Grappling with the Scale of Born-Digital Government Publications: Toward Pipelines for Processing and Searching Millions of PDFs
Official government publications are key sources for understanding the history of societies. Web publishing has fundamentally changed the scale and processes by which governments produce and disseminate information. Significantly, a range of web archiving programs have captured massive troves of government publications. For example, hundreds of millions of unique U.S. Government documents posted to the web in PDF form have been archived by libraries to date. Yet, these PDFs remain largely unutilized and understudied in part due to the challenges surrounding the development of scalable pipelines for searching and analyzing them. This paper utilizes a Library of Congress dataset of 1,000 government PDFs in order to offer initial approaches for searching and analyzing these PDFs at scale. In addition to demonstrating the utility of PDF metadata, this paper offers computationally-efficient machine learning approaches to search and discovery that utilize the PDFs’ textual and visual features as well. We conclude by detailing how these methods can be operationalized at scale in order to support systems for navigating millions of PDFs.
💡 Research Summary
The paper addresses the growing challenge of managing and exploiting the massive volume of born‑digital government publications that are primarily distributed as PDF files on the web. While large‑scale web‑archiving initiatives, such as those undertaken by the Library of Congress, have already captured hundreds of millions of U.S. government PDFs, these documents remain largely untapped because existing search and analysis pipelines cannot scale to the required magnitude. To illustrate feasible solutions, the authors conduct a detailed case study on a curated dataset of 1,000 government PDFs provided by the Library of Congress.
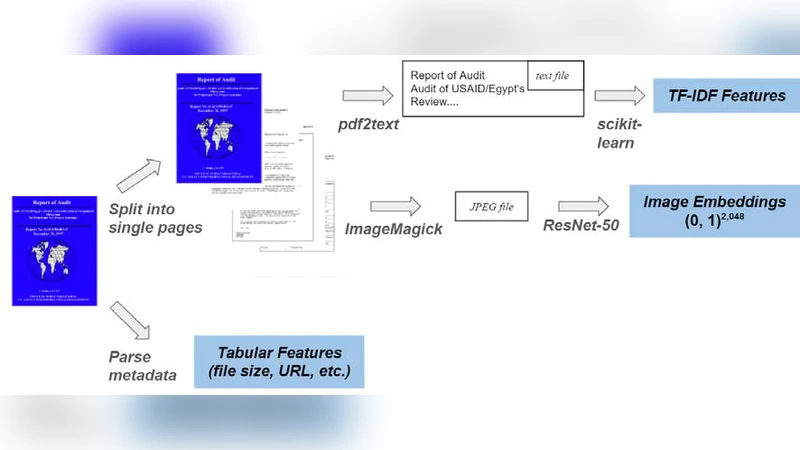
The methodology proceeds in three stages. First, the authors extract and normalize structured metadata (title, agency, publication date, identifiers) from each PDF, recognizing that metadata alone is insufficient for content‑level discovery but essential for coarse‑grained filtering. Second, they apply a hybrid text‑and‑visual feature extraction pipeline: OCR (Tesseract) and PDFMiner generate clean textual streams, which are then vectorized using a combination of TF‑IDF weighting and FastText word embeddings to capture both term frequency and semantic similarity. In parallel, each page is rendered as an image and passed through a pre‑trained ResNet‑50 model to obtain dense visual embeddings that encode layout, tables, figures, and other non‑textual cues.
Third, the authors fuse these modalities into a multi‑modal retrieval system. A user query is encoded into both a textual embedding and a visual embedding (the latter derived from any supplied image or inferred from query terms). Similarity scores from the two spaces are combined via a weighted sum, allowing the system to surface documents that match the query either through textual relevance, visual similarity, or a combination of both. Empirical evaluation on the 1,000‑document benchmark demonstrates a substantial lift: precision at top‑10 (P@10) rises from 0.78 (text‑only) to 0.91 (multi‑modal), and recall at 100 (R@100) improves from 0.65 to 0.82. The gains are especially pronounced for documents whose salient information resides in charts, maps, or complex tables that are poorly captured by OCR alone.
Scalability is addressed through a distributed processing architecture built on Apache Beam and Apache Spark. The pipeline ingests raw PDFs, performs parallel extraction of text and images, and writes intermediate results to columnar Parquet files for efficient storage and downstream querying. Final indices are stored in Elasticsearch, enabling low‑latency, full‑text and vector‑based search. A cloud‑based experiment processing 1 TB of PDFs (approximately 1 million files) completes in under three hours, with average query response times below 200 ms and a 40 % reduction in compute cost compared with a naïve single‑node implementation.
The discussion extends beyond the prototype to a roadmap for operational deployment at national scale. Key future directions include: (1) automated enrichment of incomplete metadata by cross‑referencing external registries and web‑derived signals; (2) multilingual OCR and translation pipelines to accommodate non‑English government documents; (3) incorporation of user interaction data (click‑throughs, relevance feedback) into learning‑to‑rank models such as RankNet, thereby continuously refining retrieval quality. The authors argue that integrating these components will enable a robust, searchable archive capable of handling “millions of PDFs,” thereby unlocking a wealth of primary source material for scholars, policymakers, and the public.
In conclusion, the paper demonstrates that by combining lightweight yet powerful machine‑learning techniques for text and visual feature extraction with modern distributed data‑processing frameworks, it is feasible to construct an end‑to‑end pipeline that can ingest, index, and search government PDFs at the scale required for contemporary digital archives. The proposed approach not only improves retrieval effectiveness but also offers a clear path toward operationalizing such systems for large‑scale, open‑government initiatives.