge: (1) DTT re‑uses data already present in a PE’s local buffer for subsequent operations, avoiding unnecessary DRAM accesses; (2) when the final dot‑product uses intermediate results (operands 100‑103), DTT treats them exactly like any other datum, enabling cross‑layer data reuse without explicit programmer intervention.
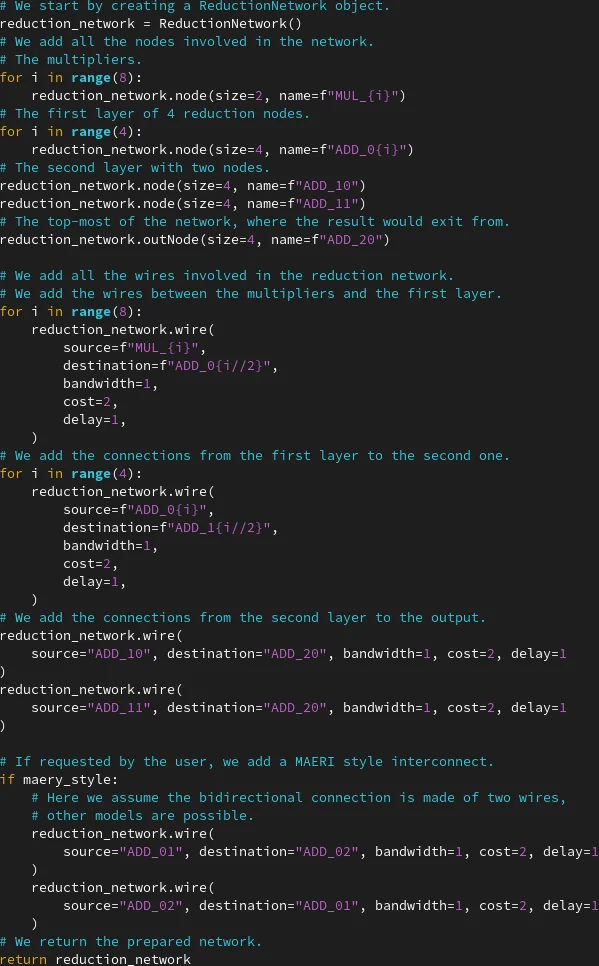
Beyond simple feed‑forward data flows, the authors discuss how DTT can be applied to reduction networks (binary trees of adders). By “pretending” to distribute the reduction results to the multipliers and then running the routing algorithm backwards, DTT can evaluate different reduction topologies, such as an “augmented reduction tree” with an extra connection between two internal adders. By simply removing or adding this wire in the hardware description, designers can quantify energy savings and runtime differences, showcasing DTT as a rapid prototyping backend for architectural exploration.
The authors acknowledge several limitations. DTT requires the workload to be fully deterministic; any data‑dependent branching or dynamic shape changes would break the model. The time‑expanded graph grows linearly with the number of cycles and quadratically with the number of nodes, leading to long compilation times for large accelerators or deep networks. The current implementation is a Python prototype; integrating it into a production compiler flow would demand more efficient data structures, parallel graph processing, and possibly heuristic pruning.
In conclusion, DTT offers a novel perspective by treating the scheduling problem as a shortest‑path search in a time‑expanded hardware graph. It bridges the gap between high‑level algorithmic transformations and low‑level instruction scheduling, automatically handling bus contention, data reuse, and cache‑coherence‑free operation for deterministic ML workloads. Future work suggested includes extending the method to handle limited nondeterminism, scaling the algorithm to thousands of processing elements, and validating the approach on real silicon or FPGA prototypes.
Comments & Academic Discussion
Loading comments...
Leave a Comment