A RISC-V Simulator and Benchmark Suite for Designing and Evaluating Vector Architectures
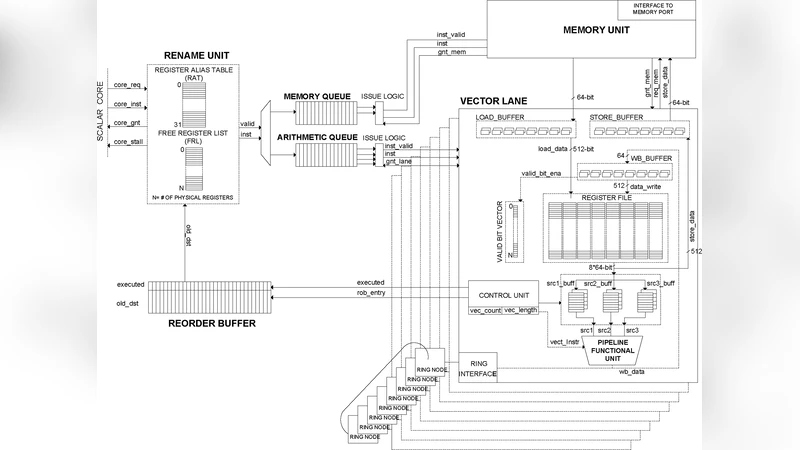
Vector architectures lack tools for research. Consider the gem5 simulator, which is possibly the leading platform for computer-system architecture research. Unfortunately, gem5 does not have an available distribution that includes a flexible and customizable vector architecture model. In consequence, researchers have to develop their own simulation platform to test their ideas, which consume much research time. However, once the base simulator platform is developed, another question is the following: Which applications should be tested to perform the experiments? The lack of Vectorized Benchmark Suites is another limitation. To face these problems, this work presents a set of tools for designing and evaluating vector architectures. First, the gem5 simulator was extended to support the execution of RISC-V Vector instructions by adding a parameterizable Vector Architecture model for designers to evaluate different approaches according to the target they pursue. Second, a novel Vectorized Benchmark Suite is presented: a collection composed of seven data-parallel applications from different domains that can be classified according to the modules that are stressed in the vector architecture. Finally, a study of the Vectorized Benchmark Suite executing on the gem5-based Vector Architecture model is highlighted. This suite is the first in its category that covers the different possible usage scenarios that may occur within different vector architecture designs such as embedded systems, mainly focused on short vectors, or High-Performance-Computing (HPC), usually designed for large vectors.
💡 Research Summary
Vector architectures promise substantial gains in data‑parallel workloads, yet the research community lacks a unified, flexible simulation platform and a representative benchmark suite to evaluate new ideas. This paper addresses both gaps by extending the widely used gem5 simulator with a parameterizable RISC‑V Vector Extension (RVV) model and by introducing a curated set of seven vectorized applications covering a broad spectrum of usage scenarios.
The authors first integrate RVV support into gem5 at both the ISA decoding and micro‑architectural levels. The new model allows users to configure key architectural parameters such as the number of vector registers, the maximum vector length (VLmax), pipeline depth, and cache‑pre‑fetch policies. Vector instructions are decoded, and the pipeline dynamically adapts its execution stages based on the current VL, handling mask registers, stride calculations, and memory accesses in a way that mirrors real hardware. By exposing these knobs, the simulator can emulate designs ranging from low‑power embedded processors that operate on short vectors to high‑performance computing (HPC) engines that process thousands of elements per instruction. The memory subsystem is also enhanced to model both contiguous and strided accesses, enabling accurate bandwidth and latency analysis for vector loads and stores.
The benchmark suite, called the Vectorized Benchmark Suite (VBS), comprises seven data‑parallel programs selected from distinct domains: image convolution, Fast Fourier Transform (FFT), General Matrix‑Matrix Multiply (GEMM), vector sort, particle‑based physics simulation, multilayer perceptron inference, and data compression. Each application stresses a different aspect of a vector processor: computational intensity, memory bandwidth, control‑flow masking, or irregular access patterns. The suite is organized into three modules—Vector Compute, Vector Memory, and Vector Control/Mask—so that researchers can pinpoint which architectural features dominate performance for a given workload. Automated scripts run each benchmark across a range of VL settings, collecting cycle counts, cache statistics, memory traffic, and estimated power consumption.
Experimental results demonstrate clear trade‑offs. Short vectors (e.g., VL = 32) suffer from pipeline start‑up overhead, leading to lower utilization, whereas long vectors (e.g., VL = 1024) expose memory‑bandwidth bottlenecks, making cache pre‑fetch strategies critical. Applications that heavily use mask registers experience pipeline stalls when control divergence is high, highlighting the importance of efficient mask handling logic. By varying VLmax, register‑file size, and memory hierarchy parameters, the authors show how performance scales and where diminishing returns appear. These findings provide concrete guidance for architects aiming to tailor a vector engine to a specific target domain.
The paper also outlines future work. A full vector‑pipeline (e.g., VLIW‑style) implementation could be compared against the current scalar‑core‑with‑vector‑extensions approach to assess latency versus throughput benefits. More accurate power modeling integrated into gem5 would enable comprehensive PPA (performance‑power‑area) trade‑off studies. Finally, expanding the benchmark suite with real‑world industrial workloads such as video codecs or large‑scale scientific simulations would increase the relevance of the evaluation framework.
In summary, this work delivers a ready‑to‑use, highly configurable RISC‑V vector simulation environment together with a diverse, well‑characterized benchmark suite. By lowering the barrier to entry for vector‑architecture research, it accelerates the design‑space exploration process, allowing researchers and engineers to validate concepts, compare alternatives, and make informed decisions about vector length, register file organization, and memory subsystem design. The contributions are poised to become foundational tools for both academic investigations and industry‑driven development of next‑generation vector processors.