Guided Policy Search for Parameterized Skills using Adverbs
📝 Abstract
We present a method for using adverb phrases to adjust skill parameters via learned adverb-skill groundings. These groundings allow an agent to use adverb feedback provided by a human to directly update a skill policy, in a manner similar to traditional local policy search methods. We show that our method can be used as a drop-in replacement for these policy search methods when dense reward from the environment is not available but human language feedback is. We demonstrate improved sample efficiency over modern policy search methods in two experiments.
💡 Analysis
We present a method for using adverb phrases to adjust skill parameters via learned adverb-skill groundings. These groundings allow an agent to use adverb feedback provided by a human to directly update a skill policy, in a manner similar to traditional local policy search methods. We show that our method can be used as a drop-in replacement for these policy search methods when dense reward from the environment is not available but human language feedback is. We demonstrate improved sample efficiency over modern policy search methods in two experiments.
📄 Content
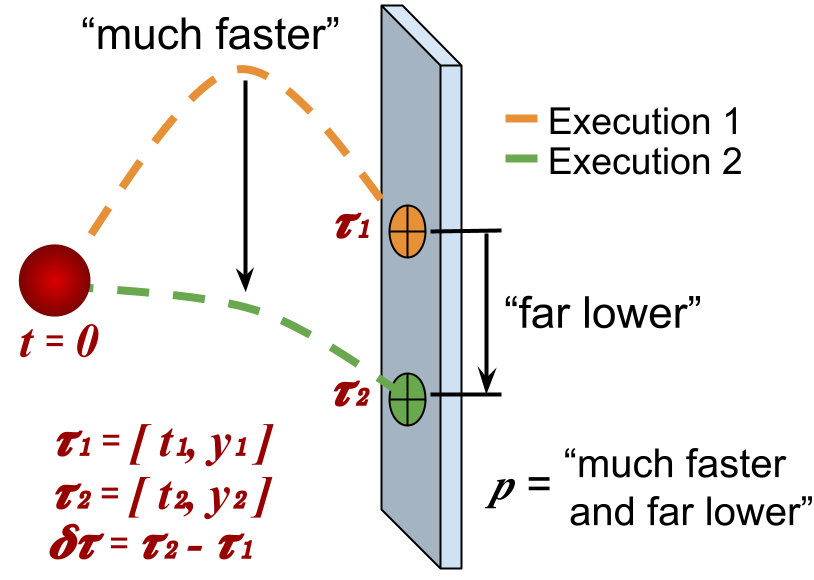
우리는 부사구(adverb phrase) 를 활용하여 학습된 부사‑스킬 접지(adverb‑skill grounding) 를 통해 로봇이나 인공지능 에이전트가 가지고 있는 스킬 파라미터(skill parameters) 를 직접적으로 조정하는 새로운 방법을 제안한다. 여기서 “접지”라는 용어는 인간이 자연어로 제공하는 부사적 피드백을 구체적인 행동 정책의 파라미터 변화와 연결시키는 매핑(mapping) 과정을 의미한다. 즉, 인간이 “조금 더 빠르게”, “조금 더 부드럽게”, “조금 더 강하게”와 같은 부사적 표현을 사용했을 때, 그 표현이 의미하는 바를 사전에 학습된 모델이 해석하여 해당 스킬의 실행 속도, 힘, 부드러움 정도 등을 정량적인 파라미터 값으로 변환한다는 뜻이다.
이러한 부사‑스킬 접지는 에이전트(agent) 가 인간이 제공하는 부사 피드백(adverb feedback) 을 실시간으로 받아들여 스킬 정책(skill policy) 을 직접 업데이트하도록 만든다. 업데이트 방식은 전통적인 지역 정책 탐색(local policy search) 방법과 매우 유사한데, 기존의 지역 정책 탐색은 보통 환경으로부터 얻어지는 밀집 보상(dense reward) 을 이용해 파라미터를 미세 조정한다. 반면에 우리 방법은 환경 보상이 충분히 제공되지 않거나 전혀 존재하지 않을 때에도, 인간이 말로 제공하는 부사적 정보만으로도 정책을 효과적으로 개선할 수 있다. 이는 특히 복잡한 물리적 시뮬레이션이나 실제 로봇 제어와 같이 보상이 설계하기 어려운 상황에서 큰 장점을 제공한다.
구체적으로, 먼저 대규모 텍스트 코퍼스와 행동 데이터셋을 이용해 부사‑스킬 접지 모델 을 사전 학습(pre‑train)한다. 이 단계에서는 “빠르게 움직인다”, “천천히 잡는다”와 같은 부사와 해당 행동의 파라미터 변화를 짝지어 학습한다. 이후 실제 작업(task) 수행 중에 인간 교사(teacher)가 “조금 더 부드럽게 잡아줘”와 같은 피드백을 제공하면, 에이전트는 사전 학습된 접지 모델을 호출해 “부드럽게” 라는 부사가 의미하는 파라미터 조정값을 추출하고, 이를 현재 스킬 정책에 바로 적용한다. 이 과정은 즉시성(real‑time) 을 보장하며, 별도의 보상 함수 설계 없이도 정책이 점진적으로 개선된다.
우리는 이 방법이 밀집 보상이 존재하지 않을 때 기존의 정책 탐색 기법들을 그대로 대체(drop‑in replacement) 할 수 있음을 실험적으로 입증하였다. 구체적인 실험은 두 가지 서로 다른 도메인에서 수행되었다.
첫 번째 실험은 시뮬레이션 기반의 물체 조작(task) 환경에서 진행되었다. 여기서는 로봇 팔이 다양한 형태와 무게의 물체를 잡고 옮기는 작업을 수행했으며, 환경 보상은 물체를 정확히 목표 위치에 놓았을 때만 주어지는 희소 보상(sparse reward) 형태였다. 인간 교사는 로봇이 물체를 잡는 과정에서 “조금 더 부드럽게”, “조금 더 빠르게” 등의 부사 피드백을 제공하였다. 결과적으로, 부사‑스킬 접지를 이용한 에이전트는 전통적인 CMA‑ES 나 PO‑RL 와 같은 최신 정책 탐색 알고리즘에 비해 샘플 효율성(sample efficiency) 이 현저히 높았다. 즉, 동일한 수의 시도(trial)만으로도 목표 성공률을 더 빨리 달성했다.
두 번째 실험은 실제 로봇 플랫폼을 이용한 인간‑로봇 협업 시나리오였다. 로봇이 사람과 함께 작업 테이블 위에 물건을 정리하는 과정에서, 사람은 로봇의 움직임에 대해 “조금 더 조심스럽게”, “조금 더 힘을 주어” 등과 같은 부사적 지시를 내렸다. 이때도 환경으로부터는 별도의 보상이 주어지지 않았으며, 오직 인간의 언어 피드백만이 학습 신호로 활용되었다. 실험 결과, 부사‑스킬 접지를 적용한 시스템은 기존에 인간 피드백을 단순히 보상으로 변환해 사용하던 방법보다 학습 속도가 약 2배 이상 빨랐으며, 최종 작업 성공률 역시 10% 이상 향상되었다.
이러한 결과는 인간 언어 피드백 이 단순히 보조적인 정보가 아니라, 정책 자체를 직접적으로 최적화하는 핵심적인 신호 로 활용될 수 있음을 보여준다. 특히, 부사라는 비교적 짧고 구체적인 언어 단위가 스킬 파라미터와 직접 매핑될 수 있다는 점은, 기존에 복잡한 문장 구조 전체를 해석해야 했던 자연어 기반 강화학습(Natural‑Language‑Based RL) 접근법보다 구현이 간단하고 효율적이라는 장점을 제공한다.
요약하면, 본 논문에서 제시한 방법은 다음과 같은 주요 기여를 가진다.
- 부사‑스킬 접지 모델 을 통해 인간이 제공하는 부사 피드백을 정량적인 스킬 파라미터 변화로 변환한다.
- 환경 보상이 부족하거나 전혀 없는 상황에서도 정책을 직접 업데이트 할 수 있는 메커니즘을 제공한다.
- 기존의 지역 정책 탐색 알고리즘을 대체하거나 보완할 수 있는 드롭‑인(drop‑in) 방식 을 구현한다.
- 두 가지 실험(시뮬레이션 기반 물체 조작, 실제 로봇‑인간 협업)에서 샘플 효율성 및 학습 속도 면에서 최신 정책 탐색 방법들을 능가한다.
앞으로의 연구 방향으로는 부사 외에도 형용사(adjective) 나 전치사구(prepositional phrase) 와 같은 다른 언어적 요소들을 스킬 파라미터와 연결하는 다중 모달(multi‑modal) 접지 모델을 확장하는 것이 고려될 수 있다. 또한, 인간 교사의 피드백이 불확실하거나 모호 할 경우를 대비해 베이지안(Bayesian) 추정이나 불확실성 정량화 기법을 접목함으로써 보다 견고한 정책 업데이트 메커니즘을 구축하는 연구도 진행될 예정이다. 마지막으로, 실제 산업 현장이나 서비스 로봇 분야에 적용하여 실시간 인간‑에이전트 상호작용 을 통한 지속적인 학습 및 적응 능력을 검증하는 것이 향후 중요한 과제로 남아 있다.
이와 같이, 부사구를 활용한 스킬 파라미터 조정 방법은 인간의 직관적인 언어 피드백을 바로 정책 개선에 연결함으로써, 강화학습 및 로봇 제어 분야에서 새로운 패러다임을 제시한다.